退购1.1定位算法
This commit is contained in:
1
docs/CNAME
Normal file
1
docs/CNAME
Normal file
@ -0,0 +1 @@
|
||||
docs.ultralytics.com
|
||||
89
docs/README.md
Normal file
89
docs/README.md
Normal file
@ -0,0 +1,89 @@
|
||||
---
|
||||
description: Learn how to install the Ultralytics package in developer mode and build/serve locally using MkDocs. Deploy your project to your host easily.
|
||||
---
|
||||
|
||||
# Ultralytics Docs
|
||||
|
||||
Ultralytics Docs are deployed to [https://docs.ultralytics.com](https://docs.ultralytics.com).
|
||||
|
||||
### Install Ultralytics package
|
||||
|
||||
To install the ultralytics package in developer mode, you will need to have Git and Python 3 installed on your system.
|
||||
Then, follow these steps:
|
||||
|
||||
1. Clone the ultralytics repository to your local machine using Git:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/ultralytics/ultralytics.git
|
||||
```
|
||||
|
||||
2. Navigate to the root directory of the repository:
|
||||
|
||||
```bash
|
||||
cd ultralytics
|
||||
```
|
||||
|
||||
3. Install the package in developer mode using pip:
|
||||
|
||||
```bash
|
||||
pip install -e '.[dev]'
|
||||
```
|
||||
|
||||
This will install the ultralytics package and its dependencies in developer mode, allowing you to make changes to the
|
||||
package code and have them reflected immediately in your Python environment.
|
||||
|
||||
Note that you may need to use the pip3 command instead of pip if you have multiple versions of Python installed on your
|
||||
system.
|
||||
|
||||
### Building and Serving Locally
|
||||
|
||||
The `mkdocs serve` command is used to build and serve a local version of the MkDocs documentation site. It is typically
|
||||
used during the development and testing phase of a documentation project.
|
||||
|
||||
```bash
|
||||
mkdocs serve
|
||||
```
|
||||
|
||||
Here is a breakdown of what this command does:
|
||||
|
||||
- `mkdocs`: This is the command-line interface (CLI) for the MkDocs static site generator. It is used to build and serve
|
||||
MkDocs sites.
|
||||
- `serve`: This is a subcommand of the `mkdocs` CLI that tells it to build and serve the documentation site locally.
|
||||
- `-a`: This flag specifies the hostname and port number to bind the server to. The default value is `localhost:8000`.
|
||||
- `-t`: This flag specifies the theme to use for the documentation site. The default value is `mkdocs`.
|
||||
- `-s`: This flag tells the `serve` command to serve the site in silent mode, which means it will not display any log
|
||||
messages or progress updates.
|
||||
When you run the `mkdocs serve` command, it will build the documentation site using the files in the `docs/` directory
|
||||
and serve it at the specified hostname and port number. You can then view the site by going to the URL in your web
|
||||
browser.
|
||||
|
||||
While the site is being served, you can make changes to the documentation files and see them reflected in the live site
|
||||
immediately. This is useful for testing and debugging your documentation before deploying it to a live server.
|
||||
|
||||
To stop the serve command and terminate the local server, you can use the `CTRL+C` keyboard shortcut.
|
||||
|
||||
### Deploying Your Documentation Site
|
||||
|
||||
To deploy your MkDocs documentation site, you will need to choose a hosting provider and a deployment method. Some
|
||||
popular options include GitHub Pages, GitLab Pages, and Amazon S3.
|
||||
|
||||
Before you can deploy your site, you will need to configure your `mkdocs.yml` file to specify the remote host and any
|
||||
other necessary deployment settings.
|
||||
|
||||
Once you have configured your `mkdocs.yml` file, you can use the `mkdocs deploy` command to build and deploy your site.
|
||||
This command will build the documentation site using the files in the `docs/` directory and the specified configuration
|
||||
file and theme, and then deploy the site to the specified remote host.
|
||||
|
||||
For example, to deploy your site to GitHub Pages using the gh-deploy plugin, you can use the following command:
|
||||
|
||||
```bash
|
||||
mkdocs gh-deploy
|
||||
```
|
||||
|
||||
If you are using GitHub Pages, you can set a custom domain for your documentation site by going to the "Settings" page
|
||||
for your repository and updating the "Custom domain" field in the "GitHub Pages" section.
|
||||
|
||||
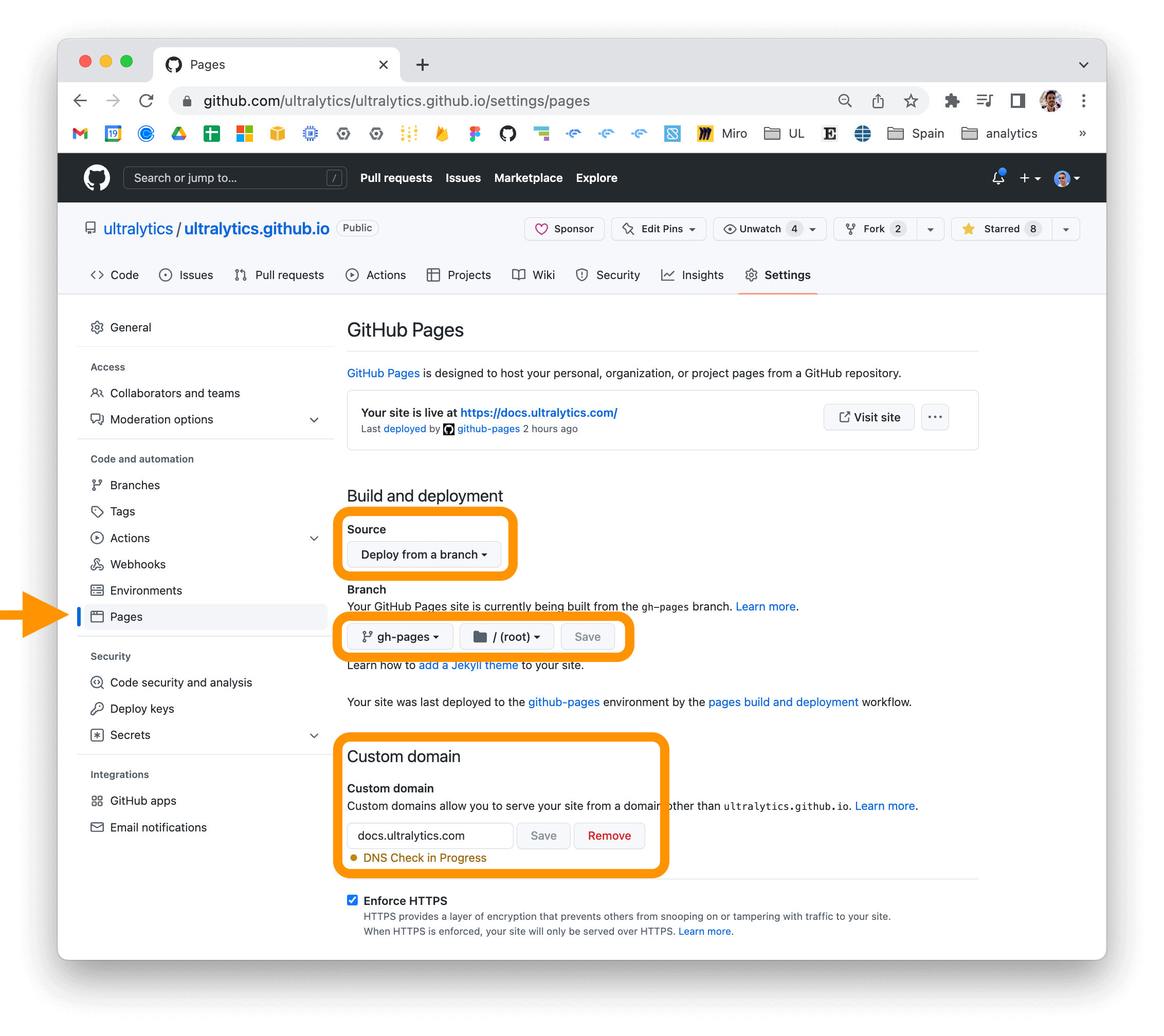
|
||||
|
||||
For more information on deploying your MkDocs documentation site, see
|
||||
the [MkDocs documentation](https://www.mkdocs.org/user-guide/deploying-your-docs/).
|
||||
32
docs/SECURITY.md
Normal file
32
docs/SECURITY.md
Normal file
@ -0,0 +1,32 @@
|
||||
---
|
||||
description: Learn how Ultralytics prioritize security. Get insights into Snyk and GitHub CodeQL scans, and how to report security issues in YOLOv8.
|
||||
---
|
||||
|
||||
# Security Policy
|
||||
|
||||
At [Ultralytics](https://ultralytics.com), the security of our users' data and systems is of utmost importance. To
|
||||
ensure the safety and security of our [open-source projects](https://github.com/ultralytics), we have implemented
|
||||
several measures to detect and prevent security vulnerabilities.
|
||||
|
||||
[](https://snyk.io/advisor/python/ultralytics)
|
||||
|
||||
## Snyk Scanning
|
||||
|
||||
We use [Snyk](https://snyk.io/advisor/python/ultralytics) to regularly scan the YOLOv8 repository for vulnerabilities
|
||||
and security issues. Our goal is to identify and remediate any potential threats as soon as possible, to minimize any
|
||||
risks to our users.
|
||||
|
||||
## GitHub CodeQL Scanning
|
||||
|
||||
In addition to our Snyk scans, we also use
|
||||
GitHub's [CodeQL](https://docs.github.com/en/code-security/code-scanning/automatically-scanning-your-code-for-vulnerabilities-and-errors/about-code-scanning-with-codeql)
|
||||
scans to proactively identify and address security vulnerabilities.
|
||||
|
||||
## Reporting Security Issues
|
||||
|
||||
If you suspect or discover a security vulnerability in the YOLOv8 repository, please let us know immediately. You can
|
||||
reach out to us directly via our [contact form](https://ultralytics.com/contact) or
|
||||
via [security@ultralytics.com](mailto:security@ultralytics.com). Our security team will investigate and respond as soon
|
||||
as possible.
|
||||
|
||||
We appreciate your help in keeping the YOLOv8 repository secure and safe for everyone.
|
||||
BIN
docs/assets/favicon.ico
Normal file
BIN
docs/assets/favicon.ico
Normal file
Binary file not shown.
|
After Width: | Height: | Size: 9.4 KiB |
107
docs/build_reference.py
Normal file
107
docs/build_reference.py
Normal file
@ -0,0 +1,107 @@
|
||||
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||
"""
|
||||
Helper file to build Ultralytics Docs reference section. Recursively walks through ultralytics dir and builds an MkDocs
|
||||
reference section of *.md files composed of classes and functions, and also creates a nav menu for use in mkdocs.yaml.
|
||||
|
||||
Note: Must be run from repository root directory. Do not run from docs directory.
|
||||
"""
|
||||
|
||||
import os
|
||||
import re
|
||||
from collections import defaultdict
|
||||
from pathlib import Path
|
||||
from ultralytics.yolo.utils import ROOT
|
||||
|
||||
NEW_YAML_DIR = ROOT.parent
|
||||
CODE_DIR = ROOT
|
||||
REFERENCE_DIR = ROOT.parent / 'docs/reference'
|
||||
|
||||
|
||||
def extract_classes_and_functions(filepath):
|
||||
with open(filepath, 'r') as file:
|
||||
content = file.read()
|
||||
|
||||
class_pattern = r"(?:^|\n)class\s(\w+)(?:\(|:)"
|
||||
func_pattern = r"(?:^|\n)def\s(\w+)\("
|
||||
|
||||
classes = re.findall(class_pattern, content)
|
||||
functions = re.findall(func_pattern, content)
|
||||
|
||||
return classes, functions
|
||||
|
||||
|
||||
def create_markdown(py_filepath, module_path, classes, functions):
|
||||
md_filepath = py_filepath.with_suffix('.md')
|
||||
|
||||
md_content = [f"# {class_name}\n---\n:::{module_path}.{class_name}\n<br><br>\n" for class_name in classes]
|
||||
md_content.extend(f"# {func_name}\n---\n:::{module_path}.{func_name}\n<br><br>\n" for func_name in functions)
|
||||
md_content = "\n".join(md_content)
|
||||
|
||||
os.makedirs(os.path.dirname(md_filepath), exist_ok=True)
|
||||
with open(md_filepath, 'w') as file:
|
||||
file.write(md_content)
|
||||
|
||||
return md_filepath.relative_to(NEW_YAML_DIR)
|
||||
|
||||
|
||||
def nested_dict():
|
||||
return defaultdict(nested_dict)
|
||||
|
||||
|
||||
def sort_nested_dict(d):
|
||||
return {
|
||||
key: sort_nested_dict(value) if isinstance(value, dict) else value
|
||||
for key, value in sorted(d.items())
|
||||
}
|
||||
|
||||
|
||||
def create_nav_menu_yaml(nav_items):
|
||||
nav_tree = nested_dict()
|
||||
|
||||
for item_str in nav_items:
|
||||
item = Path(item_str)
|
||||
parts = item.parts
|
||||
current_level = nav_tree['reference']
|
||||
for part in parts[2:-1]: # skip the first two parts (docs and reference) and the last part (filename)
|
||||
current_level = current_level[part]
|
||||
|
||||
md_file_name = parts[-1].replace('.md', '')
|
||||
current_level[md_file_name] = item
|
||||
|
||||
nav_tree_sorted = sort_nested_dict(nav_tree)
|
||||
|
||||
def _dict_to_yaml(d, level=0):
|
||||
yaml_str = ""
|
||||
indent = " " * level
|
||||
for k, v in d.items():
|
||||
if isinstance(v, dict):
|
||||
yaml_str += f"{indent}- {k}:\n{_dict_to_yaml(v, level + 1)}"
|
||||
else:
|
||||
yaml_str += f"{indent}- {k}: {str(v).replace('docs/', '')}\n"
|
||||
return yaml_str
|
||||
|
||||
with open(NEW_YAML_DIR / 'nav_menu_updated.yml', 'w') as file:
|
||||
yaml_str = _dict_to_yaml(nav_tree_sorted)
|
||||
file.write(yaml_str)
|
||||
|
||||
|
||||
def main():
|
||||
nav_items = []
|
||||
for root, _, files in os.walk(CODE_DIR):
|
||||
for file in files:
|
||||
if file.endswith(".py") and file != "__init__.py":
|
||||
py_filepath = Path(root) / file
|
||||
classes, functions = extract_classes_and_functions(py_filepath)
|
||||
|
||||
if classes or functions:
|
||||
py_filepath_rel = py_filepath.relative_to(CODE_DIR)
|
||||
md_filepath = REFERENCE_DIR / py_filepath_rel
|
||||
module_path = f"ultralytics.{py_filepath_rel.with_suffix('').as_posix().replace('/', '.')}"
|
||||
md_rel_filepath = create_markdown(md_filepath, module_path, classes, functions)
|
||||
nav_items.append(str(md_rel_filepath))
|
||||
|
||||
create_nav_menu_yaml(nav_items)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
7
docs/datasets/classify/caltech101.md
Normal file
7
docs/datasets/classify/caltech101.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
7
docs/datasets/classify/caltech256.md
Normal file
7
docs/datasets/classify/caltech256.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
7
docs/datasets/classify/cifar10.md
Normal file
7
docs/datasets/classify/cifar10.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
7
docs/datasets/classify/cifar100.md
Normal file
7
docs/datasets/classify/cifar100.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
7
docs/datasets/classify/fashion-mnist.md
Normal file
7
docs/datasets/classify/fashion-mnist.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
7
docs/datasets/classify/imagenet.md
Normal file
7
docs/datasets/classify/imagenet.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
7
docs/datasets/classify/imagenet10.md
Normal file
7
docs/datasets/classify/imagenet10.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
7
docs/datasets/classify/imagenette.md
Normal file
7
docs/datasets/classify/imagenette.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
7
docs/datasets/classify/imagewoof.md
Normal file
7
docs/datasets/classify/imagewoof.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
104
docs/datasets/classify/index.md
Normal file
104
docs/datasets/classify/index.md
Normal file
@ -0,0 +1,104 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how torchvision organizes classification image datasets. Use this code to create and train models. CLI and Python code shown.
|
||||
---
|
||||
|
||||
# Image Classification Datasets Overview
|
||||
|
||||
## Dataset format
|
||||
|
||||
The folder structure for classification datasets in torchvision typically follows a standard format:
|
||||
|
||||
```
|
||||
root/
|
||||
|-- class1/
|
||||
| |-- img1.jpg
|
||||
| |-- img2.jpg
|
||||
| |-- ...
|
||||
|
|
||||
|-- class2/
|
||||
| |-- img1.jpg
|
||||
| |-- img2.jpg
|
||||
| |-- ...
|
||||
|
|
||||
|-- class3/
|
||||
| |-- img1.jpg
|
||||
| |-- img2.jpg
|
||||
| |-- ...
|
||||
|
|
||||
|-- ...
|
||||
```
|
||||
|
||||
In this folder structure, the `root` directory contains one subdirectory for each class in the dataset. Each subdirectory is named after the corresponding class and contains all the images for that class. Each image file is named uniquely and is typically in a common image file format such as JPEG or PNG.
|
||||
|
||||
** Example **
|
||||
|
||||
For example, in the CIFAR10 dataset, the folder structure would look like this:
|
||||
|
||||
```
|
||||
cifar-10-/
|
||||
|
|
||||
|-- train/
|
||||
| |-- airplane/
|
||||
| | |-- 10008_airplane.png
|
||||
| | |-- 10009_airplane.png
|
||||
| | |-- ...
|
||||
| |
|
||||
| |-- automobile/
|
||||
| | |-- 1000_automobile.png
|
||||
| | |-- 1001_automobile.png
|
||||
| | |-- ...
|
||||
| |
|
||||
| |-- bird/
|
||||
| | |-- 10014_bird.png
|
||||
| | |-- 10015_bird.png
|
||||
| | |-- ...
|
||||
| |
|
||||
| |-- ...
|
||||
|
|
||||
|-- test/
|
||||
| |-- airplane/
|
||||
| | |-- 10_airplane.png
|
||||
| | |-- 11_airplane.png
|
||||
| | |-- ...
|
||||
| |
|
||||
| |-- automobile/
|
||||
| | |-- 100_automobile.png
|
||||
| | |-- 101_automobile.png
|
||||
| | |-- ...
|
||||
| |
|
||||
| |-- bird/
|
||||
| | |-- 1000_bird.png
|
||||
| | |-- 1001_bird.png
|
||||
| | |-- ...
|
||||
| |
|
||||
| |-- ...
|
||||
```
|
||||
|
||||
In this example, the `train` directory contains subdirectories for each class in the dataset, and each class subdirectory contains all the images for that class. The `test` directory has a similar structure. The `root` directory also contains other files that are part of the CIFAR10 dataset.
|
||||
|
||||
## Usage
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
model.train(data='path/to/dataset', epochs=100, imgsz=640)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=path/to/data model=yolov8n-seg.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Supported Datasets
|
||||
|
||||
TODO
|
||||
7
docs/datasets/classify/mnist.md
Normal file
7
docs/datasets/classify/mnist.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
88
docs/datasets/detect/argoverse.md
Normal file
88
docs/datasets/detect/argoverse.md
Normal file
@ -0,0 +1,88 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn about the Argoverse dataset, a rich dataset designed to support research in autonomous driving tasks such as 3D tracking, motion forecasting, and stereo depth estimation.
|
||||
---
|
||||
|
||||
# Argoverse Dataset
|
||||
|
||||
The [Argoverse](https://www.argoverse.org/) dataset is a collection of data designed to support research in autonomous driving tasks, such as 3D tracking, motion forecasting, and stereo depth estimation. Developed by Argo AI, the dataset provides a wide range of high-quality sensor data, including high-resolution images, LiDAR point clouds, and map data.
|
||||
|
||||
## Key Features
|
||||
|
||||
- Argoverse contains over 290K labeled 3D object tracks and 5 million object instances across 1,263 distinct scenes.
|
||||
- The dataset includes high-resolution camera images, LiDAR point clouds, and richly annotated HD maps.
|
||||
- Annotations include 3D bounding boxes for objects, object tracks, and trajectory information.
|
||||
- Argoverse provides multiple subsets for different tasks, such as 3D tracking, motion forecasting, and stereo depth estimation.
|
||||
|
||||
## Dataset Structure
|
||||
|
||||
The Argoverse dataset is organized into three main subsets:
|
||||
|
||||
1. **Argoverse 3D Tracking**: This subset contains 113 scenes with over 290K labeled 3D object tracks, focusing on 3D object tracking tasks. It includes LiDAR point clouds, camera images, and sensor calibration information.
|
||||
2. **Argoverse Motion Forecasting**: This subset consists of 324K vehicle trajectories collected from 60 hours of driving data, suitable for motion forecasting tasks.
|
||||
3. **Argoverse Stereo Depth Estimation**: This subset is designed for stereo depth estimation tasks and includes over 10K stereo image pairs with corresponding LiDAR point clouds for ground truth depth estimation.
|
||||
|
||||
## Applications
|
||||
|
||||
The Argoverse dataset is widely used for training and evaluating deep learning models in autonomous driving tasks such as 3D object tracking, motion forecasting, and stereo depth estimation. The dataset's diverse set of sensor data, object annotations, and map information make it a valuable resource for researchers and practitioners in the field of autonomous driving.
|
||||
|
||||
## Dataset YAML
|
||||
|
||||
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the Argoverse dataset, the `Argoverse.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/Argoverse.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/Argoverse.yaml).
|
||||
|
||||
!!! example "ultralytics/datasets/Argoverse.yaml"
|
||||
|
||||
```yaml
|
||||
--8<-- "ultralytics/datasets/Argoverse.yaml"
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
To train a YOLOv8n model on the Argoverse dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
||||
|
||||
!!! example "Train Example"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
model.train(data='Argoverse.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=Argoverse.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Sample Data and Annotations
|
||||
|
||||
The Argoverse dataset contains a diverse set of sensor data, including camera images, LiDAR point clouds, and HD map information, providing rich context for autonomous driving tasks. Here are some examples of data from the dataset, along with their corresponding annotations:
|
||||
|
||||

|
||||
|
||||
- **Argoverse 3D Tracking**: This image demonstrates an example of 3D object tracking, where objects are annotated with 3D bounding boxes. The dataset provides LiDAR point clouds and camera images to facilitate the development of models for this task.
|
||||
|
||||
The example showcases the variety and complexity of the data in the Argoverse dataset and highlights the importance of high-quality sensor data for autonomous driving tasks.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
If you use the Argoverse dataset in your research or development work, please cite the following paper:
|
||||
|
||||
```bibtex
|
||||
@inproceedings{chang2019argoverse,
|
||||
title={Argoverse: 3D Tracking and Forecasting with Rich Maps},
|
||||
author={Chang, Ming-Fang and Lambert, John and Sangkloy, Patsorn and Singh, Jagjeet and Bak, Slawomir and Hartnett, Andrew and Wang, Dequan and Carr, Peter and Lucey, Simon and Ramanan, Deva and others},
|
||||
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
|
||||
pages={8748--8757},
|
||||
year={2019}
|
||||
}
|
||||
```
|
||||
|
||||
We would like to acknowledge Argo AI for creating and maintaining the Argoverse dataset as a valuable resource for the autonomous driving research community. For more information about the Argoverse dataset and its creators, visit the [Argoverse dataset website](https://www.argoverse.org/).
|
||||
89
docs/datasets/detect/coco.md
Normal file
89
docs/datasets/detect/coco.md
Normal file
@ -0,0 +1,89 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn about the COCO dataset, designed to encourage research on object detection, segmentation, and captioning with standardized evaluation metrics.
|
||||
---
|
||||
|
||||
# COCO Dataset
|
||||
|
||||
The [COCO](https://cocodataset.org/#home) (Common Objects in Context) dataset is a large-scale object detection, segmentation, and captioning dataset. It is designed to encourage research on a wide variety of object categories and is commonly used for benchmarking computer vision models. It is an essential dataset for researchers and developers working on object detection, segmentation, and pose estimation tasks.
|
||||
|
||||
## Key Features
|
||||
|
||||
- COCO contains 330K images, with 200K images having annotations for object detection, segmentation, and captioning tasks.
|
||||
- The dataset comprises 80 object categories, including common objects like cars, bicycles, and animals, as well as more specific categories such as umbrellas, handbags, and sports equipment.
|
||||
- Annotations include object bounding boxes, segmentation masks, and captions for each image.
|
||||
- COCO provides standardized evaluation metrics like mean Average Precision (mAP) for object detection, and mean Average Recall (mAR) for segmentation tasks, making it suitable for comparing model performance.
|
||||
|
||||
## Dataset Structure
|
||||
|
||||
The COCO dataset is split into three subsets:
|
||||
|
||||
1. **Train2017**: This subset contains 118K images for training object detection, segmentation, and captioning models.
|
||||
2. **Val2017**: This subset has 5K images used for validation purposes during model training.
|
||||
3. **Test2017**: This subset consists of 20K images used for testing and benchmarking the trained models. Ground truth annotations for this subset are not publicly available, and the results are submitted to the [COCO evaluation server](https://competitions.codalab.org/competitions/5181) for performance evaluation.
|
||||
|
||||
## Applications
|
||||
|
||||
The COCO dataset is widely used for training and evaluating deep learning models in object detection (such as YOLO, Faster R-CNN, and SSD), instance segmentation (such as Mask R-CNN), and keypoint detection (such as OpenPose). The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners.
|
||||
|
||||
## Dataset YAML
|
||||
|
||||
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO dataset, the `coco.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml).
|
||||
|
||||
!!! example "ultralytics/datasets/coco.yaml"
|
||||
|
||||
```yaml
|
||||
--8<-- "ultralytics/datasets/coco.yaml"
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
To train a YOLOv8n model on the COCO dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
||||
|
||||
!!! example "Train Example"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
model.train(data='coco.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=coco.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Sample Images and Annotations
|
||||
|
||||
The COCO dataset contains a diverse set of images with various object categories and complex scenes. Here are some examples of images from the dataset, along with their corresponding annotations:
|
||||
|
||||
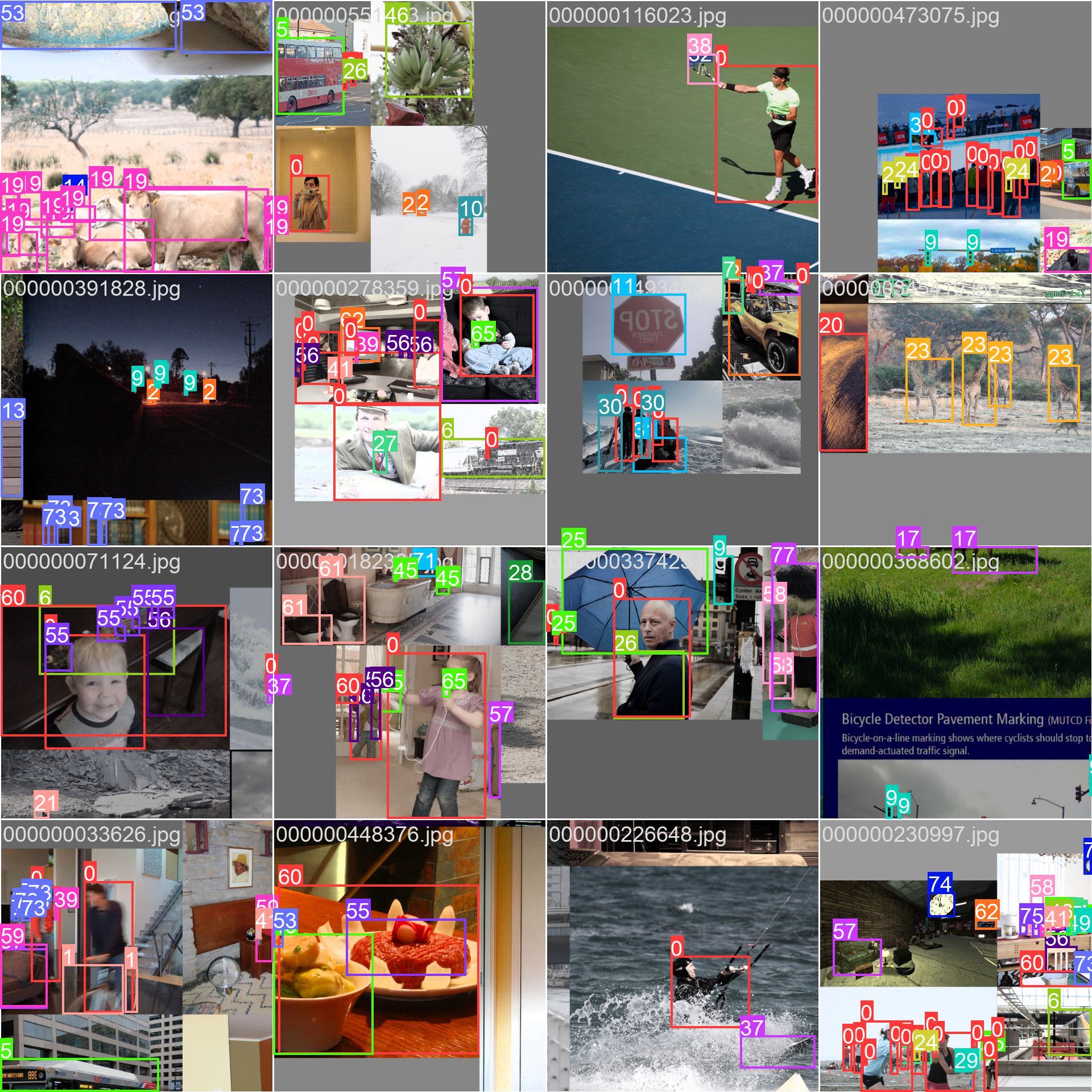
|
||||
|
||||
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
|
||||
|
||||
The example showcases the variety and complexity of the images in the COCO dataset and the benefits of using mosaicing during the training process.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
If you use the COCO dataset in your research or development work, please cite the following paper:
|
||||
|
||||
```bibtex
|
||||
@misc{lin2015microsoft,
|
||||
title={Microsoft COCO: Common Objects in Context},
|
||||
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
||||
year={2015},
|
||||
eprint={1405.0312},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
||||
79
docs/datasets/detect/coco8.md
Normal file
79
docs/datasets/detect/coco8.md
Normal file
@ -0,0 +1,79 @@
|
||||
---
|
||||
comments: true
|
||||
description: Get started with Ultralytics COCO8. Ideal for testing and debugging object detection models or experimenting with new detection approaches.
|
||||
---
|
||||
|
||||
# COCO8 Dataset
|
||||
|
||||
## Introduction
|
||||
|
||||
[Ultralytics](https://ultralytics.com) COCO8 is a small, but versatile object detection dataset composed of the first 8
|
||||
images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging
|
||||
object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be
|
||||
easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training
|
||||
larger datasets.
|
||||
|
||||
This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com)
|
||||
and [YOLOv8](https://github.com/ultralytics/ultralytics).
|
||||
|
||||
## Dataset YAML
|
||||
|
||||
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO8 dataset, the `coco8.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco8.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco8.yaml).
|
||||
|
||||
!!! example "ultralytics/datasets/coco8.yaml"
|
||||
|
||||
```yaml
|
||||
--8<-- "ultralytics/datasets/coco8.yaml"
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
To train a YOLOv8n model on the COCO8 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
||||
|
||||
!!! example "Train Example"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=coco8.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Sample Images and Annotations
|
||||
|
||||
Here are some examples of images from the COCO8 dataset, along with their corresponding annotations:
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/26833433/236818348-e6260a3d-0454-436b-83a9-de366ba07235.jpg" alt="Dataset sample image" width="800">
|
||||
|
||||
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
|
||||
|
||||
The example showcases the variety and complexity of the images in the COCO8 dataset and the benefits of using mosaicing during the training process.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
If you use the COCO dataset in your research or development work, please cite the following paper:
|
||||
|
||||
```bibtex
|
||||
@misc{lin2015microsoft,
|
||||
title={Microsoft COCO: Common Objects in Context},
|
||||
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
||||
year={2015},
|
||||
eprint={1405.0312},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
||||
86
docs/datasets/detect/globalwheat2020.md
Normal file
86
docs/datasets/detect/globalwheat2020.md
Normal file
@ -0,0 +1,86 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn about the Global Wheat Head Dataset, aimed at supporting the development of accurate wheat head models for applications in wheat phenotyping and crop management.
|
||||
---
|
||||
|
||||
# Global Wheat Head Dataset
|
||||
|
||||
The [Global Wheat Head Dataset](http://www.global-wheat.com/) is a collection of images designed to support the development of accurate wheat head detection models for applications in wheat phenotyping and crop management. Wheat heads, also known as spikes, are the grain-bearing parts of the wheat plant. Accurate estimation of wheat head density and size is essential for assessing crop health, maturity, and yield potential. The dataset, created by a collaboration of nine research institutes from seven countries, covers multiple growing regions to ensure models generalize well across different environments.
|
||||
|
||||
## Key Features
|
||||
|
||||
- The dataset contains over 3,000 training images from Europe (France, UK, Switzerland) and North America (Canada).
|
||||
- It includes approximately 1,000 test images from Australia, Japan, and China.
|
||||
- Images are outdoor field images, capturing the natural variability in wheat head appearances.
|
||||
- Annotations include wheat head bounding boxes to support object detection tasks.
|
||||
|
||||
## Dataset Structure
|
||||
|
||||
The Global Wheat Head Dataset is organized into two main subsets:
|
||||
|
||||
1. **Training Set**: This subset contains over 3,000 images from Europe and North America. The images are labeled with wheat head bounding boxes, providing ground truth for training object detection models.
|
||||
2. **Test Set**: This subset consists of approximately 1,000 images from Australia, Japan, and China. These images are used for evaluating the performance of trained models on unseen genotypes, environments, and observational conditions.
|
||||
|
||||
## Applications
|
||||
|
||||
The Global Wheat Head Dataset is widely used for training and evaluating deep learning models in wheat head detection tasks. The dataset's diverse set of images, capturing a wide range of appearances, environments, and conditions, make it a valuable resource for researchers and practitioners in the field of plant phenotyping and crop management.
|
||||
|
||||
## Dataset YAML
|
||||
|
||||
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the Global Wheat Head Dataset, the `GlobalWheat2020.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/GlobalWheat2020.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/GlobalWheat2020.yaml).
|
||||
|
||||
!!! example "ultralytics/datasets/GlobalWheat2020.yaml"
|
||||
|
||||
```yaml
|
||||
--8<-- "ultralytics/datasets/GlobalWheat2020.yaml"
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
To train a YOLOv8n model on the Global Wheat Head Dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
||||
|
||||
!!! example "Train Example"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
model.train(data='GlobalWheat2020.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=GlobalWheat2020.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Sample Data and Annotations
|
||||
|
||||
The Global Wheat Head Dataset contains a diverse set of outdoor field images, capturing the natural variability in wheat head appearances, environments, and conditions. Here are some examples of data from the dataset, along with their corresponding annotations:
|
||||
|
||||

|
||||
|
||||
- **Wheat Head Detection**: This image demonstrates an example of wheat head detection, where wheat heads are annotated with bounding boxes. The dataset provides a variety of images to facilitate the development of models for this task.
|
||||
|
||||
The example showcases the variety and complexity of the data in the Global Wheat Head Dataset and highlights the importance of accurate wheat head detection for applications in wheat phenotyping and crop management.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
If you use the Global Wheat Head Dataset in your research or development work, please cite the following paper:
|
||||
|
||||
```bibtex
|
||||
@article{david2020global,
|
||||
title={Global Wheat Head Detection (GWHD) Dataset: A Large and Diverse Dataset of High-Resolution RGB-Labelled Images to Develop and Benchmark Wheat Head Detection Methods},
|
||||
author={David, Etienne and Madec, Simon and Sadeghi-Tehran, Pouria and Aasen, Helge and Zheng, Bangyou and Liu, Shouyang and Kirchgessner, Norbert and Ishikawa, Goro and Nagasawa, Koichi and Badhon, Minhajul and others},
|
||||
journal={arXiv preprint arXiv:2005.02162},
|
||||
year={2020}
|
||||
}
|
||||
```
|
||||
|
||||
We would like to acknowledge the researchers and institutions that contributed to the creation and maintenance of the Global Wheat Head Dataset as a valuable resource for the plant phenotyping and crop management research community. For more information about the dataset and its creators, visit the [Global Wheat Head Dataset website](http://www.global-wheat.com/).
|
||||
111
docs/datasets/detect/index.md
Normal file
111
docs/datasets/detect/index.md
Normal file
@ -0,0 +1,111 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn about supported dataset formats for training YOLO detection models, including Ultralytics YOLO and COCO, in this Object Detection Datasets Overview.
|
||||
---
|
||||
|
||||
# Object Detection Datasets Overview
|
||||
|
||||
## Supported Dataset Formats
|
||||
|
||||
### Ultralytics YOLO format
|
||||
|
||||
** Label Format **
|
||||
|
||||
The dataset format used for training YOLO detection models is as follows:
|
||||
|
||||
1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the ".txt" extension.
|
||||
2. One row per object: Each row in the text file corresponds to one object instance in the image.
|
||||
3. Object information per row: Each row contains the following information about the object instance:
|
||||
- Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).
|
||||
- Object center coordinates: The x and y coordinates of the center of the object, normalized to be between 0 and 1.
|
||||
- Object width and height: The width and height of the object, normalized to be between 0 and 1.
|
||||
|
||||
The format for a single row in the detection dataset file is as follows:
|
||||
|
||||
```
|
||||
<object-class> <x> <y> <width> <height>
|
||||
```
|
||||
|
||||
Here is an example of the YOLO dataset format for a single image with two object instances:
|
||||
|
||||
```
|
||||
0 0.5 0.4 0.3 0.6
|
||||
1 0.3 0.7 0.4 0.2
|
||||
```
|
||||
|
||||
In this example, the first object is of class 0 (person), with its center at (0.5, 0.4), width of 0.3, and height of 0.6. The second object is of class 1 (car), with its center at (0.3, 0.7), width of 0.4, and height of 0.2.
|
||||
|
||||
** Dataset file format **
|
||||
|
||||
The Ultralytics framework uses a YAML file format to define the dataset and model configuration for training Detection Models. Here is an example of the YAML format used for defining a detection dataset:
|
||||
|
||||
```
|
||||
train: <path-to-training-images>
|
||||
val: <path-to-validation-images>
|
||||
|
||||
nc: <number-of-classes>
|
||||
names: [<class-1>, <class-2>, ..., <class-n>]
|
||||
|
||||
```
|
||||
|
||||
The `train` and `val` fields specify the paths to the directories containing the training and validation images, respectively.
|
||||
|
||||
The `nc` field specifies the number of object classes in the dataset.
|
||||
|
||||
The `names` field is a list of the names of the object classes. The order of the names should match the order of the object class indices in the YOLO dataset files.
|
||||
|
||||
NOTE: Either `nc` or `names` must be defined. Defining both are not mandatory
|
||||
|
||||
Alternatively, you can directly define class names like this:
|
||||
|
||||
```yaml
|
||||
names:
|
||||
0: person
|
||||
1: bicycle
|
||||
```
|
||||
|
||||
** Example **
|
||||
|
||||
```yaml
|
||||
train: data/train/
|
||||
val: data/val/
|
||||
|
||||
nc: 2
|
||||
names: ['person', 'car']
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
model.train(data='coco128.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Supported Datasets
|
||||
|
||||
TODO
|
||||
|
||||
## Port or Convert label formats
|
||||
|
||||
### COCO dataset format to YOLO format
|
||||
|
||||
```
|
||||
from ultralytics.yolo.data.converter import convert_coco
|
||||
|
||||
convert_coco(labels_dir='../coco/annotations/')
|
||||
```
|
||||
7
docs/datasets/detect/objects365.md
Normal file
7
docs/datasets/detect/objects365.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
7
docs/datasets/detect/sku-110k.md
Normal file
7
docs/datasets/detect/sku-110k.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
7
docs/datasets/detect/visdrone.md
Normal file
7
docs/datasets/detect/visdrone.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
90
docs/datasets/detect/voc.md
Normal file
90
docs/datasets/detect/voc.md
Normal file
@ -0,0 +1,90 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn about the VOC dataset, designed to encourage research on object detection, segmentation, and classification with standardized evaluation metrics.
|
||||
---
|
||||
|
||||
# VOC Dataset
|
||||
|
||||
The [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/) (Visual Object Classes) dataset is a well-known object detection, segmentation, and classification dataset. It is designed to encourage research on a wide variety of object categories and is commonly used for benchmarking computer vision models. It is an essential dataset for researchers and developers working on object detection, segmentation, and classification tasks.
|
||||
|
||||
## Key Features
|
||||
|
||||
- VOC dataset includes two main challenges: VOC2007 and VOC2012.
|
||||
- The dataset comprises 20 object categories, including common objects like cars, bicycles, and animals, as well as more specific categories such as boats, sofas, and dining tables.
|
||||
- Annotations include object bounding boxes and class labels for object detection and classification tasks, and segmentation masks for the segmentation tasks.
|
||||
- VOC provides standardized evaluation metrics like mean Average Precision (mAP) for object detection and classification, making it suitable for comparing model performance.
|
||||
|
||||
## Dataset Structure
|
||||
|
||||
The VOC dataset is split into three subsets:
|
||||
|
||||
1. **Train**: This subset contains images for training object detection, segmentation, and classification models.
|
||||
2. **Validation**: This subset has images used for validation purposes during model training.
|
||||
3. **Test**: This subset consists of images used for testing and benchmarking the trained models. Ground truth annotations for this subset are not publicly available, and the results are submitted to the [PASCAL VOC evaluation server](http://host.robots.ox.ac.uk:8080/leaderboard/displaylb.php) for performance evaluation.
|
||||
|
||||
## Applications
|
||||
|
||||
The VOC dataset is widely used for training and evaluating deep learning models in object detection (such as YOLO, Faster R-CNN, and SSD), instance segmentation (such as Mask R-CNN), and image classification. The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners.
|
||||
|
||||
## Dataset YAML
|
||||
|
||||
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the VOC dataset, the `VOC.yaml` file should be created and maintained.
|
||||
|
||||
!!! example "ultralytics/datasets/VOC.yaml"
|
||||
|
||||
```yaml
|
||||
--8<-- "ultralytics/datasets/VOC.yaml"
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
To train a YOLOv8n model on the VOC dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
||||
|
||||
!!! example "Train Example"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
model.train(data='VOC.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from
|
||||
a pretrained *.pt model
|
||||
yolo detect train data=VOC.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Sample Images and Annotations
|
||||
|
||||
The VOC dataset contains a diverse set of images with various object categories and complex scenes. Here are some examples of images from the dataset, along with their corresponding annotations:
|
||||
|
||||

|
||||
|
||||
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
|
||||
|
||||
The example showcases the variety and complexity of the images in the VOC dataset and the benefits of using mosaicing during the training process.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
If you use the VOC dataset in your research or development work, please cite the following paper:
|
||||
|
||||
```bibtex
|
||||
@misc{everingham2010pascal,
|
||||
title={The PASCAL Visual Object Classes (VOC) Challenge},
|
||||
author={Mark Everingham and Luc Van Gool and Christopher K. I. Williams and John Winn and Andrew Zisserman},
|
||||
year={2010},
|
||||
eprint={0909.5206},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
We would like to acknowledge the PASCAL VOC Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the VOC dataset and its creators, visit the [PASCAL VOC dataset website](http://host.robots.ox.ac.uk/pascal/VOC/).
|
||||
7
docs/datasets/detect/xview.md
Normal file
7
docs/datasets/detect/xview.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
58
docs/datasets/index.md
Normal file
58
docs/datasets/index.md
Normal file
@ -0,0 +1,58 @@
|
||||
---
|
||||
comments: true
|
||||
description: Ultralytics provides support for various datasets to facilitate multiple computer vision tasks. Check out our list of main datasets and their summaries.
|
||||
---
|
||||
|
||||
# Datasets Overview
|
||||
|
||||
Ultralytics provides support for various datasets to facilitate computer vision tasks such as detection, instance segmentation, pose estimation, classification, and multi-object tracking. Below is a list of the main Ultralytics datasets, followed by a summary of each computer vision task and the respective datasets.
|
||||
|
||||
## [Detection Datasets](detect/index.md)
|
||||
|
||||
Bounding box object detection is a computer vision technique that involves detecting and localizing objects in an image by drawing a bounding box around each object.
|
||||
|
||||
* [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations.
|
||||
* [COCO](detect/coco.md): A large-scale dataset designed for object detection, segmentation, and captioning with over 200K labeled images.
|
||||
* [COCO8](detect/coco8.md): Contains the first 4 images from COCO train and COCO val, suitable for quick tests.
|
||||
* [Global Wheat 2020](detect/globalwheat2020.md): A dataset of wheat head images collected from around the world for object detection and localization tasks.
|
||||
* [Objects365](detect/objects365.md): A high-quality, large-scale dataset for object detection with 365 object categories and over 600K annotated images.
|
||||
* [SKU-110K](detect/sku-110k.md): A dataset featuring dense object detection in retail environments with over 11K images and 1.7 million bounding boxes.
|
||||
* [VisDrone](detect/visdrone.md): A dataset containing object detection and multi-object tracking data from drone-captured imagery with over 10K images and video sequences.
|
||||
* [VOC](detect/voc.md): The Pascal Visual Object Classes (VOC) dataset for object detection and segmentation with 20 object classes and over 11K images.
|
||||
* [xView](detect/xview.md): A dataset for object detection in overhead imagery with 60 object categories and over 1 million annotated objects.
|
||||
|
||||
## [Instance Segmentation Datasets](segment/index.md)
|
||||
|
||||
Instance segmentation is a computer vision technique that involves identifying and localizing objects in an image at the pixel level.
|
||||
|
||||
* [COCO](segment/coco.md): A large-scale dataset designed for object detection, segmentation, and captioning tasks with over 200K labeled images.
|
||||
* [COCO8-seg](segment/coco8-seg.md): A smaller dataset for instance segmentation tasks, containing a subset of 8 COCO images with segmentation annotations.
|
||||
|
||||
## [Pose Estimation](pose/index.md)
|
||||
|
||||
Pose estimation is a technique used to determine the pose of the object relative to the camera or the world coordinate system.
|
||||
|
||||
* [COCO](pose/coco.md): A large-scale dataset with human pose annotations designed for pose estimation tasks.
|
||||
* [COCO8-pose](pose/coco8-pose.md): A smaller dataset for pose estimation tasks, containing a subset of 8 COCO images with human pose annotations.
|
||||
|
||||
## [Classification](classify/index.md)
|
||||
|
||||
Image classification is a computer vision task that involves categorizing an image into one or more predefined classes or categories based on its visual content.
|
||||
|
||||
* [Caltech 101](classify/caltech101.md): A dataset containing images of 101 object categories for image classification tasks.
|
||||
* [Caltech 256](classify/caltech256.md): An extended version of Caltech 101 with 256 object categories and more challenging images.
|
||||
* [CIFAR-10](classify/cifar10.md): A dataset of 60K 32x32 color images in 10 classes, with 6K images per class.
|
||||
* [CIFAR-100](classify/cifar100.md): An extended version of CIFAR-10 with 100 object categories and 600 images per class.
|
||||
* [Fashion-MNIST](classify/fashion-mnist.md): A dataset consisting of 70,000 grayscale images of 10 fashion categories for image classification tasks.
|
||||
* [ImageNet](classify/imagenet.md): A large-scale dataset for object detection and image classification with over 14 million images and 20,000 categories.
|
||||
* [ImageNet-10](classify/imagenet10.md): A smaller subset of ImageNet with 10 categories for faster experimentation and testing.
|
||||
* [Imagenette](classify/imagenette.md): A smaller subset of ImageNet that contains 10 easily distinguishable classes for quicker training and testing.
|
||||
* [Imagewoof](classify/imagewoof.md): A more challenging subset of ImageNet containing 10 dog breed categories for image classification tasks.
|
||||
* [MNIST](classify/mnist.md): A dataset of 70,000 grayscale images of handwritten digits for image classification tasks.
|
||||
|
||||
## [Multi-Object Tracking](track/index.md)
|
||||
|
||||
Multi-object tracking is a computer vision technique that involves detecting and tracking multiple objects over time in a video sequence.
|
||||
|
||||
* [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations for multi-object tracking tasks.
|
||||
* [VisDrone](detect/visdrone.md): A dataset containing object detection and multi-object tracking data from drone-captured imagery with over 10K images and video sequences.
|
||||
7
docs/datasets/pose/coco.md
Normal file
7
docs/datasets/pose/coco.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
79
docs/datasets/pose/coco8-pose.md
Normal file
79
docs/datasets/pose/coco8-pose.md
Normal file
@ -0,0 +1,79 @@
|
||||
---
|
||||
comments: true
|
||||
description: Test and debug object detection models with Ultralytics COCO8-Pose Dataset - a small, versatile pose detection dataset with 8 images.
|
||||
---
|
||||
|
||||
# COCO8-Pose Dataset
|
||||
|
||||
## Introduction
|
||||
|
||||
[Ultralytics](https://ultralytics.com) COCO8-Pose is a small, but versatile pose detection dataset composed of the first
|
||||
8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and
|
||||
debugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough
|
||||
to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before
|
||||
training larger datasets.
|
||||
|
||||
This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com)
|
||||
and [YOLOv8](https://github.com/ultralytics/ultralytics).
|
||||
|
||||
## Dataset YAML
|
||||
|
||||
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO8-Pose dataset, the `coco8-pose.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco8-pose.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco8-pose.yaml).
|
||||
|
||||
!!! example "ultralytics/datasets/coco8-pose.yaml"
|
||||
|
||||
```yaml
|
||||
--8<-- "ultralytics/datasets/coco8-pose.yaml"
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
To train a YOLOv8n model on the COCO8-Pose dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
||||
|
||||
!!! example "Train Example"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
model.train(data='coco8-pose.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=coco8-pose.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Sample Images and Annotations
|
||||
|
||||
Here are some examples of images from the COCO8-Pose dataset, along with their corresponding annotations:
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/26833433/236818283-52eecb96-fc6a-420d-8a26-d488b352dd4c.jpg" alt="Dataset sample image" width="800">
|
||||
|
||||
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
|
||||
|
||||
The example showcases the variety and complexity of the images in the COCO8-Pose dataset and the benefits of using mosaicing during the training process.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
If you use the COCO dataset in your research or development work, please cite the following paper:
|
||||
|
||||
```bibtex
|
||||
@misc{lin2015microsoft,
|
||||
title={Microsoft COCO: Common Objects in Context},
|
||||
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
||||
year={2015},
|
||||
eprint={1405.0312},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
||||
124
docs/datasets/pose/index.md
Normal file
124
docs/datasets/pose/index.md
Normal file
@ -0,0 +1,124 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to format your dataset for training YOLO models with Ultralytics YOLO format using our concise tutorial and example YAML files.
|
||||
---
|
||||
|
||||
# Pose Estimation Datasets Overview
|
||||
|
||||
## Supported Dataset Formats
|
||||
|
||||
### Ultralytics YOLO format
|
||||
|
||||
** Label Format **
|
||||
|
||||
The dataset format used for training YOLO segmentation models is as follows:
|
||||
|
||||
1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the ".txt" extension.
|
||||
2. One row per object: Each row in the text file corresponds to one object instance in the image.
|
||||
3. Object information per row: Each row contains the following information about the object instance:
|
||||
- Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).
|
||||
- Object center coordinates: The x and y coordinates of the center of the object, normalized to be between 0 and 1.
|
||||
- Object width and height: The width and height of the object, normalized to be between 0 and 1.
|
||||
- Object keypoint coordinates: The keypoints of the object, normalized to be between 0 and 1.
|
||||
|
||||
Here is an example of the label format for pose estimation task:
|
||||
|
||||
Format with Dim = 2
|
||||
|
||||
```
|
||||
<class-index> <x> <y> <width> <height> <px1> <py1> <px2> <py2> ... <pxn> <pyn>
|
||||
```
|
||||
|
||||
Format with Dim = 3
|
||||
|
||||
```
|
||||
<class-index> <x> <y> <width> <height> <px1> <py1> <p1-visibility> <px2> <py2> <p2-visibility> <pxn> <pyn> <p2-visibility>
|
||||
```
|
||||
|
||||
In this format, `<class-index>` is the index of the class for the object,`<x> <y> <width> <height>` are coordinates of boudning box, and `<px1> <py1> <px2> <py2> ... <pxn> <pyn>` are the pixel coordinates of the keypoints. The coordinates are separated by spaces.
|
||||
|
||||
** Dataset file format **
|
||||
|
||||
The Ultralytics framework uses a YAML file format to define the dataset and model configuration for training Detection Models. Here is an example of the YAML format used for defining a detection dataset:
|
||||
|
||||
```yaml
|
||||
train: <path-to-training-images>
|
||||
val: <path-to-validation-images>
|
||||
|
||||
nc: <number-of-classes>
|
||||
names: [<class-1>, <class-2>, ..., <class-n>]
|
||||
|
||||
# Keypoints
|
||||
kpt_shape: [num_kpts, dim] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
|
||||
flip_idx: [n1, n2 ... , n(num_kpts)]
|
||||
|
||||
```
|
||||
|
||||
The `train` and `val` fields specify the paths to the directories containing the training and validation images, respectively.
|
||||
|
||||
The `nc` field specifies the number of object classes in the dataset.
|
||||
|
||||
The `names` field is a list of the names of the object classes. The order of the names should match the order of the object class indices in the YOLO dataset files.
|
||||
|
||||
NOTE: Either `nc` or `names` must be defined. Defining both are not mandatory
|
||||
|
||||
Alternatively, you can directly define class names like this:
|
||||
|
||||
```
|
||||
names:
|
||||
0: person
|
||||
1: bicycle
|
||||
```
|
||||
|
||||
(Optional) if the points are symmetric then need flip_idx, like left-right side of human or face.
|
||||
For example let's say there're five keypoints of facial landmark: [left eye, right eye, nose, left point of mouth, right point of mouse], and the original index is [0, 1, 2, 3, 4], then flip_idx is [1, 0, 2, 4, 3].(just exchange the left-right index, i.e 0-1 and 3-4, and do not modify others like nose in this example)
|
||||
|
||||
** Example **
|
||||
|
||||
```yaml
|
||||
train: data/train/
|
||||
val: data/val/
|
||||
|
||||
nc: 2
|
||||
names: ['person', 'car']
|
||||
|
||||
# Keypoints
|
||||
kpt_shape: [17, 3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
|
||||
flip_idx: [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15]
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n-pose.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
model.train(data='coco128-pose.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=coco128-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Supported Datasets
|
||||
|
||||
TODO
|
||||
|
||||
## Port or Convert label formats
|
||||
|
||||
### COCO dataset format to YOLO format
|
||||
|
||||
```
|
||||
from ultralytics.yolo.data.converter import convert_coco
|
||||
|
||||
convert_coco(labels_dir='../coco/annotations/', use_keypoints=True)
|
||||
```
|
||||
7
docs/datasets/segment/coco.md
Normal file
7
docs/datasets/segment/coco.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
79
docs/datasets/segment/coco8-seg.md
Normal file
79
docs/datasets/segment/coco8-seg.md
Normal file
@ -0,0 +1,79 @@
|
||||
---
|
||||
comments: true
|
||||
description: Test and debug segmentation models on small, versatile COCO8-Seg instance segmentation dataset, now available for use with YOLOv8 and Ultralytics HUB.
|
||||
---
|
||||
|
||||
# COCO8-Seg Dataset
|
||||
|
||||
## Introduction
|
||||
|
||||
[Ultralytics](https://ultralytics.com) COCO8-Seg is a small, but versatile instance segmentation dataset composed of the
|
||||
first 8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and
|
||||
debugging segmentation models, or for experimenting with new detection approaches. With 8 images, it is small enough to
|
||||
be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training
|
||||
larger datasets.
|
||||
|
||||
This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com)
|
||||
and [YOLOv8](https://github.com/ultralytics/ultralytics).
|
||||
|
||||
## Dataset YAML
|
||||
|
||||
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO8-Seg dataset, the `coco8-seg.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco8-seg.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco8-seg.yaml).
|
||||
|
||||
!!! example "ultralytics/datasets/coco8-seg.yaml"
|
||||
|
||||
```yaml
|
||||
--8<-- "ultralytics/datasets/coco8-seg.yaml"
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
To train a YOLOv8n model on the COCO8-Seg dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
||||
|
||||
!!! example "Train Example"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
model.train(data='coco8-seg.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=coco8-seg.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Sample Images and Annotations
|
||||
|
||||
Here are some examples of images from the COCO8-Seg dataset, along with their corresponding annotations:
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/26833433/236818387-f7bde7df-caaa-46d1-8341-1f7504cd11a1.jpg" alt="Dataset sample image" width="800">
|
||||
|
||||
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
|
||||
|
||||
The example showcases the variety and complexity of the images in the COCO8-Seg dataset and the benefits of using mosaicing during the training process.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
If you use the COCO dataset in your research or development work, please cite the following paper:
|
||||
|
||||
```bibtex
|
||||
@misc{lin2015microsoft,
|
||||
title={Microsoft COCO: Common Objects in Context},
|
||||
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
||||
year={2015},
|
||||
eprint={1405.0312},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
||||
136
docs/datasets/segment/index.md
Normal file
136
docs/datasets/segment/index.md
Normal file
@ -0,0 +1,136 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn about the Ultralytics YOLO dataset format for segmentation models. Use YAML to train Detection Models. Convert COCO to YOLO format using Python.
|
||||
---
|
||||
|
||||
# Instance Segmentation Datasets Overview
|
||||
|
||||
## Supported Dataset Formats
|
||||
|
||||
### Ultralytics YOLO format
|
||||
|
||||
** Label Format **
|
||||
|
||||
The dataset format used for training YOLO segmentation models is as follows:
|
||||
|
||||
1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the ".txt" extension.
|
||||
2. One row per object: Each row in the text file corresponds to one object instance in the image.
|
||||
3. Object information per row: Each row contains the following information about the object instance:
|
||||
- Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).
|
||||
- Object bounding coordinates: The bounding coordinates around the mask area, normalized to be between 0 and 1.
|
||||
|
||||
The format for a single row in the segmentation dataset file is as follows:
|
||||
|
||||
```
|
||||
<class-index> <x1> <y1> <x2> <y2> ... <xn> <yn>
|
||||
```
|
||||
|
||||
In this format, `<class-index>` is the index of the class for the object, and `<x1> <y1> <x2> <y2> ... <xn> <yn>` are the bounding coordinates of the object's segmentation mask. The coordinates are separated by spaces.
|
||||
|
||||
Here is an example of the YOLO dataset format for a single image with two object instances:
|
||||
|
||||
```
|
||||
0 0.6812 0.48541 0.67 0.4875 0.67656 0.487 0.675 0.489 0.66
|
||||
1 0.5046 0.0 0.5015 0.004 0.4984 0.00416 0.4937 0.010 0.492 0.0104
|
||||
```
|
||||
|
||||
Note: The length of each row does not have to be equal.
|
||||
|
||||
** Dataset file format **
|
||||
|
||||
The Ultralytics framework uses a YAML file format to define the dataset and model configuration for training Detection Models. Here is an example of the YAML format used for defining a detection dataset:
|
||||
|
||||
```yaml
|
||||
train: <path-to-training-images>
|
||||
val: <path-to-validation-images>
|
||||
|
||||
nc: <number-of-classes>
|
||||
names: [ <class-1>, <class-2>, ..., <class-n> ]
|
||||
|
||||
```
|
||||
|
||||
The `train` and `val` fields specify the paths to the directories containing the training and validation images, respectively.
|
||||
|
||||
The `nc` field specifies the number of object classes in the dataset.
|
||||
|
||||
The `names` field is a list of the names of the object classes. The order of the names should match the order of the object class indices in the YOLO dataset files.
|
||||
|
||||
NOTE: Either `nc` or `names` must be defined. Defining both are not mandatory.
|
||||
|
||||
Alternatively, you can directly define class names like this:
|
||||
|
||||
```yaml
|
||||
names:
|
||||
0: person
|
||||
1: bicycle
|
||||
```
|
||||
|
||||
** Example **
|
||||
|
||||
```yaml
|
||||
train: data/train/
|
||||
val: data/val/
|
||||
|
||||
nc: 2
|
||||
names: [ 'person', 'car' ]
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
model.train(data='coco128-seg.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=coco128-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Supported Datasets
|
||||
|
||||
## Port or Convert label formats
|
||||
|
||||
### COCO dataset format to YOLO format
|
||||
|
||||
```
|
||||
from ultralytics.yolo.data.converter import convert_coco
|
||||
|
||||
convert_coco(labels_dir='../coco/annotations/', use_segments=True)
|
||||
```
|
||||
|
||||
## Auto-Annotation
|
||||
|
||||
Auto-annotation is an essential feature that allows you to generate a segmentation dataset using a pre-trained detection model. It enables you to quickly and accurately annotate a large number of images without the need for manual labeling, saving time and effort.
|
||||
|
||||
### Generate Segmentation Dataset Using a Detection Model
|
||||
|
||||
To auto-annotate your dataset using the Ultralytics framework, you can use the `auto_annotate` function as shown below:
|
||||
|
||||
```python
|
||||
from ultralytics.yolo.data import auto_annotate
|
||||
|
||||
auto_annotate(data="path/to/images", det_model="yolov8x.pt", sam_model='sam_b.pt')
|
||||
```
|
||||
|
||||
| Argument | Type | Description | Default |
|
||||
|------------|---------------------|---------------------------------------------------------------------------------------------------------|--------------|
|
||||
| data | str | Path to a folder containing images to be annotated. | |
|
||||
| det_model | str, optional | Pre-trained YOLO detection model. Defaults to 'yolov8x.pt'. | 'yolov8x.pt' |
|
||||
| sam_model | str, optional | Pre-trained SAM segmentation model. Defaults to 'sam_b.pt'. | 'sam_b.pt' |
|
||||
| device | str, optional | Device to run the models on. Defaults to an empty string (CPU or GPU, if available). | |
|
||||
| output_dir | str, None, optional | Directory to save the annotated results. Defaults to a 'labels' folder in the same directory as 'data'. | None |
|
||||
|
||||
The `auto_annotate` function takes the path to your images, along with optional arguments for specifying the pre-trained detection and [SAM segmentation models](https://docs.ultralytics.com/models/sam), the device to run the models on, and the output directory for saving the annotated results.
|
||||
|
||||
By leveraging the power of pre-trained models, auto-annotation can significantly reduce the time and effort required for creating high-quality segmentation datasets. This feature is particularly useful for researchers and developers working with large image collections, as it allows them to focus on model development and evaluation rather than manual annotation.
|
||||
29
docs/datasets/track/index.md
Normal file
29
docs/datasets/track/index.md
Normal file
@ -0,0 +1,29 @@
|
||||
---
|
||||
comments: true
|
||||
description: Discover the datasets compatible with Multi-Object Detector. Train your trackers and make your detections more efficient with Ultralytics' YOLO.
|
||||
---
|
||||
|
||||
# Multi-object Tracking Datasets Overview
|
||||
|
||||
## Dataset Format (Coming Soon)
|
||||
|
||||
Multi-Object Detector doesn't need standalone training and directly supports pre-trained detection, segmentation or Pose models.
|
||||
Support for training trackers alone is coming soon
|
||||
|
||||
## Usage
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
model = YOLO('yolov8n.pt')
|
||||
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", conf=0.3, iou=0.5, show=True)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" conf=0.3, iou=0.5 show
|
||||
```
|
||||
69
docs/help/CLA.md
Normal file
69
docs/help/CLA.md
Normal file
@ -0,0 +1,69 @@
|
||||
---
|
||||
description: Individual Contributor License Agreement. Settle Intellectual Property issues for Contributions made to anything open source released by Ultralytics.
|
||||
---
|
||||
|
||||
# Ultralytics Individual Contributor License Agreement
|
||||
|
||||
Thank you for your interest in contributing to open source software projects (“Projects”) made available by Ultralytics
|
||||
SE or its affiliates (“Ultralytics”). This Individual Contributor License Agreement (“Agreement”) sets out the terms
|
||||
governing any source code, object code, bug fixes, configuration changes, tools, specifications, documentation, data,
|
||||
materials, feedback, information or other works of authorship that you submit or have submitted, in any form and in any
|
||||
manner, to Ultralytics in respect of any of the Projects (collectively “Contributions”). If you have any questions
|
||||
respecting this Agreement, please contact hello@ultralytics.com.
|
||||
|
||||
You agree that the following terms apply to all of your past, present and future Contributions. Except for the licenses
|
||||
granted in this Agreement, you retain all of your right, title and interest in and to your Contributions.
|
||||
|
||||
**Copyright License.** You hereby grant, and agree to grant, to Ultralytics a non-exclusive, perpetual, irrevocable,
|
||||
worldwide, fully-paid, royalty-free, transferable copyright license to reproduce, prepare derivative works of, publicly
|
||||
display, publicly perform, and distribute your Contributions and such derivative works, with the right to sublicense the
|
||||
foregoing rights through multiple tiers of sublicensees.
|
||||
|
||||
**Patent License.** You hereby grant, and agree to grant, to Ultralytics a non-exclusive, perpetual, irrevocable,
|
||||
worldwide, fully-paid, royalty-free, transferable patent license to make, have made, use, offer to sell, sell,
|
||||
import, and otherwise transfer your Contributions, where such license applies only to those patent claims
|
||||
licensable by you that are necessarily infringed by your Contributions alone or by combination of your
|
||||
Contributions with the Project to which such Contributions were submitted, with the right to sublicense the
|
||||
foregoing rights through multiple tiers of sublicensees.
|
||||
|
||||
**Moral Rights.** To the fullest extent permitted under applicable law, you hereby waive, and agree not to
|
||||
assert, all of your “moral rights” in or relating to your Contributions for the benefit of Ultralytics, its assigns, and
|
||||
their respective direct and indirect sublicensees.
|
||||
|
||||
**Third Party Content/Rights.** If your Contribution includes or is based on any source code, object code, bug
|
||||
fixes, configuration changes, tools, specifications, documentation, data, materials, feedback, information or
|
||||
other works of authorship that were not authored by you (“Third Party Content”) or if you are aware of any
|
||||
third party intellectual property or proprietary rights associated with your Contribution (“Third Party Rights”),
|
||||
then you agree to include with the submission of your Contribution full details respecting such Third Party
|
||||
Content and Third Party Rights, including, without limitation, identification of which aspects of your
|
||||
Contribution contain Third Party Content or are associated with Third Party Rights, the owner/author of the
|
||||
Third Party Content and Third Party Rights, where you obtained the Third Party Content, and any applicable
|
||||
third party license terms or restrictions respecting the Third Party Content and Third Party Rights. For greater
|
||||
certainty, the foregoing obligations respecting the identification of Third Party Content and Third Party Rights
|
||||
do not apply to any portion of a Project that is incorporated into your Contribution to that same Project.
|
||||
|
||||
**Representations.** You represent that, other than the Third Party Content and Third Party Rights identified by
|
||||
you in accordance with this Agreement, you are the sole author of your Contributions and are legally entitled
|
||||
to grant the foregoing licenses and waivers in respect of your Contributions. If your Contributions were
|
||||
created in the course of your employment with your past or present employer(s), you represent that such
|
||||
employer(s) has authorized you to make your Contributions on behalf of such employer(s) or such employer
|
||||
(s) has waived all of their right, title or interest in or to your Contributions.
|
||||
|
||||
**Disclaimer.** To the fullest extent permitted under applicable law, your Contributions are provided on an "asis"
|
||||
basis, without any warranties or conditions, express or implied, including, without limitation, any implied
|
||||
warranties or conditions of non-infringement, merchantability or fitness for a particular purpose. You are not
|
||||
required to provide support for your Contributions, except to the extent you desire to provide support.
|
||||
|
||||
**No Obligation.** You acknowledge that Ultralytics is under no obligation to use or incorporate your Contributions
|
||||
into any of the Projects. The decision to use or incorporate your Contributions into any of the Projects will be
|
||||
made at the sole discretion of Ultralytics or its authorized delegates ..
|
||||
|
||||
**Disputes.** This Agreement shall be governed by and construed in accordance with the laws of the State of
|
||||
New York, United States of America, without giving effect to its principles or rules regarding conflicts of laws,
|
||||
other than such principles directing application of New York law. The parties hereby submit to venue in, and
|
||||
jurisdiction of the courts located in New York, New York for purposes relating to this Agreement. In the event
|
||||
that any of the provisions of this Agreement shall be held by a court or other tribunal of competent jurisdiction
|
||||
to be unenforceable, the remaining portions hereof shall remain in full force and effect.
|
||||
|
||||
**Assignment.** You agree that Ultralytics may assign this Agreement, and all of its rights, obligations and licenses
|
||||
hereunder.
|
||||
38
docs/help/FAQ.md
Normal file
38
docs/help/FAQ.md
Normal file
@ -0,0 +1,38 @@
|
||||
---
|
||||
comments: true
|
||||
description: 'Get quick answers to common Ultralytics YOLO questions: Hardware requirements, fine-tuning, conversion, real-time detection, and accuracy tips.'
|
||||
---
|
||||
|
||||
# Ultralytics YOLO Frequently Asked Questions (FAQ)
|
||||
|
||||
This FAQ section addresses some common questions and issues users might encounter while working with Ultralytics YOLO repositories.
|
||||
|
||||
## 1. What are the hardware requirements for running Ultralytics YOLO?
|
||||
|
||||
Ultralytics YOLO can be run on a variety of hardware configurations, including CPUs, GPUs, and even some edge devices. However, for optimal performance and faster training and inference, we recommend using a GPU with a minimum of 8GB of memory. NVIDIA GPUs with CUDA support are ideal for this purpose.
|
||||
|
||||
## 2. How do I fine-tune a pre-trained YOLO model on my custom dataset?
|
||||
|
||||
To fine-tune a pre-trained YOLO model on your custom dataset, you'll need to create a dataset configuration file (YAML) that defines the dataset's properties, such as the path to the images, the number of classes, and class names. Next, you'll need to modify the model configuration file to match the number of classes in your dataset. Finally, use the `train.py` script to start the training process with your custom dataset and the pre-trained model. You can find a detailed guide on fine-tuning YOLO in the Ultralytics documentation.
|
||||
|
||||
## 3. How do I convert a YOLO model to ONNX or TensorFlow format?
|
||||
|
||||
Ultralytics provides built-in support for converting YOLO models to ONNX format. You can use the `export.py` script to convert a saved model to ONNX format. If you need to convert the model to TensorFlow format, you can use the ONNX model as an intermediary and then use the ONNX-TensorFlow converter to convert the ONNX model to TensorFlow format.
|
||||
|
||||
## 4. Can I use Ultralytics YOLO for real-time object detection?
|
||||
|
||||
Yes, Ultralytics YOLO is designed to be efficient and fast, making it suitable for real-time object detection tasks. The actual performance will depend on your hardware configuration and the complexity of the model. Using a GPU and optimizing the model for your specific use case can help achieve real-time performance.
|
||||
|
||||
## 5. How can I improve the accuracy of my YOLO model?
|
||||
|
||||
Improving the accuracy of a YOLO model may involve several strategies, such as:
|
||||
|
||||
- Fine-tuning the model on more annotated data
|
||||
- Data augmentation to increase the variety of training samples
|
||||
- Using a larger or more complex model architecture
|
||||
- Adjusting the learning rate, batch size, and other hyperparameters
|
||||
- Using techniques like transfer learning or knowledge distillation
|
||||
|
||||
Remember that there's often a trade-off between accuracy and inference speed, so finding the right balance is crucial for your specific application.
|
||||
|
||||
If you have any more questions or need assistance, don't hesitate to consult the Ultralytics documentation or reach out to the community through GitHub Issues or the official discussion forum.
|
||||
133
docs/help/code_of_conduct.md
Normal file
133
docs/help/code_of_conduct.md
Normal file
@ -0,0 +1,133 @@
|
||||
---
|
||||
comments: true
|
||||
description: Read the Ultralytics Contributor Covenant Code of Conduct. Learn ways to create a welcoming community & consequences for inappropriate conduct.
|
||||
---
|
||||
|
||||
# Ultralytics Contributor Covenant Code of Conduct
|
||||
|
||||
## Our Pledge
|
||||
|
||||
We as members, contributors, and leaders pledge to make participation in our
|
||||
community a harassment-free experience for everyone, regardless of age, body
|
||||
size, visible or invisible disability, ethnicity, sex characteristics, gender
|
||||
identity and expression, level of experience, education, socio-economic status,
|
||||
nationality, personal appearance, race, religion, or sexual identity
|
||||
and orientation.
|
||||
|
||||
We pledge to act and interact in ways that contribute to an open, welcoming,
|
||||
diverse, inclusive, and healthy community.
|
||||
|
||||
## Our Standards
|
||||
|
||||
Examples of behavior that contributes to a positive environment for our
|
||||
community include:
|
||||
|
||||
- Demonstrating empathy and kindness toward other people
|
||||
- Being respectful of differing opinions, viewpoints, and experiences
|
||||
- Giving and gracefully accepting constructive feedback
|
||||
- Accepting responsibility and apologizing to those affected by our mistakes,
|
||||
and learning from the experience
|
||||
- Focusing on what is best not just for us as individuals, but for the
|
||||
overall community
|
||||
|
||||
Examples of unacceptable behavior include:
|
||||
|
||||
- The use of sexualized language or imagery, and sexual attention or
|
||||
advances of any kind
|
||||
- Trolling, insulting or derogatory comments, and personal or political attacks
|
||||
- Public or private harassment
|
||||
- Publishing others' private information, such as a physical or email
|
||||
address, without their explicit permission
|
||||
- Other conduct which could reasonably be considered inappropriate in a
|
||||
professional setting
|
||||
|
||||
## Enforcement Responsibilities
|
||||
|
||||
Community leaders are responsible for clarifying and enforcing our standards of
|
||||
acceptable behavior and will take appropriate and fair corrective action in
|
||||
response to any behavior that they deem inappropriate, threatening, offensive,
|
||||
or harmful.
|
||||
|
||||
Community leaders have the right and responsibility to remove, edit, or reject
|
||||
comments, commits, code, wiki edits, issues, and other contributions that are
|
||||
not aligned to this Code of Conduct, and will communicate reasons for moderation
|
||||
decisions when appropriate.
|
||||
|
||||
## Scope
|
||||
|
||||
This Code of Conduct applies within all community spaces, and also applies when
|
||||
an individual is officially representing the community in public spaces.
|
||||
Examples of representing our community include using an official e-mail address,
|
||||
posting via an official social media account, or acting as an appointed
|
||||
representative at an online or offline event.
|
||||
|
||||
## Enforcement
|
||||
|
||||
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
||||
reported to the community leaders responsible for enforcement at
|
||||
hello@ultralytics.com.
|
||||
All complaints will be reviewed and investigated promptly and fairly.
|
||||
|
||||
All community leaders are obligated to respect the privacy and security of the
|
||||
reporter of any incident.
|
||||
|
||||
## Enforcement Guidelines
|
||||
|
||||
Community leaders will follow these Community Impact Guidelines in determining
|
||||
the consequences for any action they deem in violation of this Code of Conduct:
|
||||
|
||||
### 1. Correction
|
||||
|
||||
**Community Impact**: Use of inappropriate language or other behavior deemed
|
||||
unprofessional or unwelcome in the community.
|
||||
|
||||
**Consequence**: A private, written warning from community leaders, providing
|
||||
clarity around the nature of the violation and an explanation of why the
|
||||
behavior was inappropriate. A public apology may be requested.
|
||||
|
||||
### 2. Warning
|
||||
|
||||
**Community Impact**: A violation through a single incident or series
|
||||
of actions.
|
||||
|
||||
**Consequence**: A warning with consequences for continued behavior. No
|
||||
interaction with the people involved, including unsolicited interaction with
|
||||
those enforcing the Code of Conduct, for a specified period of time. This
|
||||
includes avoiding interactions in community spaces as well as external channels
|
||||
like social media. Violating these terms may lead to a temporary or
|
||||
permanent ban.
|
||||
|
||||
### 3. Temporary Ban
|
||||
|
||||
**Community Impact**: A serious violation of community standards, including
|
||||
sustained inappropriate behavior.
|
||||
|
||||
**Consequence**: A temporary ban from any sort of interaction or public
|
||||
communication with the community for a specified period of time. No public or
|
||||
private interaction with the people involved, including unsolicited interaction
|
||||
with those enforcing the Code of Conduct, is allowed during this period.
|
||||
Violating these terms may lead to a permanent ban.
|
||||
|
||||
### 4. Permanent Ban
|
||||
|
||||
**Community Impact**: Demonstrating a pattern of violation of community
|
||||
standards, including sustained inappropriate behavior, harassment of an
|
||||
individual, or aggression toward or disparagement of classes of individuals.
|
||||
|
||||
**Consequence**: A permanent ban from any sort of public interaction within
|
||||
the community.
|
||||
|
||||
## Attribution
|
||||
|
||||
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
|
||||
version 2.0, available at
|
||||
https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
|
||||
|
||||
Community Impact Guidelines were inspired by [Mozilla's code of conduct
|
||||
enforcement ladder](https://github.com/mozilla/diversity).
|
||||
|
||||
For answers to common questions about this code of conduct, see the FAQ at
|
||||
https://www.contributor-covenant.org/faq. Translations are available at
|
||||
https://www.contributor-covenant.org/translations.
|
||||
|
||||
[homepage]: https://www.contributor-covenant.org
|
||||
74
docs/help/contributing.md
Normal file
74
docs/help/contributing.md
Normal file
@ -0,0 +1,74 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to contribute to Ultralytics Open-Source YOLO Repositories with contributions guidelines, pull requests requirements, and GitHub CI tests.
|
||||
---
|
||||
|
||||
# Contributing to Ultralytics Open-Source YOLO Repositories
|
||||
|
||||
First of all, thank you for your interest in contributing to Ultralytics open-source YOLO repositories! Your contributions will help improve the project and benefit the community. This document provides guidelines and best practices for contributing to Ultralytics YOLO repositories.
|
||||
|
||||
## Table of Contents
|
||||
|
||||
- [Code of Conduct](#code-of-conduct)
|
||||
- [Pull Requests](#pull-requests)
|
||||
- [CLA Signing](#cla-signing)
|
||||
- [Google-Style Docstrings](#google-style-docstrings)
|
||||
- [GitHub Actions CI Tests](#github-actions-ci-tests)
|
||||
- [Bug Reports](#bug-reports)
|
||||
- [Minimum Reproducible Example](#minimum-reproducible-example)
|
||||
- [License and Copyright](#license-and-copyright)
|
||||
|
||||
## Code of Conduct
|
||||
|
||||
All contributors are expected to adhere to the [Code of Conduct](code_of_conduct.md) to ensure a welcoming and inclusive environment for everyone.
|
||||
|
||||
## Pull Requests
|
||||
|
||||
We welcome contributions in the form of pull requests. To make the review process smoother, please follow these guidelines:
|
||||
|
||||
1. **Fork the repository**: Fork the Ultralytics YOLO repository to your own GitHub account.
|
||||
|
||||
2. **Create a branch**: Create a new branch in your forked repository with a descriptive name for your changes.
|
||||
|
||||
3. **Make your changes**: Make the changes you want to contribute. Ensure that your changes follow the coding style of the project and do not introduce new errors or warnings.
|
||||
|
||||
4. **Test your changes**: Test your changes locally to ensure that they work as expected and do not introduce new issues.
|
||||
|
||||
5. **Commit your changes**: Commit your changes with a descriptive commit message. Make sure to include any relevant issue numbers in your commit message.
|
||||
|
||||
6. **Create a pull request**: Create a pull request from your forked repository to the main Ultralytics YOLO repository. In the pull request description, provide a clear explanation of your changes and how they improve the project.
|
||||
|
||||
### CLA Signing
|
||||
|
||||
Before we can accept your pull request, you need to sign a [Contributor License Agreement (CLA)](CLA.md). This is a legal document stating that you agree to the terms of contributing to the Ultralytics YOLO repositories. The CLA ensures that your contributions are properly licensed and that the project can continue to be distributed under the AGPL-3.0 license.
|
||||
|
||||
To sign the CLA, follow the instructions provided by the CLA bot after you submit your PR.
|
||||
|
||||
### Google-Style Docstrings
|
||||
|
||||
When adding new functions or classes, please include a [Google-style docstring](https://google.github.io/styleguide/pyguide.html) to provide clear and concise documentation for other developers. This will help ensure that your contributions are easy to understand and maintain.
|
||||
|
||||
Example Google-style docstring:
|
||||
|
||||
```python
|
||||
def example_function(arg1: int, arg2: str) -> bool:
|
||||
"""Example function that demonstrates Google-style docstrings.
|
||||
|
||||
Args:
|
||||
arg1 (int): The first argument.
|
||||
arg2 (str): The second argument.
|
||||
|
||||
Returns:
|
||||
bool: True if successful, False otherwise.
|
||||
|
||||
Raises:
|
||||
ValueError: If `arg1` is negative or `arg2` is empty.
|
||||
"""
|
||||
if arg1 < 0 or not arg2:
|
||||
raise ValueError("Invalid input values")
|
||||
return True
|
||||
```
|
||||
|
||||
### GitHub Actions CI Tests
|
||||
|
||||
Before your pull request can be merged, all GitHub Actions Continuous Integration (CI) tests must pass. These tests include linting, unit tests, and other checks to ensure that your changes meet the quality standards of the project. Make sure to review the output of the GitHub Actions and fix any issues
|
||||
15
docs/help/index.md
Normal file
15
docs/help/index.md
Normal file
@ -0,0 +1,15 @@
|
||||
---
|
||||
comments: true
|
||||
description: Get comprehensive resources for Ultralytics YOLO repositories. Find guides, FAQs, MRE creation, CLA & more. Join the supportive community now!
|
||||
---
|
||||
|
||||
Welcome to the Ultralytics Help page! We are committed to providing you with comprehensive resources to make your experience with Ultralytics YOLO repositories as smooth and enjoyable as possible. On this page, you'll find essential links to guides and documents that will help you navigate through common tasks and address any questions you might have while using our repositories.
|
||||
|
||||
- [Frequently Asked Questions (FAQ)](FAQ.md): Find answers to common questions and issues faced by users and contributors of Ultralytics YOLO repositories.
|
||||
- [Contributing Guide](contributing.md): Learn the best practices for submitting pull requests, reporting bugs, and contributing to the development of our repositories.
|
||||
- [Contributor License Agreement (CLA)](CLA.md): Familiarize yourself with our CLA to understand the terms and conditions for contributing to Ultralytics projects.
|
||||
- [Minimum Reproducible Example (MRE) Guide](minimum_reproducible_example.md): Understand how to create an MRE when submitting bug reports to ensure that our team can quickly and efficiently address the issue.
|
||||
- [Code of Conduct](code_of_conduct.md): Learn about our community guidelines and expectations to ensure a welcoming and inclusive environment for all participants.
|
||||
- [Security Policy](../SECURITY.md): Understand our security practices and how to report security vulnerabilities responsibly.
|
||||
|
||||
We highly recommend going through these guides to make the most of your collaboration with the Ultralytics community. Our goal is to maintain a welcoming and supportive environment for all users and contributors. If you need further assistance, don't hesitate to reach out to us through GitHub Issues or the official discussion forum. Happy coding!
|
||||
77
docs/help/minimum_reproducible_example.md
Normal file
77
docs/help/minimum_reproducible_example.md
Normal file
@ -0,0 +1,77 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to create a Minimum Reproducible Example (MRE) for Ultralytics YOLO bug reports to help maintainers and contributors understand your issue better.
|
||||
---
|
||||
|
||||
# Creating a Minimum Reproducible Example for Bug Reports in Ultralytics YOLO Repositories
|
||||
|
||||
When submitting a bug report for Ultralytics YOLO repositories, it's essential to provide a [minimum reproducible example](https://stackoverflow.com/help/minimal-reproducible-example) (MRE). An MRE is a small, self-contained piece of code that demonstrates the problem you're experiencing. Providing an MRE helps maintainers and contributors understand the issue and work on a fix more efficiently. This guide explains how to create an MRE when submitting bug reports to Ultralytics YOLO repositories.
|
||||
|
||||
## 1. Isolate the Problem
|
||||
|
||||
The first step in creating an MRE is to isolate the problem. This means removing any unnecessary code or dependencies that are not directly related to the issue. Focus on the specific part of the code that is causing the problem and remove any irrelevant code.
|
||||
|
||||
## 2. Use Public Models and Datasets
|
||||
|
||||
When creating an MRE, use publicly available models and datasets to reproduce the issue. For example, use the 'yolov8n.pt' model and the 'coco8.yaml' dataset. This ensures that the maintainers and contributors can easily run your example and investigate the problem without needing access to proprietary data or custom models.
|
||||
|
||||
## 3. Include All Necessary Dependencies
|
||||
|
||||
Make sure to include all the necessary dependencies in your MRE. If your code relies on external libraries, specify the required packages and their versions. Ideally, provide a `requirements.txt` file or list the dependencies in your bug report.
|
||||
|
||||
## 4. Write a Clear Description of the Issue
|
||||
|
||||
Provide a clear and concise description of the issue you're experiencing. Explain the expected behavior and the actual behavior you're encountering. If applicable, include any relevant error messages or logs.
|
||||
|
||||
## 5. Format Your Code Properly
|
||||
|
||||
When submitting an MRE, format your code properly using code blocks in the issue description. This makes it easier for others to read and understand your code. In GitHub, you can create a code block by wrapping your code with triple backticks (\```) and specifying the language:
|
||||
|
||||
<pre>
|
||||
```python
|
||||
# Your Python code goes here
|
||||
```
|
||||
</pre>
|
||||
|
||||
## 6. Test Your MRE
|
||||
|
||||
Before submitting your MRE, test it to ensure that it accurately reproduces the issue. Make sure that others can run your example without any issues or modifications.
|
||||
|
||||
## Example of an MRE
|
||||
|
||||
Here's an example of an MRE for a hypothetical bug report:
|
||||
|
||||
**Bug description:**
|
||||
|
||||
When running the `detect.py` script on the sample image from the 'coco8.yaml' dataset, I get an error related to the dimensions of the input tensor.
|
||||
|
||||
**MRE:**
|
||||
|
||||
```python
|
||||
import torch
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load the model
|
||||
model = YOLO("yolov8n.pt")
|
||||
|
||||
# Load a 0-channel image
|
||||
image = torch.rand(1, 0, 640, 640)
|
||||
|
||||
# Run the model
|
||||
results = model(image)
|
||||
```
|
||||
|
||||
**Error message:**
|
||||
|
||||
```
|
||||
RuntimeError: Expected input[1, 0, 640, 640] to have 3 channels, but got 0 channels instead
|
||||
```
|
||||
|
||||
**Dependencies:**
|
||||
|
||||
- torch==2.0.0
|
||||
- ultralytics==8.0.90
|
||||
|
||||
In this example, the MRE demonstrates the issue with a minimal amount of code, uses a public model ('yolov8n.pt'), includes all necessary dependencies, and provides a clear description of the problem along with the error message.
|
||||
|
||||
By following these guidelines, you'll help the maintainers and contributors of Ultralytics YOLO repositories to understand and resolve your issue more efficiently.
|
||||
65
docs/hub/app/android.md
Normal file
65
docs/hub/app/android.md
Normal file
@ -0,0 +1,65 @@
|
||||
---
|
||||
comments: true
|
||||
description: Run YOLO models on your Android device for real-time object detection with Ultralytics Android App. Utilizes TensorFlow Lite and hardware delegates.
|
||||
---
|
||||
|
||||
# Ultralytics Android App: Real-time Object Detection with YOLO Models
|
||||
|
||||
The Ultralytics Android App is a powerful tool that allows you to run YOLO models directly on your Android device for real-time object detection. This app utilizes TensorFlow Lite for model optimization and various hardware delegates for acceleration, enabling fast and efficient object detection.
|
||||
|
||||
## Quantization and Acceleration
|
||||
|
||||
To achieve real-time performance on your Android device, YOLO models are quantized to either FP16 or INT8 precision. Quantization is a process that reduces the numerical precision of the model's weights and biases, thus reducing the model's size and the amount of computation required. This results in faster inference times without significantly affecting the model's accuracy.
|
||||
|
||||
### FP16 Quantization
|
||||
|
||||
FP16 (or half-precision) quantization converts the model's 32-bit floating-point numbers to 16-bit floating-point numbers. This reduces the model's size by half and speeds up the inference process, while maintaining a good balance between accuracy and performance.
|
||||
|
||||
### INT8 Quantization
|
||||
|
||||
INT8 (or 8-bit integer) quantization further reduces the model's size and computation requirements by converting its 32-bit floating-point numbers to 8-bit integers. This quantization method can result in a significant speedup, but it may lead to a slight reduction in mean average precision (mAP) due to the lower numerical precision.
|
||||
|
||||
!!! tip "mAP Reduction in INT8 Models"
|
||||
|
||||
The reduced numerical precision in INT8 models can lead to some loss of information during the quantization process, which may result in a slight decrease in mAP. However, this trade-off is often acceptable considering the substantial performance gains offered by INT8 quantization.
|
||||
|
||||
## Delegates and Performance Variability
|
||||
|
||||
Different delegates are available on Android devices to accelerate model inference. These delegates include CPU, [GPU](https://www.tensorflow.org/lite/android/delegates/gpu), [Hexagon](https://www.tensorflow.org/lite/android/delegates/hexagon) and [NNAPI](https://www.tensorflow.org/lite/android/delegates/nnapi). The performance of these delegates varies depending on the device's hardware vendor, product line, and specific chipsets used in the device.
|
||||
|
||||
1. **CPU**: The default option, with reasonable performance on most devices.
|
||||
2. **GPU**: Utilizes the device's GPU for faster inference. It can provide a significant performance boost on devices with powerful GPUs.
|
||||
3. **Hexagon**: Leverages Qualcomm's Hexagon DSP for faster and more efficient processing. This option is available on devices with Qualcomm Snapdragon processors.
|
||||
4. **NNAPI**: The Android Neural Networks API (NNAPI) serves as an abstraction layer for running ML models on Android devices. NNAPI can utilize various hardware accelerators, such as CPU, GPU, and dedicated AI chips (e.g., Google's Edge TPU, or the Pixel Neural Core).
|
||||
|
||||
Here's a table showing the primary vendors, their product lines, popular devices, and supported delegates:
|
||||
|
||||
| Vendor | Product Lines | Popular Devices | Delegates Supported |
|
||||
|-----------------------------------------|---------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------|
|
||||
| [Qualcomm](https://www.qualcomm.com/) | [Snapdragon (e.g., 800 series)](https://www.qualcomm.com/snapdragon) | [Samsung Galaxy S21](https://www.samsung.com/global/galaxy/galaxy-s21-5g/), [OnePlus 9](https://www.oneplus.com/9), [Google Pixel 6](https://store.google.com/product/pixel_6) | CPU, GPU, Hexagon, NNAPI |
|
||||
| [Samsung](https://www.samsung.com/) | [Exynos (e.g., Exynos 2100)](https://www.samsung.com/semiconductor/minisite/exynos/) | [Samsung Galaxy S21 (Global version)](https://www.samsung.com/global/galaxy/galaxy-s21-5g/) | CPU, GPU, NNAPI |
|
||||
| [MediaTek](https://www.mediatek.com/) | [Dimensity (e.g., Dimensity 1200)](https://www.mediatek.com/products/smartphones) | [Realme GT](https://www.realme.com/global/realme-gt), [Xiaomi Redmi Note](https://www.mi.com/en/phone/redmi/note-list) | CPU, GPU, NNAPI |
|
||||
| [HiSilicon](https://www.hisilicon.com/) | [Kirin (e.g., Kirin 990)](https://www.hisilicon.com/en/products/Kirin) | [Huawei P40 Pro](https://consumer.huawei.com/en/phones/p40-pro/), [Huawei Mate 30 Pro](https://consumer.huawei.com/en/phones/mate30-pro/) | CPU, GPU, NNAPI |
|
||||
| [NVIDIA](https://www.nvidia.com/) | [Tegra (e.g., Tegra X1)](https://www.nvidia.com/en-us/autonomous-machines/embedded-systems-dev-kits-modules/) | [NVIDIA Shield TV](https://www.nvidia.com/en-us/shield/shield-tv/), [Nintendo Switch](https://www.nintendo.com/switch/) | CPU, GPU, NNAPI |
|
||||
|
||||
Please note that the list of devices mentioned is not exhaustive and may vary depending on the specific chipsets and device models. Always test your models on your target devices to ensure compatibility and optimal performance.
|
||||
|
||||
Keep in mind that the choice of delegate can affect performance and model compatibility. For example, some models may not work with certain delegates, or a delegate may not be available on a specific device. As such, it's essential to test your model and the chosen delegate on your target devices for the best results.
|
||||
|
||||
## Getting Started with the Ultralytics Android App
|
||||
|
||||
To get started with the Ultralytics Android App, follow these steps:
|
||||
|
||||
1. Download the Ultralytics App from the [Google Play Store](https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app).
|
||||
|
||||
2. Launch the app on your Android device and sign in with your Ultralytics account. If you don't have an account yet, create one [here](https://hub.ultralytics.com/).
|
||||
|
||||
3. Once signed in, you will see a list of your trained YOLO models. Select a model to use for object detection.
|
||||
|
||||
4. Grant the app permission to access your device's camera.
|
||||
|
||||
5. Point your device's camera at objects you want to detect. The app will display bounding boxes and class labels in real-time as it detects objects.
|
||||
|
||||
6. Explore the app's settings to adjust the detection threshold, enable or disable specific object classes, and more.
|
||||
|
||||
With the Ultralytics Android App, you now have the power of real-time object detection using YOLO models right at your fingertips. Enjoy exploring the app's features and optimizing its settings to suit your specific use cases.
|
||||
51
docs/hub/app/index.md
Normal file
51
docs/hub/app/index.md
Normal file
@ -0,0 +1,51 @@
|
||||
---
|
||||
comments: true
|
||||
description: Experience the power of YOLOv5 and YOLOv8 models with Ultralytics HUB app. Download from Google Play and App Store now.
|
||||
---
|
||||
|
||||
# Ultralytics HUB App
|
||||
|
||||
<a href="https://bit.ly/ultralytics_hub" target="_blank">
|
||||
<img width="100%" src="https://github.com/ultralytics/assets/raw/main/im/ultralytics-hub.png"></a>
|
||||
<br>
|
||||
<div align="center">
|
||||
<a href="https://github.com/ultralytics" style="text-decoration:none;">
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-github.png" width="2%" alt="" /></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%" alt="" />
|
||||
<a href="https://www.linkedin.com/company/ultralytics" style="text-decoration:none;">
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-linkedin.png" width="2%" alt="" /></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%" alt="" />
|
||||
<a href="https://twitter.com/ultralytics" style="text-decoration:none;">
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-twitter.png" width="2%" alt="" /></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%" alt="" />
|
||||
<a href="https://youtube.com/ultralytics" style="text-decoration:none;">
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-youtube.png" width="2%" alt="" /></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%" alt="" />
|
||||
<a href="https://www.tiktok.com/@ultralytics" style="text-decoration:none;">
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-tiktok.png" width="2%" alt="" /></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%" alt="" />
|
||||
<a href="https://www.instagram.com/ultralytics/" style="text-decoration:none;">
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-instagram.png" width="2%" alt="" /></a>
|
||||
<br>
|
||||
<br>
|
||||
<a href="https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app" style="text-decoration:none;">
|
||||
<img src="https://raw.githubusercontent.com/ultralytics/assets/master/app/google-play.svg" width="15%" alt="" /></a>
|
||||
<a href="https://apps.apple.com/xk/app/ultralytics/id1583935240" style="text-decoration:none;">
|
||||
<img src="https://raw.githubusercontent.com/ultralytics/assets/master/app/app-store.svg" width="15%" alt="" /></a>
|
||||
</div>
|
||||
|
||||
Welcome to the Ultralytics HUB App! We are excited to introduce this powerful mobile app that allows you to run YOLOv5 and YOLOv8 models directly on your [iOS](https://apps.apple.com/xk/app/ultralytics/id1583935240) and [Android](https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app) devices. With the HUB App, you can utilize hardware acceleration features like Apple's Neural Engine (ANE) or Android GPU and Neural Network API (NNAPI) delegates to achieve impressive performance on your mobile device.
|
||||
|
||||
## Features
|
||||
|
||||
- **Run YOLOv5 and YOLOv8 models**: Experience the power of YOLO models on your mobile device for real-time object detection and image recognition tasks.
|
||||
- **Hardware Acceleration**: Benefit from Apple ANE on iOS devices or Android GPU and NNAPI delegates for optimized performance.
|
||||
- **Custom Model Training**: Train custom models with the Ultralytics HUB platform and preview them live using the HUB App.
|
||||
- **Mobile Compatibility**: The HUB App supports both iOS and Android devices, bringing the power of YOLO models to a wide range of users.
|
||||
|
||||
## App Documentation
|
||||
|
||||
- [**iOS**](./ios.md): Learn about YOLO CoreML models accelerated on Apple's Neural Engine for iPhones and iPads.
|
||||
- [**Android**](./android.md): Explore TFLite acceleration on Android mobile devices.
|
||||
|
||||
Get started today by downloading the Ultralytics HUB App on your mobile device and unlock the potential of YOLOv5 and YOLOv8 models on-the-go. Don't forget to check out our comprehensive [HUB Docs](../) for more information on training, deploying, and using your custom models with the Ultralytics HUB platform.
|
||||
55
docs/hub/app/ios.md
Normal file
55
docs/hub/app/ios.md
Normal file
@ -0,0 +1,55 @@
|
||||
---
|
||||
comments: true
|
||||
description: Get started with the Ultralytics iOS app and run YOLO models in real-time for object detection on your iPhone or iPad with the Apple Neural Engine.
|
||||
---
|
||||
|
||||
# Ultralytics iOS App: Real-time Object Detection with YOLO Models
|
||||
|
||||
The Ultralytics iOS App is a powerful tool that allows you to run YOLO models directly on your iPhone or iPad for real-time object detection. This app utilizes the Apple Neural Engine and Core ML for model optimization and acceleration, enabling fast and efficient object detection.
|
||||
|
||||
## Quantization and Acceleration
|
||||
|
||||
To achieve real-time performance on your iOS device, YOLO models are quantized to either FP16 or INT8 precision. Quantization is a process that reduces the numerical precision of the model's weights and biases, thus reducing the model's size and the amount of computation required. This results in faster inference times without significantly affecting the model's accuracy.
|
||||
|
||||
### FP16 Quantization
|
||||
|
||||
FP16 (or half-precision) quantization converts the model's 32-bit floating-point numbers to 16-bit floating-point numbers. This reduces the model's size by half and speeds up the inference process, while maintaining a good balance between accuracy and performance.
|
||||
|
||||
### INT8 Quantization
|
||||
|
||||
INT8 (or 8-bit integer) quantization further reduces the model's size and computation requirements by converting its 32-bit floating-point numbers to 8-bit integers. This quantization method can result in a significant speedup, but it may lead to a slight reduction in accuracy.
|
||||
|
||||
## Apple Neural Engine
|
||||
|
||||
The Apple Neural Engine (ANE) is a dedicated hardware component integrated into Apple's A-series and M-series chips. It's designed to accelerate machine learning tasks, particularly for neural networks, allowing for faster and more efficient execution of your YOLO models.
|
||||
|
||||
By combining quantized YOLO models with the Apple Neural Engine, the Ultralytics iOS App achieves real-time object detection on your iOS device without compromising on accuracy or performance.
|
||||
|
||||
| Release Year | iPhone Name | Chipset Name | Node Size | ANE TOPs |
|
||||
|--------------|------------------------------------------------------|-------------------------------------------------------|-----------|----------|
|
||||
| 2017 | [iPhone X](https://en.wikipedia.org/wiki/IPhone_X) | [A11 Bionic](https://en.wikipedia.org/wiki/Apple_A11) | 10 nm | 0.6 |
|
||||
| 2018 | [iPhone XS](https://en.wikipedia.org/wiki/IPhone_XS) | [A12 Bionic](https://en.wikipedia.org/wiki/Apple_A12) | 7 nm | 5 |
|
||||
| 2019 | [iPhone 11](https://en.wikipedia.org/wiki/IPhone_11) | [A13 Bionic](https://en.wikipedia.org/wiki/Apple_A13) | 7 nm | 6 |
|
||||
| 2020 | [iPhone 12](https://en.wikipedia.org/wiki/IPhone_12) | [A14 Bionic](https://en.wikipedia.org/wiki/Apple_A14) | 5 nm | 11 |
|
||||
| 2021 | [iPhone 13](https://en.wikipedia.org/wiki/IPhone_13) | [A15 Bionic](https://en.wikipedia.org/wiki/Apple_A15) | 5 nm | 15.8 |
|
||||
| 2022 | [iPhone 14](https://en.wikipedia.org/wiki/IPhone_14) | [A16 Bionic](https://en.wikipedia.org/wiki/Apple_A16) | 4 nm | 17.0 |
|
||||
|
||||
Please note that this list only includes iPhone models from 2017 onwards, and the ANE TOPs values are approximate.
|
||||
|
||||
## Getting Started with the Ultralytics iOS App
|
||||
|
||||
To get started with the Ultralytics iOS App, follow these steps:
|
||||
|
||||
1. Download the Ultralytics App from the [App Store](https://apps.apple.com/xk/app/ultralytics/id1583935240).
|
||||
|
||||
2. Launch the app on your iOS device and sign in with your Ultralytics account. If you don't have an account yet, create one [here](https://hub.ultralytics.com/).
|
||||
|
||||
3. Once signed in, you will see a list of your trained YOLO models. Select a model to use for object detection.
|
||||
|
||||
4. Grant the app permission to access your device's camera.
|
||||
|
||||
5. Point your device's camera at objects you want to detect. The app will display bounding boxes and class labels in real-time as it detects objects.
|
||||
|
||||
6. Explore the app's settings to adjust the detection threshold, enable or disable specific object classes, and more.
|
||||
|
||||
With the Ultralytics iOS App, you can now leverage the power of YOLO models for real-time object detection on your iPhone or iPad, powered by the Apple Neural Engine and optimized with FP16 or INT8 quantization.
|
||||
50
docs/hub/datasets.md
Normal file
50
docs/hub/datasets.md
Normal file
@ -0,0 +1,50 @@
|
||||
---
|
||||
comments: true
|
||||
description: Upload custom datasets to Ultralytics HUB for YOLOv5 and YOLOv8 models. Follow YAML structure, zip and upload. Scan & train new models.
|
||||
---
|
||||
|
||||
# HUB Datasets
|
||||
|
||||
## 1. Upload a Dataset
|
||||
|
||||
Ultralytics HUB datasets are just like YOLOv5 and YOLOv8 🚀 datasets, they use the same structure and the same label formats to keep
|
||||
everything simple.
|
||||
|
||||
When you upload a dataset to Ultralytics HUB, make sure to **place your dataset YAML inside the dataset root directory**
|
||||
as in the example shown below, and then zip for upload to [https://hub.ultralytics.com](https://hub.ultralytics.com/). Your **dataset YAML, directory
|
||||
and zip** should all share the same name. For example, if your dataset is called 'coco8' as in our
|
||||
example [ultralytics/hub/example_datasets/coco8.zip](https://github.com/ultralytics/hub/blob/master/example_datasets/coco8.zip), then you should have a `coco8.yaml` inside your `coco8/` directory, which should zip to create `coco8.zip` for upload:
|
||||
|
||||
```bash
|
||||
zip -r coco8.zip coco8
|
||||
```
|
||||
|
||||
The [example_datasets/coco8.zip](https://github.com/ultralytics/hub/blob/master/example_datasets/coco8.zip) dataset in this repository can be downloaded and unzipped to see exactly how to structure your custom dataset.
|
||||
|
||||
<p align="center">
|
||||
<img width="80%" src="https://user-images.githubusercontent.com/26833433/201424843-20fa081b-ad4b-4d6c-a095-e810775908d8.png" title="COCO8" />
|
||||
</p>
|
||||
|
||||
The dataset YAML is the same standard YOLOv5 and YOLOv8 YAML format. See
|
||||
the [YOLOv5 and YOLOv8 Train Custom Data tutorial](https://docs.ultralytics.com/yolov5/tutorials/train_custom_data/) for full details.
|
||||
|
||||
```yaml
|
||||
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
||||
path: # dataset root dir (leave empty for HUB)
|
||||
train: images/train # train images (relative to 'path') 8 images
|
||||
val: images/val # val images (relative to 'path') 8 images
|
||||
test: # test images (optional)
|
||||
|
||||
# Classes
|
||||
names:
|
||||
0: person
|
||||
1: bicycle
|
||||
2: car
|
||||
3: motorcycle
|
||||
...
|
||||
```
|
||||
|
||||
After zipping your dataset, sign in to [Ultralytics HUB](https://bit.ly/ultralytics_hub) and click the Datasets tab.
|
||||
Click 'Upload Dataset' to upload, scan and visualize your new dataset before training new YOLOv5 or YOLOv8 models on it!
|
||||
|
||||
<img width="100%" alt="HUB Dataset Upload" src="https://user-images.githubusercontent.com/26833433/216763338-9a8812c8-a4e5-4362-8102-40dad7818396.png">
|
||||
41
docs/hub/index.md
Normal file
41
docs/hub/index.md
Normal file
@ -0,0 +1,41 @@
|
||||
---
|
||||
comments: true
|
||||
description: 'Ultralytics HUB: Train & deploy YOLO models from one spot! Use drag-and-drop interface with templates & pre-training models. Check quickstart, datasets, and more.'
|
||||
---
|
||||
|
||||
# Ultralytics HUB
|
||||
|
||||
<a href="https://bit.ly/ultralytics_hub" target="_blank">
|
||||
<img width="100%" src="https://github.com/ultralytics/assets/raw/main/im/ultralytics-hub.png"></a>
|
||||
<br>
|
||||
<br>
|
||||
<div align="center">
|
||||
<a href="https://github.com/ultralytics/hub/actions/workflows/ci.yaml">
|
||||
<img src="https://github.com/ultralytics/hub/actions/workflows/ci.yaml/badge.svg" alt="CI CPU"></a>
|
||||
<a href="https://colab.research.google.com/github/ultralytics/hub/blob/master/hub.ipynb">
|
||||
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>
|
||||
</div>
|
||||
<br>
|
||||
|
||||
👋 Hello from the [Ultralytics](https://ultralytics.com/) Team! We've been working hard these last few months to
|
||||
launch [Ultralytics HUB](https://bit.ly/ultralytics_hub), a new web tool for training and deploying all your YOLOv5 and YOLOv8 🚀
|
||||
models from one spot!
|
||||
|
||||
## Introduction
|
||||
|
||||
HUB is designed to be user-friendly and intuitive, with a drag-and-drop interface that allows users to
|
||||
easily upload their data and train new models quickly. It offers a range of pre-trained models and
|
||||
templates to choose from, making it easy for users to get started with training their own models. Once a model is
|
||||
trained, it can be easily deployed and used for real-time object detection, instance segmentation and classification tasks.
|
||||
|
||||
We hope that the resources here will help you get the most out of HUB. Please browse the HUB <a href="https://docs.ultralytics.com/hub">Docs</a> for details, raise an issue on <a href="https://github.com/ultralytics/hub/issues/new/choose">GitHub</a> for support, and join our <a href="https://discord.gg/n6cFeSPZdD">Discord</a> community for questions and discussions!
|
||||
|
||||
- [**Quickstart**](./quickstart.md). Start training and deploying YOLO models with HUB in seconds.
|
||||
- [**Datasets: Preparing and Uploading**](./datasets.md). Learn how to prepare and upload your datasets to HUB in YOLO format.
|
||||
- [**Projects: Creating and Managing**](./projects.md). Group your models into projects for improved organization.
|
||||
- [**Models: Training and Exporting**](./models.md). Train YOLOv5 and YOLOv8 models on your custom datasets and export them to various formats for deployment.
|
||||
- [**Integrations: Options**](./integrations.md). Explore different integration options for your trained models, such as TensorFlow, ONNX, OpenVINO, CoreML, and PaddlePaddle.
|
||||
- [**Ultralytics HUB App**](./app/index.md). Learn about the Ultralytics App for iOS and Android, which allows you to run models directly on your mobile device.
|
||||
* [**iOS**](./app/ios.md). Learn about YOLO CoreML models accelerated on Apple's Neural Engine on iPhones and iPads.
|
||||
* [**Android**](./app/android.md). Explore TFLite acceleration on mobile devices.
|
||||
- [**Inference API**](./inference_api.md). Understand how to use the Inference API for running your trained models in the cloud to generate predictions.
|
||||
457
docs/hub/inference_api.md
Normal file
457
docs/hub/inference_api.md
Normal file
@ -0,0 +1,457 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
|
||||
# YOLO Inference API
|
||||
|
||||
The YOLO Inference API allows you to access the YOLOv8 object detection capabilities via a RESTful API. This enables you to run object detection on images without the need to install and set up the YOLOv8 environment locally.
|
||||
|
||||
## API URL
|
||||
|
||||
The API URL is the address used to access the YOLO Inference API. In this case, the base URL is:
|
||||
|
||||
```
|
||||
https://api.ultralytics.com/v1/predict
|
||||
```
|
||||
|
||||
## Example Usage in Python
|
||||
|
||||
To access the YOLO Inference API with the specified model and API key using Python, you can use the following code:
|
||||
|
||||
```python
|
||||
import requests
|
||||
|
||||
# API URL, use actual MODEL_ID
|
||||
url = f"https://api.ultralytics.com/v1/predict/MODEL_ID"
|
||||
|
||||
# Headers, use actual API_KEY
|
||||
headers = {"x-api-key": "API_KEY"}
|
||||
|
||||
# Inference arguments (optional)
|
||||
data = {"size": 640, "confidence": 0.25, "iou": 0.45}
|
||||
|
||||
# Load image and send request
|
||||
with open("path/to/image.jpg", "rb") as image_file:
|
||||
files = {"image": image_file}
|
||||
response = requests.post(url, headers=headers, files=files, data=data)
|
||||
|
||||
print(response.json())
|
||||
```
|
||||
|
||||
In this example, replace `API_KEY` with your actual API key, `MODEL_ID` with the desired model ID, and `path/to/image.jpg` with the path to the image you want to analyze.
|
||||
|
||||
## Example Usage with CLI
|
||||
|
||||
You can use the YOLO Inference API with the command-line interface (CLI) by utilizing the `curl` command. Replace `API_KEY` with your actual API key, `MODEL_ID` with the desired model ID, and `image.jpg` with the path to the image you want to analyze:
|
||||
|
||||
```bash
|
||||
curl -X POST "https://api.ultralytics.com/v1/predict/MODEL_ID" \
|
||||
-H "x-api-key: API_KEY" \
|
||||
-F "image=@/path/to/image.jpg" \
|
||||
-F "size=640" \
|
||||
-F "confidence=0.25" \
|
||||
-F "iou=0.45"
|
||||
```
|
||||
|
||||
## Passing Arguments
|
||||
|
||||
This command sends a POST request to the YOLO Inference API with the specified `MODEL_ID` in the URL and the `API_KEY` in the request `headers`, along with the image file specified by `@path/to/image.jpg`.
|
||||
|
||||
Here's an example of passing the `size`, `confidence`, and `iou` arguments via the API URL using the `requests` library in Python:
|
||||
|
||||
```python
|
||||
import requests
|
||||
|
||||
# API URL, use actual MODEL_ID
|
||||
url = f"https://api.ultralytics.com/v1/predict/MODEL_ID"
|
||||
|
||||
# Headers, use actual API_KEY
|
||||
headers = {"x-api-key": "API_KEY"}
|
||||
|
||||
# Inference arguments (optional)
|
||||
data = {"size": 640, "confidence": 0.25, "iou": 0.45}
|
||||
|
||||
# Load image and send request
|
||||
with open("path/to/image.jpg", "rb") as image_file:
|
||||
files = {"image": image_file}
|
||||
response = requests.post(url, headers=headers, files=files, data=data)
|
||||
|
||||
print(response.json())
|
||||
```
|
||||
|
||||
In this example, the `data` dictionary contains the query arguments `size`, `confidence`, and `iou`, which tells the API to run inference at image size 640 with confidence and IoU thresholds of 0.25 and 0.45.
|
||||
|
||||
This will send the query parameters along with the file in the POST request. See the table below for a full list of available inference arguments.
|
||||
|
||||
| Inference Argument | Default | Type | Notes |
|
||||
|--------------------|---------|---------|------------------------------------------------|
|
||||
| `size` | `640` | `int` | valid range is `32` - `1280` pixels |
|
||||
| `confidence` | `0.25` | `float` | valid range is `0.01` - `1.0` |
|
||||
| `iou` | `0.45` | `float` | valid range is `0.0` - `0.95` |
|
||||
| `url` | `''` | `str` | optional image URL if not image file is passed |
|
||||
| `normalize` | `False` | `bool` | |
|
||||
|
||||
## Return JSON format
|
||||
|
||||
The YOLO Inference API returns a JSON list with the detection results. The format of the JSON list will be the same as the one produced locally by the `results[0].tojson()` command.
|
||||
|
||||
The JSON list contains information about the detected objects, their coordinates, classes, and confidence scores.
|
||||
|
||||
### Detect Model Format
|
||||
|
||||
YOLO detection models, such as `yolov8n.pt`, can return JSON responses from local inference, CLI API inference, and Python API inference. All of these methods produce the same JSON response format.
|
||||
|
||||
!!! example "Detect Model JSON Response"
|
||||
|
||||
=== "Local"
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load model
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Run inference
|
||||
results = model('image.jpg')
|
||||
|
||||
# Print image.jpg results in JSON format
|
||||
print(results[0].tojson())
|
||||
```
|
||||
|
||||
=== "CLI API"
|
||||
```bash
|
||||
curl -X POST "https://api.ultralytics.com/v1/predict/MODEL_ID" \
|
||||
-H "x-api-key: API_KEY" \
|
||||
-F "image=@/path/to/image.jpg" \
|
||||
-F "size=640" \
|
||||
-F "confidence=0.25" \
|
||||
-F "iou=0.45"
|
||||
```
|
||||
|
||||
=== "Python API"
|
||||
```python
|
||||
import requests
|
||||
|
||||
# API URL, use actual MODEL_ID
|
||||
url = f"https://api.ultralytics.com/v1/predict/MODEL_ID"
|
||||
|
||||
# Headers, use actual API_KEY
|
||||
headers = {"x-api-key": "API_KEY"}
|
||||
|
||||
# Inference arguments (optional)
|
||||
data = {"size": 640, "confidence": 0.25, "iou": 0.45}
|
||||
|
||||
# Load image and send request
|
||||
with open("path/to/image.jpg", "rb") as image_file:
|
||||
files = {"image": image_file}
|
||||
response = requests.post(url, headers=headers, files=files, data=data)
|
||||
|
||||
print(response.json())
|
||||
```
|
||||
|
||||
=== "JSON Response"
|
||||
```json
|
||||
{
|
||||
"success": True,
|
||||
"message": "Inference complete.",
|
||||
"data": [
|
||||
{
|
||||
"name": "person",
|
||||
"class": 0,
|
||||
"confidence": 0.8359682559967041,
|
||||
"box": {
|
||||
"x1": 0.08974208831787109,
|
||||
"y1": 0.27418340047200523,
|
||||
"x2": 0.8706787109375,
|
||||
"y2": 0.9887352837456598
|
||||
}
|
||||
},
|
||||
{
|
||||
"name": "person",
|
||||
"class": 0,
|
||||
"confidence": 0.8189555406570435,
|
||||
"box": {
|
||||
"x1": 0.5847355842590332,
|
||||
"y1": 0.05813225640190972,
|
||||
"x2": 0.8930277824401855,
|
||||
"y2": 0.9903111775716146
|
||||
}
|
||||
},
|
||||
{
|
||||
"name": "tie",
|
||||
"class": 27,
|
||||
"confidence": 0.2909725308418274,
|
||||
"box": {
|
||||
"x1": 0.3433395862579346,
|
||||
"y1": 0.6070465511745877,
|
||||
"x2": 0.40964522361755373,
|
||||
"y2": 0.9849439832899306
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### Segment Model Format
|
||||
|
||||
YOLO segmentation models, such as `yolov8n-seg.pt`, can return JSON responses from local inference, CLI API inference, and Python API inference. All of these methods produce the same JSON response format.
|
||||
|
||||
!!! example "Segment Model JSON Response"
|
||||
|
||||
=== "Local"
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load model
|
||||
model = YOLO('yolov8n-seg.pt')
|
||||
|
||||
# Run inference
|
||||
results = model('image.jpg')
|
||||
|
||||
# Print image.jpg results in JSON format
|
||||
print(results[0].tojson())
|
||||
```
|
||||
|
||||
=== "CLI API"
|
||||
```bash
|
||||
curl -X POST "https://api.ultralytics.com/v1/predict/MODEL_ID" \
|
||||
-H "x-api-key: API_KEY" \
|
||||
-F "image=@/path/to/image.jpg" \
|
||||
-F "size=640" \
|
||||
-F "confidence=0.25" \
|
||||
-F "iou=0.45"
|
||||
```
|
||||
|
||||
=== "Python API"
|
||||
```python
|
||||
import requests
|
||||
|
||||
# API URL, use actual MODEL_ID
|
||||
url = f"https://api.ultralytics.com/v1/predict/MODEL_ID"
|
||||
|
||||
# Headers, use actual API_KEY
|
||||
headers = {"x-api-key": "API_KEY"}
|
||||
|
||||
# Inference arguments (optional)
|
||||
data = {"size": 640, "confidence": 0.25, "iou": 0.45}
|
||||
|
||||
# Load image and send request
|
||||
with open("path/to/image.jpg", "rb") as image_file:
|
||||
files = {"image": image_file}
|
||||
response = requests.post(url, headers=headers, files=files, data=data)
|
||||
|
||||
print(response.json())
|
||||
```
|
||||
|
||||
=== "JSON Response"
|
||||
Note `segments` `x` and `y` lengths may vary from one object to another. Larger or more complex objects may have more segment points.
|
||||
```json
|
||||
{
|
||||
"success": True,
|
||||
"message": "Inference complete.",
|
||||
"data": [
|
||||
{
|
||||
"name": "person",
|
||||
"class": 0,
|
||||
"confidence": 0.856913149356842,
|
||||
"box": {
|
||||
"x1": 0.1064866065979004,
|
||||
"y1": 0.2798851860894097,
|
||||
"x2": 0.8738358497619629,
|
||||
"y2": 0.9894873725043403
|
||||
},
|
||||
"segments": {
|
||||
"x": [
|
||||
0.421875,
|
||||
0.4203124940395355,
|
||||
0.41718751192092896
|
||||
...
|
||||
],
|
||||
"y": [
|
||||
0.2888889014720917,
|
||||
0.2916666567325592,
|
||||
0.2916666567325592
|
||||
...
|
||||
]
|
||||
}
|
||||
},
|
||||
{
|
||||
"name": "person",
|
||||
"class": 0,
|
||||
"confidence": 0.8512625694274902,
|
||||
"box": {
|
||||
"x1": 0.5757311820983887,
|
||||
"y1": 0.053943040635850696,
|
||||
"x2": 0.8960096359252929,
|
||||
"y2": 0.985154045952691
|
||||
},
|
||||
"segments": {
|
||||
"x": [
|
||||
0.7515624761581421,
|
||||
0.75,
|
||||
0.7437499761581421
|
||||
...
|
||||
],
|
||||
"y": [
|
||||
0.0555555559694767,
|
||||
0.05833333358168602,
|
||||
0.05833333358168602
|
||||
...
|
||||
]
|
||||
}
|
||||
},
|
||||
{
|
||||
"name": "tie",
|
||||
"class": 27,
|
||||
"confidence": 0.6485961675643921,
|
||||
"box": {
|
||||
"x1": 0.33911995887756347,
|
||||
"y1": 0.6057066175672743,
|
||||
"x2": 0.4081430912017822,
|
||||
"y2": 0.9916408962673611
|
||||
},
|
||||
"segments": {
|
||||
"x": [
|
||||
0.37187498807907104,
|
||||
0.37031251192092896,
|
||||
0.3687500059604645
|
||||
...
|
||||
],
|
||||
"y": [
|
||||
0.6111111044883728,
|
||||
0.6138888597488403,
|
||||
0.6138888597488403
|
||||
...
|
||||
]
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### Pose Model Format
|
||||
|
||||
YOLO pose models, such as `yolov8n-pose.pt`, can return JSON responses from local inference, CLI API inference, and Python API inference. All of these methods produce the same JSON response format.
|
||||
|
||||
!!! example "Pose Model JSON Response"
|
||||
|
||||
=== "Local"
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load model
|
||||
model = YOLO('yolov8n-seg.pt')
|
||||
|
||||
# Run inference
|
||||
results = model('image.jpg')
|
||||
|
||||
# Print image.jpg results in JSON format
|
||||
print(results[0].tojson())
|
||||
```
|
||||
|
||||
=== "CLI API"
|
||||
```bash
|
||||
curl -X POST "https://api.ultralytics.com/v1/predict/MODEL_ID" \
|
||||
-H "x-api-key: API_KEY" \
|
||||
-F "image=@/path/to/image.jpg" \
|
||||
-F "size=640" \
|
||||
-F "confidence=0.25" \
|
||||
-F "iou=0.45"
|
||||
```
|
||||
|
||||
=== "Python API"
|
||||
```python
|
||||
import requests
|
||||
|
||||
# API URL, use actual MODEL_ID
|
||||
url = f"https://api.ultralytics.com/v1/predict/MODEL_ID"
|
||||
|
||||
# Headers, use actual API_KEY
|
||||
headers = {"x-api-key": "API_KEY"}
|
||||
|
||||
# Inference arguments (optional)
|
||||
data = {"size": 640, "confidence": 0.25, "iou": 0.45}
|
||||
|
||||
# Load image and send request
|
||||
with open("path/to/image.jpg", "rb") as image_file:
|
||||
files = {"image": image_file}
|
||||
response = requests.post(url, headers=headers, files=files, data=data)
|
||||
|
||||
print(response.json())
|
||||
```
|
||||
|
||||
=== "JSON Response"
|
||||
Note COCO-keypoints pretrained models will have 17 human keypoints. The `visible` part of the keypoints indicates whether a keypoint is visible or obscured. Obscured keypoints may be outside the image or may not be visible, i.e. a person's eyes facing away from the camera.
|
||||
```json
|
||||
{
|
||||
"success": True,
|
||||
"message": "Inference complete.",
|
||||
"data": [
|
||||
{
|
||||
"name": "person",
|
||||
"class": 0,
|
||||
"confidence": 0.8439509868621826,
|
||||
"box": {
|
||||
"x1": 0.1125,
|
||||
"y1": 0.28194444444444444,
|
||||
"x2": 0.7953125,
|
||||
"y2": 0.9902777777777778
|
||||
},
|
||||
"keypoints": {
|
||||
"x": [
|
||||
0.5058594942092896,
|
||||
0.5103894472122192,
|
||||
0.4920862317085266
|
||||
...
|
||||
],
|
||||
"y": [
|
||||
0.48964157700538635,
|
||||
0.4643048942089081,
|
||||
0.4465252459049225
|
||||
...
|
||||
],
|
||||
"visible": [
|
||||
0.8726999163627625,
|
||||
0.653947651386261,
|
||||
0.9130823612213135
|
||||
...
|
||||
]
|
||||
}
|
||||
},
|
||||
{
|
||||
"name": "person",
|
||||
"class": 0,
|
||||
"confidence": 0.7474289536476135,
|
||||
"box": {
|
||||
"x1": 0.58125,
|
||||
"y1": 0.0625,
|
||||
"x2": 0.8859375,
|
||||
"y2": 0.9888888888888889
|
||||
},
|
||||
"keypoints": {
|
||||
"x": [
|
||||
0.778544008731842,
|
||||
0.7976160049438477,
|
||||
0.7530890107154846
|
||||
...
|
||||
],
|
||||
"y": [
|
||||
0.27595141530036926,
|
||||
0.2378823608160019,
|
||||
0.23644638061523438
|
||||
...
|
||||
],
|
||||
"visible": [
|
||||
0.8900790810585022,
|
||||
0.789978563785553,
|
||||
0.8974530100822449
|
||||
...
|
||||
]
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
7
docs/hub/integrations.md
Normal file
7
docs/hub/integrations.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
20
docs/hub/models.md
Normal file
20
docs/hub/models.md
Normal file
@ -0,0 +1,20 @@
|
||||
---
|
||||
comments: true
|
||||
description: Train and Deploy your Model to 13 different formats, including TensorFlow, ONNX, OpenVINO, CoreML, Paddle or directly on Mobile.
|
||||
---
|
||||
|
||||
# HUB Models
|
||||
|
||||
## Train a Model
|
||||
|
||||
Connect to the Ultralytics HUB notebook and use your model API key to begin training!
|
||||
|
||||
<a href="https://colab.research.google.com/github/ultralytics/hub/blob/master/hub.ipynb" target="_blank">
|
||||
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>
|
||||
|
||||
## Deploy to Real World
|
||||
|
||||
Export your model to 13 different formats, including TensorFlow, ONNX, OpenVINO, CoreML, Paddle and many others. Run
|
||||
models directly on your [iOS](https://apps.apple.com/xk/app/ultralytics/id1583935240) or
|
||||
[Android](https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app) mobile device by downloading
|
||||
the [Ultralytics App](https://ultralytics.com/app_install)!
|
||||
7
docs/hub/projects.md
Normal file
7
docs/hub/projects.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
7
docs/hub/quickstart.md
Normal file
7
docs/hub/quickstart.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧 Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
41
docs/index.md
Normal file
41
docs/index.md
Normal file
@ -0,0 +1,41 @@
|
||||
---
|
||||
comments: true
|
||||
description: Explore Ultralytics YOLOv8, a cutting-edge real-time object detection and image segmentation model for various applications and hardware platforms.
|
||||
---
|
||||
|
||||
<div align="center">
|
||||
<p>
|
||||
<a href="https://github.com/ultralytics/ultralytics" target="_blank">
|
||||
<img width="1024" src="https://raw.githubusercontent.com/ultralytics/assets/main/yolov8/banner-yolov8.png"></a>
|
||||
</p>
|
||||
<a href="https://github.com/ultralytics/ultralytics/actions/workflows/ci.yaml"><img src="https://github.com/ultralytics/ultralytics/actions/workflows/ci.yaml/badge.svg" alt="Ultralytics CI"></a>
|
||||
<a href="https://zenodo.org/badge/latestdoi/264818686"><img src="https://zenodo.org/badge/264818686.svg" alt="YOLOv8 Citation"></a>
|
||||
<a href="https://hub.docker.com/r/ultralytics/ultralytics"><img src="https://img.shields.io/docker/pulls/ultralytics/ultralytics?logo=docker" alt="Docker Pulls"></a>
|
||||
<br>
|
||||
<a href="https://console.paperspace.com/github/ultralytics/ultralytics"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"/></a>
|
||||
<a href="https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>
|
||||
<a href="https://www.kaggle.com/ultralytics/yolov8"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||
</div>
|
||||
|
||||
Introducing [Ultralytics](https://ultralytics.com) [YOLOv8](https://github.com/ultralytics/ultralytics), the latest version of the acclaimed real-time object detection and image segmentation model. YOLOv8 is built on cutting-edge advancements in deep learning and computer vision, offering unparalleled performance in terms of speed and accuracy. Its streamlined design makes it suitable for various applications and easily adaptable to different hardware platforms, from edge devices to cloud APIs.
|
||||
|
||||
Explore the YOLOv8 Docs, a comprehensive resource designed to help you understand and utilize its features and capabilities. Whether you are a seasoned machine learning practitioner or new to the field, this hub aims to maximize YOLOv8's potential in your projects
|
||||
|
||||
## Where to Start
|
||||
|
||||
- **Install** `ultralytics` with pip and get up and running in minutes [:material-clock-fast: Get Started](quickstart.md){ .md-button }
|
||||
- **Predict** new images and videos with YOLOv8 [:octicons-image-16: Predict on Images](modes/predict.md){ .md-button }
|
||||
- **Train** a new YOLOv8 model on your own custom dataset [:fontawesome-solid-brain: Train a Model](modes/train.md){ .md-button }
|
||||
- **Explore** YOLOv8 tasks like segment, classify, pose and track [:material-magnify-expand: Explore Tasks](tasks/index.md){ .md-button }
|
||||
|
||||
## YOLO: A Brief History
|
||||
|
||||
[YOLO](https://arxiv.org/abs/1506.02640) (You Only Look Once), a popular object detection and image segmentation model, was developed by Joseph Redmon and Ali Farhadi at the University of Washington. Launched in 2015, YOLO quickly gained popularity for its high speed and accuracy.
|
||||
|
||||
- [YOLOv2](https://arxiv.org/abs/1612.08242), released in 2016, improved the original model by incorporating batch normalization, anchor boxes, and dimension clusters.
|
||||
- [YOLOv3](https://pjreddie.com/media/files/papers/YOLOv3.pdf), launched in 2018, further enhanced the model's performance using a more efficient backbone network, multiple anchors and spatial pyramid pooling.
|
||||
- [YOLOv4](https://arxiv.org/abs/2004.10934) was released in 2020, introducing innovations like Mosaic data augmentation, a new anchor-free detection head, and a new loss function.
|
||||
- [YOLOv5](https://github.com/ultralytics/yolov5) further improved the model's performance and added new features such as hyperparameter optimization, integrated experiment tracking and automatic export to popular export formats.
|
||||
- [YOLOv6](https://github.com/meituan/YOLOv6) was open-sourced by [Meituan](https://about.meituan.com/) in 2022 and is in use in many of the company's autonomous delivery robots.
|
||||
- [YOLOv7](https://github.com/WongKinYiu/yolov7) added additional tasks such as pose estimation on the COCO keypoints dataset.
|
||||
- [YOLOv8](https://github.com/ultralytics/ultralytics) is the latest version of YOLO by Ultralytics. As a cutting-edge, state-of-the-art (SOTA) model, YOLOv8 builds on the success of previous versions, introducing new features and improvements for enhanced performance, flexibility, and efficiency. YOLOv8 supports a full range of vision AI tasks, including [detection](tasks/detect.md), [segmentation](tasks/segment.md), [pose estimation](tasks/pose.md), [tracking](modes/track.md), and [classification](tasks/classify.md). This versatility allows users to leverage YOLOv8's capabilities across diverse applications and domains.
|
||||
37
docs/models/index.md
Normal file
37
docs/models/index.md
Normal file
@ -0,0 +1,37 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn about the supported models and architectures, such as YOLOv3, YOLOv5, and YOLOv8, and how to contribute your own model to Ultralytics.
|
||||
---
|
||||
|
||||
# Models
|
||||
|
||||
Ultralytics supports many models and architectures with more to come in the future. Want to add your model architecture? [Here's](../help/contributing.md) how you can contribute.
|
||||
|
||||
In this documentation, we provide information on four major models:
|
||||
|
||||
1. [YOLOv3](./yolov3.md): The third iteration of the YOLO model family, known for its efficient real-time object detection capabilities.
|
||||
2. [YOLOv5](./yolov5.md): An improved version of the YOLO architecture, offering better performance and speed tradeoffs compared to previous versions.
|
||||
3. [YOLOv8](./yolov8.md): The latest version of the YOLO family, featuring enhanced capabilities such as instance segmentation, pose/keypoints estimation, and classification.
|
||||
4. [Segment Anything Model (SAM)](./sam.md): Meta's Segment Anything Model (SAM).
|
||||
5. [Realtime Detection Transformers (RT-DETR)](./rtdetr.md): Baidu's RT-DETR model.
|
||||
|
||||
You can use these models directly in the Command Line Interface (CLI) or in a Python environment. Below are examples of how to use the models with CLI and Python:
|
||||
|
||||
## CLI Example
|
||||
|
||||
```bash
|
||||
yolo task=detect mode=train model=yolov8n.yaml data=coco128.yaml epochs=100
|
||||
```
|
||||
|
||||
## Python Example
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
model = YOLO("model.yaml") # build a YOLOv8n model from scratch
|
||||
# YOLO("model.pt") use pre-trained model if available
|
||||
model.info() # display model information
|
||||
model.train(data="coco128.yaml", epochs=100) # train the model
|
||||
```
|
||||
|
||||
For more details on each model, their supported tasks, modes, and performance, please visit their respective documentation pages linked above.
|
||||
67
docs/models/rtdetr.md
Normal file
67
docs/models/rtdetr.md
Normal file
@ -0,0 +1,67 @@
|
||||
---
|
||||
comments: true
|
||||
description: Explore RT-DETR, a high-performance real-time object detector. Learn how to use pre-trained models with Ultralytics Python API for various tasks.
|
||||
---
|
||||
|
||||
# RT-DETR
|
||||
|
||||
## Overview
|
||||
|
||||
Real-Time Detection Transformer (RT-DETR) is an end-to-end object detector that provides real-time performance while maintaining high accuracy. It efficiently processes multi-scale features by decoupling intra-scale interaction and cross-scale fusion, and supports flexible adjustment of inference speed using different decoder layers without retraining. RT-DETR outperforms many real-time object detectors on accelerated backends like CUDA with TensorRT.
|
||||
|
||||
### Key Features
|
||||
|
||||
- **Efficient Hybrid Encoder:** RT-DETR uses an efficient hybrid encoder that processes multi-scale features by decoupling intra-scale interaction and cross-scale fusion. This design reduces computational costs and allows for real-time object detection.
|
||||
- **IoU-aware Query Selection:** RT-DETR improves object query initialization by utilizing IoU-aware query selection. This allows the model to focus on the most relevant objects in the scene.
|
||||
- **Adaptable Inference Speed:** RT-DETR supports flexible adjustments of inference speed by using different decoder layers without the need for retraining. This adaptability facilitates practical application in various real-time object detection scenarios.
|
||||
|
||||
## Pre-trained Models
|
||||
|
||||
Ultralytics RT-DETR provides several pre-trained models with different scales:
|
||||
|
||||
- RT-DETR-L: 53.0% AP on COCO val2017, 114 FPS on T4 GPU
|
||||
- RT-DETR-X: 54.8% AP on COCO val2017, 74 FPS on T4 GPU
|
||||
|
||||
## Usage
|
||||
|
||||
### Python API
|
||||
|
||||
```python
|
||||
from ultralytics import RTDETR
|
||||
|
||||
model = RTDETR("rtdetr-l.pt")
|
||||
model.info() # display model information
|
||||
model.predict("path/to/image.jpg") # predict
|
||||
```
|
||||
|
||||
### Supported Tasks
|
||||
|
||||
| Model Type | Pre-trained Weights | Tasks Supported |
|
||||
|---------------------|---------------------|------------------|
|
||||
| RT-DETR Large | `rtdetr-l.pt` | Object Detection |
|
||||
| RT-DETR Extra-Large | `rtdetr-x.pt` | Object Detection |
|
||||
|
||||
### Supported Modes
|
||||
|
||||
| Mode | Supported |
|
||||
|------------|--------------------|
|
||||
| Inference | :heavy_check_mark: |
|
||||
| Validation | :heavy_check_mark: |
|
||||
| Training | :x: (Coming soon) |
|
||||
|
||||
# Citations and Acknowledgements
|
||||
|
||||
If you use RT-DETR in your research or development work, please cite the [original paper](https://arxiv.org/abs/2304.08069):
|
||||
|
||||
```bibtex
|
||||
@misc{lv2023detrs,
|
||||
title={DETRs Beat YOLOs on Real-time Object Detection},
|
||||
author={Wenyu Lv and Shangliang Xu and Yian Zhao and Guanzhong Wang and Jinman Wei and Cheng Cui and Yuning Du and Qingqing Dang and Yi Liu},
|
||||
year={2023},
|
||||
eprint={2304.08069},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
We would like to acknowledge Baidu's [PaddlePaddle]((https://github.com/PaddlePaddle/PaddleDetection)) team for creating and maintaining this valuable resource for the computer vision community.
|
||||
92
docs/models/sam.md
Normal file
92
docs/models/sam.md
Normal file
@ -0,0 +1,92 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn about the Segment Anything Model (SAM) and how it provides promptable image segmentation through an advanced architecture and the SA-1B dataset.
|
||||
---
|
||||
|
||||
# Segment Anything Model (SAM)
|
||||
|
||||
## Overview
|
||||
|
||||
The Segment Anything Model (SAM) is a groundbreaking image segmentation model that enables promptable segmentation with real-time performance. It forms the foundation for the Segment Anything project, which introduces a new task, model, and dataset for image segmentation. SAM is designed to be promptable, allowing it to transfer zero-shot to new image distributions and tasks. The model is trained on the [SA-1B dataset](https://ai.facebook.com/datasets/segment-anything/), which contains over 1 billion masks on 11 million licensed and privacy-respecting images. SAM has demonstrated impressive zero-shot performance, often surpassing prior fully supervised results.
|
||||
|
||||

|
||||
Example images with overlaid masks from our newly introduced dataset, SA-1B. SA-1B contains 11M diverse, high-resolution, licensed, and privacy protecting images and 1.1B high-quality segmentation masks. These masks were annotated fully automatically by SAM, and as verified by human ratings and numerous experiments, are of high quality and diversity. Images are grouped by number of masks per image for visualization (there are ∼100 masks per image on average).
|
||||
|
||||
## Key Features
|
||||
|
||||
- **Promptable Segmentation Task:** SAM is designed for a promptable segmentation task, enabling it to return a valid segmentation mask given any segmentation prompt, such as spatial or text information identifying an object.
|
||||
- **Advanced Architecture:** SAM utilizes a powerful image encoder, a prompt encoder, and a lightweight mask decoder. This architecture enables flexible prompting, real-time mask computation, and ambiguity awareness in segmentation.
|
||||
- **SA-1B Dataset:** The Segment Anything project introduces the SA-1B dataset, which contains over 1 billion masks on 11 million images. This dataset is the largest segmentation dataset to date, providing SAM with a diverse and large-scale source of data for training.
|
||||
- **Zero-Shot Performance:** SAM demonstrates remarkable zero-shot performance across a range of segmentation tasks, allowing it to be used out-of-the-box with prompt engineering for various applications.
|
||||
|
||||
For more information about the Segment Anything Model and the SA-1B dataset, please refer to the [Segment Anything website](https://segment-anything.com) and the research paper [Segment Anything](https://arxiv.org/abs/2304.02643).
|
||||
|
||||
## Usage
|
||||
|
||||
SAM can be used for a variety of downstream tasks involving object and image distributions beyond its training data. Examples include edge detection, object proposal generation, instance segmentation, and preliminary text-to-mask prediction. By employing prompt engineering, SAM can adapt to new tasks and data distributions in a zero-shot manner, making it a versatile and powerful tool for image segmentation tasks.
|
||||
|
||||
```python
|
||||
from ultralytics.vit import SAM
|
||||
|
||||
model = SAM('sam_b.pt')
|
||||
model.info() # display model information
|
||||
model.predict('path/to/image.jpg') # predict
|
||||
```
|
||||
|
||||
## Supported Tasks
|
||||
|
||||
| Model Type | Pre-trained Weights | Tasks Supported |
|
||||
|------------|---------------------|-----------------------|
|
||||
| sam base | `sam_b.pt` | Instance Segmentation |
|
||||
| sam large | `sam_l.pt` | Instance Segmentation |
|
||||
|
||||
## Supported Modes
|
||||
|
||||
| Mode | Supported |
|
||||
|------------|--------------------|
|
||||
| Inference | :heavy_check_mark: |
|
||||
| Validation | :x: |
|
||||
| Training | :x: |
|
||||
|
||||
## Auto-Annotation
|
||||
|
||||
Auto-annotation is an essential feature that allows you to generate a [segmentation dataset](https://docs.ultralytics.com/datasets/segment) using a pre-trained detection model. It enables you to quickly and accurately annotate a large number of images without the need for manual labeling, saving time and effort.
|
||||
|
||||
### Generate Segmentation Dataset Using a Detection Model
|
||||
|
||||
To auto-annotate your dataset using the Ultralytics framework, you can use the `auto_annotate` function as shown below:
|
||||
|
||||
```python
|
||||
from ultralytics.yolo.data import auto_annotate
|
||||
|
||||
auto_annotate(data="path/to/images", det_model="yolov8x.pt", sam_model='sam_b.pt')
|
||||
```
|
||||
|
||||
| Argument | Type | Description | Default |
|
||||
|------------|---------------------|---------------------------------------------------------------------------------------------------------|--------------|
|
||||
| data | str | Path to a folder containing images to be annotated. | |
|
||||
| det_model | str, optional | Pre-trained YOLO detection model. Defaults to 'yolov8x.pt'. | 'yolov8x.pt' |
|
||||
| sam_model | str, optional | Pre-trained SAM segmentation model. Defaults to 'sam_b.pt'. | 'sam_b.pt' |
|
||||
| device | str, optional | Device to run the models on. Defaults to an empty string (CPU or GPU, if available). | |
|
||||
| output_dir | str, None, optional | Directory to save the annotated results. Defaults to a 'labels' folder in the same directory as 'data'. | None |
|
||||
|
||||
The `auto_annotate` function takes the path to your images, along with optional arguments for specifying the pre-trained detection and SAM segmentation models, the device to run the models on, and the output directory for saving the annotated results.
|
||||
|
||||
By leveraging the power of pre-trained models, auto-annotation can significantly reduce the time and effort required for creating high-quality segmentation datasets. This feature is particularly useful for researchers and developers working with large image collections, as it allows them to focus on model development and evaluation rather than manual annotation.
|
||||
|
||||
## Citations and Acknowledgements
|
||||
|
||||
If you use SAM in your research or development work, please cite the following paper:
|
||||
|
||||
```bibtex
|
||||
@misc{kirillov2023segment,
|
||||
title={Segment Anything},
|
||||
author={Alexander Kirillov and Eric Mintun and Nikhila Ravi and Hanzi Mao and Chloe Rolland and Laura Gustafson and Tete Xiao and Spencer Whitehead and Alexander C. Berg and Wan-Yen Lo and Piotr Dollár and Ross Girshick},
|
||||
year={2023},
|
||||
eprint={2304.02643},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
We would like to acknowledge Meta AI for creating and maintaining this valuable resource for the computer vision community.
|
||||
7
docs/models/yolov3.md
Normal file
7
docs/models/yolov3.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
---
|
||||
|
||||
# 🚧Page Under Construction ⚒
|
||||
|
||||
This page is currently under construction!️👷Please check back later for updates. 😃🔜
|
||||
48
docs/models/yolov5.md
Normal file
48
docs/models/yolov5.md
Normal file
@ -0,0 +1,48 @@
|
||||
---
|
||||
comments: true
|
||||
description: Detect objects faster and more accurately using Ultralytics YOLOv5u. Find pre-trained models for each task, including Inference, Validation and Training.
|
||||
---
|
||||
|
||||
# YOLOv5u
|
||||
|
||||
## Overview
|
||||
|
||||
YOLOv5u is an updated version of YOLOv5 that incorporates the anchor-free split Ultralytics head used in the YOLOv8 models. It retains the same backbone and neck architecture as YOLOv5 but offers improved accuracy-speed tradeoff for object detection tasks.
|
||||
|
||||
## Key Features
|
||||
|
||||
- **Anchor-free Split Ultralytics Head:** YOLOv5u replaces the traditional anchor-based detection head with an anchor-free split Ultralytics head, resulting in improved performance.
|
||||
- **Optimized Accuracy-Speed Tradeoff:** The updated model offers a better balance between accuracy and speed, making it more suitable for a wider range of applications.
|
||||
- **Variety of Pre-trained Models:** YOLOv5u offers a range of pre-trained models tailored for various tasks, including Inference, Validation, and Training.
|
||||
|
||||
## Supported Tasks
|
||||
|
||||
| Model Type | Pre-trained Weights | Task |
|
||||
|------------|-----------------------------------------------------------------------------------------------------------------------------|-----------|
|
||||
| YOLOv5u | `yolov5nu`, `yolov5su`, `yolov5mu`, `yolov5lu`, `yolov5xu`, `yolov5n6u`, `yolov5s6u`, `yolov5m6u`, `yolov5l6u`, `yolov5x6u` | Detection |
|
||||
|
||||
## Supported Modes
|
||||
|
||||
| Mode | Supported |
|
||||
|------------|--------------------|
|
||||
| Inference | :heavy_check_mark: |
|
||||
| Validation | :heavy_check_mark: |
|
||||
| Training | :heavy_check_mark: |
|
||||
|
||||
??? Performance
|
||||
|
||||
=== "Detection"
|
||||
|
||||
| Model | size<br><sup>(pixels) | mAP<sup>val<br>50-95 | Speed<br><sup>CPU ONNX<br>(ms) | Speed<br><sup>A100 TensorRT<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>(B) |
|
||||
| ---------------------------------------------------------------------------------------- | --------------------- | -------------------- | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
|
||||
| [YOLOv5nu](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5nu.pt) | 640 | 34.3 | 73.6 | 1.06 | 2.6 | 7.7 |
|
||||
| [YOLOv5su](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5su.pt) | 640 | 43.0 | 120.7 | 1.27 | 9.1 | 24.0 |
|
||||
| [YOLOv5mu](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5mu.pt) | 640 | 49.0 | 233.9 | 1.86 | 25.1 | 64.2 |
|
||||
| [YOLOv5lu](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5lu.pt) | 640 | 52.2 | 408.4 | 2.50 | 53.2 | 135.0 |
|
||||
| [YOLOv5xu](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5xu.pt) | 640 | 53.2 | 763.2 | 3.81 | 97.2 | 246.4 |
|
||||
| | | | | | | |
|
||||
| [YOLOv5n6u](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5n6u.pt) | 1280 | 42.1 | - | - | 4.3 | 7.8 |
|
||||
| [YOLOv5s6u](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5s6u.pt) | 1280 | 48.6 | - | - | 15.3 | 24.6 |
|
||||
| [YOLOv5m6u](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5m6u.pt) | 1280 | 53.6 | - | - | 41.2 | 65.7 |
|
||||
| [YOLOv5l6u](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5l6u.pt) | 1280 | 55.7 | - | - | 86.1 | 137.4 |
|
||||
| [YOLOv5x6u](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5x6u.pt) | 1280 | 56.8 | - | - | 155.4 | 250.7 |
|
||||
77
docs/models/yolov8.md
Normal file
77
docs/models/yolov8.md
Normal file
@ -0,0 +1,77 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn about YOLOv8's pre-trained weights supporting detection, instance segmentation, pose, and classification tasks. Get performance details.
|
||||
---
|
||||
|
||||
# YOLOv8
|
||||
|
||||
## Overview
|
||||
|
||||
YOLOv8 is the latest iteration in the YOLO series of real-time object detectors, offering cutting-edge performance in terms of accuracy and speed. Building upon the advancements of previous YOLO versions, YOLOv8 introduces new features and optimizations that make it an ideal choice for various object detection tasks in a wide range of applications.
|
||||
|
||||
## Key Features
|
||||
|
||||
- **Advanced Backbone and Neck Architectures:** YOLOv8 employs state-of-the-art backbone and neck architectures, resulting in improved feature extraction and object detection performance.
|
||||
- **Anchor-free Split Ultralytics Head:** YOLOv8 adopts an anchor-free split Ultralytics head, which contributes to better accuracy and a more efficient detection process compared to anchor-based approaches.
|
||||
- **Optimized Accuracy-Speed Tradeoff:** With a focus on maintaining an optimal balance between accuracy and speed, YOLOv8 is suitable for real-time object detection tasks in diverse application areas.
|
||||
- **Variety of Pre-trained Models:** YOLOv8 offers a range of pre-trained models to cater to various tasks and performance requirements, making it easier to find the right model for your specific use case.
|
||||
|
||||
## Supported Tasks
|
||||
|
||||
| Model Type | Pre-trained Weights | Task |
|
||||
|-------------|------------------------------------------------------------------------------------------------------------------|-----------------------|
|
||||
| YOLOv8 | `yolov8n.pt`, `yolov8s.pt`, `yolov8m.pt`, `yolov8l.pt`, `yolov8x.pt` | Detection |
|
||||
| YOLOv8-seg | `yolov8n-seg.pt`, `yolov8s-seg.pt`, `yolov8m-seg.pt`, `yolov8l-seg.pt`, `yolov8x-seg.pt` | Instance Segmentation |
|
||||
| YOLOv8-pose | `yolov8n-pose.pt`, `yolov8s-pose.pt`, `yolov8m-pose.pt`, `yolov8l-pose.pt`, `yolov8x-pose.pt` ,`yolov8x-pose-p6` | Pose/Keypoints |
|
||||
| YOLOv8-cls | `yolov8n-cls.pt`, `yolov8s-cls.pt`, `yolov8m-cls.pt`, `yolov8l-cls.pt`, `yolov8x-cls.pt` | Classification |
|
||||
|
||||
## Supported Modes
|
||||
|
||||
| Mode | Supported |
|
||||
|------------|--------------------|
|
||||
| Inference | :heavy_check_mark: |
|
||||
| Validation | :heavy_check_mark: |
|
||||
| Training | :heavy_check_mark: |
|
||||
|
||||
??? Performance
|
||||
|
||||
=== "Detection"
|
||||
|
||||
| Model | size<br><sup>(pixels) | mAP<sup>val<br>50-95 | Speed<br><sup>CPU ONNX<br>(ms) | Speed<br><sup>A100 TensorRT<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>(B) |
|
||||
| ------------------------------------------------------------------------------------ | --------------------- | -------------------- | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
|
||||
| [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt) | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
|
||||
| [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s.pt) | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
|
||||
| [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m.pt) | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
|
||||
| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l.pt) | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
|
||||
| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x.pt) | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
|
||||
|
||||
=== "Segmentation"
|
||||
|
||||
| Model | size<br><sup>(pixels) | mAP<sup>box<br>50-95 | mAP<sup>mask<br>50-95 | Speed<br><sup>CPU ONNX<br>(ms) | Speed<br><sup>A100 TensorRT<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>(B) |
|
||||
| -------------------------------------------------------------------------------------------- | --------------------- | -------------------- | --------------------- | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
|
||||
| [YOLOv8n-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-seg.pt) | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
|
||||
| [YOLOv8s-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-seg.pt) | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
|
||||
| [YOLOv8m-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-seg.pt) | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
|
||||
| [YOLOv8l-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-seg.pt) | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
|
||||
| [YOLOv8x-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-seg.pt) | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
|
||||
|
||||
=== "Classification"
|
||||
|
||||
| Model | size<br><sup>(pixels) | acc<br><sup>top1 | acc<br><sup>top5 | Speed<br><sup>CPU ONNX<br>(ms) | Speed<br><sup>A100 TensorRT<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>(B) at 640 |
|
||||
| -------------------------------------------------------------------------------------------- | --------------------- | ---------------- | ---------------- | ------------------------------ | ----------------------------------- | ------------------ | ------------------------ |
|
||||
| [YOLOv8n-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-cls.pt) | 224 | 66.6 | 87.0 | 12.9 | 0.31 | 2.7 | 4.3 |
|
||||
| [YOLOv8s-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-cls.pt) | 224 | 72.3 | 91.1 | 23.4 | 0.35 | 6.4 | 13.5 |
|
||||
| [YOLOv8m-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-cls.pt) | 224 | 76.4 | 93.2 | 85.4 | 0.62 | 17.0 | 42.7 |
|
||||
| [YOLOv8l-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-cls.pt) | 224 | 78.0 | 94.1 | 163.0 | 0.87 | 37.5 | 99.7 |
|
||||
| [YOLOv8x-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-cls.pt) | 224 | 78.4 | 94.3 | 232.0 | 1.01 | 57.4 | 154.8 |
|
||||
|
||||
=== "Pose"
|
||||
|
||||
| Model | size<br><sup>(pixels) | mAP<sup>pose<br>50-95 | mAP<sup>pose<br>50 | Speed<br><sup>CPU ONNX<br>(ms) | Speed<br><sup>A100 TensorRT<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>(B) |
|
||||
| ---------------------------------------------------------------------------------------------------- | --------------------- | --------------------- | ------------------ | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
|
||||
| [YOLOv8n-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-pose.pt) | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |
|
||||
| [YOLOv8s-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-pose.pt) | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |
|
||||
| [YOLOv8m-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-pose.pt) | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
|
||||
| [YOLOv8l-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-pose.pt) | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
|
||||
| [YOLOv8x-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose.pt) | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
|
||||
| [YOLOv8x-pose-p6](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose-p6.pt) | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
|
||||
73
docs/modes/benchmark.md
Normal file
73
docs/modes/benchmark.md
Normal file
@ -0,0 +1,73 @@
|
||||
---
|
||||
comments: true
|
||||
description: Benchmark mode compares speed and accuracy of various YOLOv8 export formats like ONNX or OpenVINO. Optimize formats for speed or accuracy.
|
||||
---
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png">
|
||||
|
||||
**Benchmark mode** is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks
|
||||
provide information on the size of the exported format, its `mAP50-95` metrics (for object detection, segmentation and pose)
|
||||
or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export
|
||||
formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for
|
||||
their specific use case based on their requirements for speed and accuracy.
|
||||
|
||||
!!! tip "Tip"
|
||||
|
||||
* Export to ONNX or OpenVINO for up to 3x CPU speedup.
|
||||
* Export to TensorRT for up to 5x GPU speedup.
|
||||
|
||||
## Usage Examples
|
||||
|
||||
Run YOLOv8n benchmarks on all supported export formats including ONNX, TensorRT etc. See Arguments section below for a
|
||||
full list of export arguments.
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics.yolo.utils.benchmarks import benchmark
|
||||
|
||||
# Benchmark on GPU
|
||||
benchmark(model='yolov8n.pt', imgsz=640, half=False, device=0)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo benchmark model=yolov8n.pt imgsz=640 half=False device=0
|
||||
```
|
||||
|
||||
## Arguments
|
||||
|
||||
Arguments such as `model`, `imgsz`, `half`, `device`, and `hard_fail` provide users with the flexibility to fine-tune
|
||||
the benchmarks to their specific needs and compare the performance of different export formats with ease.
|
||||
|
||||
| Key | Value | Description |
|
||||
|-------------|---------|----------------------------------------------------------------------|
|
||||
| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |
|
||||
| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
|
||||
| `half` | `False` | FP16 quantization |
|
||||
| `int8` | `False` | INT8 quantization |
|
||||
| `device` | `None` | device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |
|
||||
| `hard_fail` | `False` | do not continue on error (bool), or val floor threshold (float) |
|
||||
|
||||
## Export Formats
|
||||
|
||||
Benchmarks will attempt to run automatically on all possible export formats below.
|
||||
|
||||
| Format | `format` Argument | Model | Metadata |
|
||||
|--------------------------------------------------------------------|-------------------|---------------------------|----------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |
|
||||
|
||||
See full `export` details in the [Export](https://docs.ultralytics.com/modes/export/) page.
|
||||
86
docs/modes/export.md
Normal file
86
docs/modes/export.md
Normal file
@ -0,0 +1,86 @@
|
||||
---
|
||||
comments: true
|
||||
description: 'Export mode: Create a deployment-ready YOLOv8 model by converting it to various formats. Export to ONNX or OpenVINO for up to 3x CPU speedup.'
|
||||
---
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png">
|
||||
|
||||
**Export mode** is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the
|
||||
model is converted to a format that can be used by other software applications or hardware devices. This mode is useful
|
||||
when deploying the model to production environments.
|
||||
|
||||
!!! tip "Tip"
|
||||
|
||||
* Export to ONNX or OpenVINO for up to 3x CPU speedup.
|
||||
* Export to TensorRT for up to 5x GPU speedup.
|
||||
|
||||
## Usage Examples
|
||||
|
||||
Export a YOLOv8n model to a different format like ONNX or TensorRT. See Arguments section below for a full list of
|
||||
export arguments.
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load an official model
|
||||
model = YOLO('path/to/best.pt') # load a custom trained
|
||||
|
||||
# Export the model
|
||||
model.export(format='onnx')
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo export model=yolov8n.pt format=onnx # export official model
|
||||
yolo export model=path/to/best.pt format=onnx # export custom trained model
|
||||
```
|
||||
|
||||
## Arguments
|
||||
|
||||
Export settings for YOLO models refer to the various configurations and options used to save or
|
||||
export the model for use in other environments or platforms. These settings can affect the model's performance, size,
|
||||
and compatibility with different systems. Some common YOLO export settings include the format of the exported model
|
||||
file (e.g. ONNX, TensorFlow SavedModel), the device on which the model will be run (e.g. CPU, GPU), and the presence of
|
||||
additional features such as masks or multiple labels per box. Other factors that may affect the export process include
|
||||
the specific task the model is being used for and the requirements or constraints of the target environment or platform.
|
||||
It is important to carefully consider and configure these settings to ensure that the exported model is optimized for
|
||||
the intended use case and can be used effectively in the target environment.
|
||||
|
||||
| Key | Value | Description |
|
||||
|-------------|-----------------|------------------------------------------------------|
|
||||
| `format` | `'torchscript'` | format to export to |
|
||||
| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
|
||||
| `keras` | `False` | use Keras for TF SavedModel export |
|
||||
| `optimize` | `False` | TorchScript: optimize for mobile |
|
||||
| `half` | `False` | FP16 quantization |
|
||||
| `int8` | `False` | INT8 quantization |
|
||||
| `dynamic` | `False` | ONNX/TensorRT: dynamic axes |
|
||||
| `simplify` | `False` | ONNX/TensorRT: simplify model |
|
||||
| `opset` | `None` | ONNX: opset version (optional, defaults to latest) |
|
||||
| `workspace` | `4` | TensorRT: workspace size (GB) |
|
||||
| `nms` | `False` | CoreML: add NMS |
|
||||
|
||||
## Export Formats
|
||||
|
||||
Available YOLOv8 export formats are in the table below. You can export to any format using the `format` argument,
|
||||
i.e. `format='onnx'` or `format='engine'`.
|
||||
|
||||
| Format | `format` Argument | Model | Metadata | Arguments |
|
||||
|--------------------------------------------------------------------|-------------------|---------------------------|----------|-----------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ | `imgsz`, `optimize` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ | `imgsz`, `half` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ | `imgsz`, `half`, `int8`, `nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ | `imgsz`, `keras` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |
|
||||
67
docs/modes/index.md
Normal file
67
docs/modes/index.md
Normal file
@ -0,0 +1,67 @@
|
||||
---
|
||||
comments: true
|
||||
description: Use Ultralytics YOLOv8 Modes (Train, Val, Predict, Export, Track, Benchmark) to train, validate, predict, track, export or benchmark.
|
||||
---
|
||||
|
||||
# Ultralytics YOLOv8 Modes
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png">
|
||||
|
||||
Ultralytics YOLOv8 supports several **modes** that can be used to perform different tasks. These modes are:
|
||||
|
||||
**Train**: For training a YOLOv8 model on a custom dataset.
|
||||
**Val**: For validating a YOLOv8 model after it has been trained.
|
||||
**Predict**: For making predictions using a trained YOLOv8 model on new images or videos.
|
||||
**Export**: For exporting a YOLOv8 model to a format that can be used for deployment.
|
||||
**Track**: For tracking objects in real-time using a YOLOv8 model.
|
||||
**Benchmark**: For benchmarking YOLOv8 exports (ONNX, TensorRT, etc.) speed and accuracy.
|
||||
|
||||
## [Train](train.md)
|
||||
|
||||
Train mode is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the
|
||||
specified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can
|
||||
accurately predict the classes and locations of objects in an image.
|
||||
|
||||
[Train Examples](train.md){ .md-button .md-button--primary}
|
||||
|
||||
## [Val](val.md)
|
||||
|
||||
Val mode is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a
|
||||
validation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters
|
||||
of the model to improve its performance.
|
||||
|
||||
[Val Examples](val.md){ .md-button .md-button--primary}
|
||||
|
||||
## [Predict](predict.md)
|
||||
|
||||
Predict mode is used for making predictions using a trained YOLOv8 model on new images or videos. In this mode, the
|
||||
model is loaded from a checkpoint file, and the user can provide images or videos to perform inference. The model
|
||||
predicts the classes and locations of objects in the input images or videos.
|
||||
|
||||
[Predict Examples](predict.md){ .md-button .md-button--primary}
|
||||
|
||||
## [Export](export.md)
|
||||
|
||||
Export mode is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the model is
|
||||
converted to a format that can be used by other software applications or hardware devices. This mode is useful when
|
||||
deploying the model to production environments.
|
||||
|
||||
[Export Examples](export.md){ .md-button .md-button--primary}
|
||||
|
||||
## [Track](track.md)
|
||||
|
||||
Track mode is used for tracking objects in real-time using a YOLOv8 model. In this mode, the model is loaded from a
|
||||
checkpoint file, and the user can provide a live video stream to perform real-time object tracking. This mode is useful
|
||||
for applications such as surveillance systems or self-driving cars.
|
||||
|
||||
[Track Examples](track.md){ .md-button .md-button--primary}
|
||||
|
||||
## [Benchmark](benchmark.md)
|
||||
|
||||
Benchmark mode is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks provide
|
||||
information on the size of the exported format, its `mAP50-95` metrics (for object detection, segmentation and pose)
|
||||
or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export
|
||||
formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for
|
||||
their specific use case based on their requirements for speed and accuracy.
|
||||
|
||||
[Benchmark Examples](benchmark.md){ .md-button .md-button--primary}
|
||||
282
docs/modes/predict.md
Normal file
282
docs/modes/predict.md
Normal file
@ -0,0 +1,282 @@
|
||||
---
|
||||
comments: true
|
||||
description: Get started with YOLOv8 Predict mode and input sources. Accepts various input sources such as images, videos, and directories.
|
||||
---
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png">
|
||||
|
||||
YOLOv8 **predict mode** can generate predictions for various tasks, returning either a list of `Results` objects or a
|
||||
memory-efficient generator of `Results` objects when using the streaming mode. Enable streaming mode by
|
||||
passing `stream=True` in the predictor's call method.
|
||||
|
||||
!!! example "Predict"
|
||||
|
||||
=== "Return a list with `Stream=False`"
|
||||
```python
|
||||
inputs = [img, img] # list of numpy arrays
|
||||
results = model(inputs) # list of Results objects
|
||||
|
||||
for result in results:
|
||||
boxes = result.boxes # Boxes object for bbox outputs
|
||||
masks = result.masks # Masks object for segmentation masks outputs
|
||||
probs = result.probs # Class probabilities for classification outputs
|
||||
```
|
||||
|
||||
=== "Return a generator with `Stream=True`"
|
||||
```python
|
||||
inputs = [img, img] # list of numpy arrays
|
||||
results = model(inputs, stream=True) # generator of Results objects
|
||||
|
||||
for result in results:
|
||||
boxes = result.boxes # Boxes object for bbox outputs
|
||||
masks = result.masks # Masks object for segmentation masks outputs
|
||||
probs = result.probs # Class probabilities for classification outputs
|
||||
```
|
||||
|
||||
!!! tip "Tip"
|
||||
|
||||
Streaming mode with `stream=True` should be used for long videos or large predict sources, otherwise results will accumuate in memory and will eventually cause out-of-memory errors.
|
||||
|
||||
## Sources
|
||||
|
||||
YOLOv8 can accept various input sources, as shown in the table below. This includes images, URLs, PIL images, OpenCV,
|
||||
numpy arrays, torch tensors, CSV files, videos, directories, globs, YouTube videos, and streams. The table indicates
|
||||
whether each source can be used in streaming mode with `stream=True` ✅ and an example argument for each source.
|
||||
|
||||
| source | model(arg) | type | notes |
|
||||
|-------------|--------------------------------------------|----------------|------------------|
|
||||
| image | `'im.jpg'` | `str`, `Path` | |
|
||||
| URL | `'https://ultralytics.com/images/bus.jpg'` | `str` | |
|
||||
| screenshot | `'screen'` | `str` | |
|
||||
| PIL | `Image.open('im.jpg')` | `PIL.Image` | HWC, RGB |
|
||||
| OpenCV | `cv2.imread('im.jpg')` | `np.ndarray` | HWC, BGR |
|
||||
| numpy | `np.zeros((640,1280,3))` | `np.ndarray` | HWC |
|
||||
| torch | `torch.zeros(16,3,320,640)` | `torch.Tensor` | BCHW, RGB |
|
||||
| CSV | `'sources.csv'` | `str`, `Path` | RTSP, RTMP, HTTP |
|
||||
| video ✅ | `'vid.mp4'` | `str`, `Path` | |
|
||||
| directory ✅ | `'path/'` | `str`, `Path` | |
|
||||
| glob ✅ | `'path/*.jpg'` | `str` | Use `*` operator |
|
||||
| YouTube ✅ | `'https://youtu.be/Zgi9g1ksQHc'` | `str` | |
|
||||
| stream ✅ | `'rtsp://example.com/media.mp4'` | `str` | RTSP, RTMP, HTTP |
|
||||
|
||||
## Arguments
|
||||
|
||||
`model.predict` accepts multiple arguments that control the prediction operation. These arguments can be passed directly to `model.predict`:
|
||||
!!! example
|
||||
|
||||
```
|
||||
model.predict(source, save=True, imgsz=320, conf=0.5)
|
||||
```
|
||||
|
||||
All supported arguments:
|
||||
|
||||
| Key | Value | Description |
|
||||
|----------------|------------------------|--------------------------------------------------------------------------------|
|
||||
| `source` | `'ultralytics/assets'` | source directory for images or videos |
|
||||
| `conf` | `0.25` | object confidence threshold for detection |
|
||||
| `iou` | `0.7` | intersection over union (IoU) threshold for NMS |
|
||||
| `half` | `False` | use half precision (FP16) |
|
||||
| `device` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |
|
||||
| `show` | `False` | show results if possible |
|
||||
| `save` | `False` | save images with results |
|
||||
| `save_txt` | `False` | save results as .txt file |
|
||||
| `save_conf` | `False` | save results with confidence scores |
|
||||
| `save_crop` | `False` | save cropped images with results |
|
||||
| `hide_labels` | `False` | hide labels |
|
||||
| `hide_conf` | `False` | hide confidence scores |
|
||||
| `max_det` | `300` | maximum number of detections per image |
|
||||
| `vid_stride` | `False` | video frame-rate stride |
|
||||
| `line_width` | `None` | The line width of the bounding boxes. If None, it is scaled to the image size. |
|
||||
| `visualize` | `False` | visualize model features |
|
||||
| `augment` | `False` | apply image augmentation to prediction sources |
|
||||
| `agnostic_nms` | `False` | class-agnostic NMS |
|
||||
| `retina_masks` | `False` | use high-resolution segmentation masks |
|
||||
| `classes` | `None` | filter results by class, i.e. class=0, or class=[0,2,3] |
|
||||
| `boxes` | `True` | Show boxes in segmentation predictions |
|
||||
|
||||
## Image and Video Formats
|
||||
|
||||
YOLOv8 supports various image and video formats, as specified
|
||||
in [yolo/data/utils.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/data/utils.py). See the
|
||||
tables below for the valid suffixes and example predict commands.
|
||||
|
||||
### Image Suffixes
|
||||
|
||||
| Image Suffixes | Example Predict Command | Reference |
|
||||
|----------------|----------------------------------|-------------------------------------------------------------------------------|
|
||||
| .bmp | `yolo predict source=image.bmp` | [Microsoft BMP File Format](https://en.wikipedia.org/wiki/BMP_file_format) |
|
||||
| .dng | `yolo predict source=image.dng` | [Adobe DNG](https://www.adobe.com/products/photoshop/extend.displayTab2.html) |
|
||||
| .jpeg | `yolo predict source=image.jpeg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) |
|
||||
| .jpg | `yolo predict source=image.jpg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) |
|
||||
| .mpo | `yolo predict source=image.mpo` | [Multi Picture Object](https://fileinfo.com/extension/mpo) |
|
||||
| .png | `yolo predict source=image.png` | [Portable Network Graphics](https://en.wikipedia.org/wiki/PNG) |
|
||||
| .tif | `yolo predict source=image.tif` | [Tag Image File Format](https://en.wikipedia.org/wiki/TIFF) |
|
||||
| .tiff | `yolo predict source=image.tiff` | [Tag Image File Format](https://en.wikipedia.org/wiki/TIFF) |
|
||||
| .webp | `yolo predict source=image.webp` | [WebP](https://en.wikipedia.org/wiki/WebP) |
|
||||
| .pfm | `yolo predict source=image.pfm` | [Portable FloatMap](https://en.wikipedia.org/wiki/Netpbm#File_formats) |
|
||||
|
||||
### Video Suffixes
|
||||
|
||||
| Video Suffixes | Example Predict Command | Reference |
|
||||
|----------------|----------------------------------|----------------------------------------------------------------------------------|
|
||||
| .asf | `yolo predict source=video.asf` | [Advanced Systems Format](https://en.wikipedia.org/wiki/Advanced_Systems_Format) |
|
||||
| .avi | `yolo predict source=video.avi` | [Audio Video Interleave](https://en.wikipedia.org/wiki/Audio_Video_Interleave) |
|
||||
| .gif | `yolo predict source=video.gif` | [Graphics Interchange Format](https://en.wikipedia.org/wiki/GIF) |
|
||||
| .m4v | `yolo predict source=video.m4v` | [MPEG-4 Part 14](https://en.wikipedia.org/wiki/M4V) |
|
||||
| .mkv | `yolo predict source=video.mkv` | [Matroska](https://en.wikipedia.org/wiki/Matroska) |
|
||||
| .mov | `yolo predict source=video.mov` | [QuickTime File Format](https://en.wikipedia.org/wiki/QuickTime_File_Format) |
|
||||
| .mp4 | `yolo predict source=video.mp4` | [MPEG-4 Part 14 - Wikipedia](https://en.wikipedia.org/wiki/MPEG-4_Part_14) |
|
||||
| .mpeg | `yolo predict source=video.mpeg` | [MPEG-1 Part 2](https://en.wikipedia.org/wiki/MPEG-1) |
|
||||
| .mpg | `yolo predict source=video.mpg` | [MPEG-1 Part 2](https://en.wikipedia.org/wiki/MPEG-1) |
|
||||
| .ts | `yolo predict source=video.ts` | [MPEG Transport Stream](https://en.wikipedia.org/wiki/MPEG_transport_stream) |
|
||||
| .wmv | `yolo predict source=video.wmv` | [Windows Media Video](https://en.wikipedia.org/wiki/Windows_Media_Video) |
|
||||
| .webm | `yolo predict source=video.webm` | [WebM Project](https://en.wikipedia.org/wiki/WebM) |
|
||||
|
||||
## Working with Results
|
||||
|
||||
The `Results` object contains the following components:
|
||||
|
||||
- `Results.boxes`: `Boxes` object with properties and methods for manipulating bounding boxes
|
||||
- `Results.masks`: `Masks` object for indexing masks or getting segment coordinates
|
||||
- `Results.probs`: `torch.Tensor` containing class probabilities or logits
|
||||
- `Results.orig_img`: Original image loaded in memory
|
||||
- `Results.path`: `Path` containing the path to the input image
|
||||
|
||||
Each result is composed of a `torch.Tensor` by default, which allows for easy manipulation:
|
||||
|
||||
!!! example "Results"
|
||||
|
||||
```python
|
||||
results = results.cuda()
|
||||
results = results.cpu()
|
||||
results = results.to('cpu')
|
||||
results = results.numpy()
|
||||
```
|
||||
|
||||
### Boxes
|
||||
|
||||
`Boxes` object can be used to index, manipulate, and convert bounding boxes to different formats. Box format conversion
|
||||
operations are cached, meaning they're only calculated once per object, and those values are reused for future calls.
|
||||
|
||||
- Indexing a `Boxes` object returns a `Boxes` object:
|
||||
|
||||
!!! example "Boxes"
|
||||
|
||||
```python
|
||||
results = model(img)
|
||||
boxes = results[0].boxes
|
||||
box = boxes[0] # returns one box
|
||||
box.xyxy
|
||||
```
|
||||
|
||||
- Properties and conversions
|
||||
|
||||
!!! example "Boxes Properties"
|
||||
|
||||
```python
|
||||
boxes.xyxy # box with xyxy format, (N, 4)
|
||||
boxes.xywh # box with xywh format, (N, 4)
|
||||
boxes.xyxyn # box with xyxy format but normalized, (N, 4)
|
||||
boxes.xywhn # box with xywh format but normalized, (N, 4)
|
||||
boxes.conf # confidence score, (N, 1)
|
||||
boxes.cls # cls, (N, 1)
|
||||
boxes.data # raw bboxes tensor, (N, 6) or boxes.boxes
|
||||
```
|
||||
|
||||
### Masks
|
||||
|
||||
`Masks` object can be used index, manipulate and convert masks to segments. The segment conversion operation is cached.
|
||||
|
||||
!!! example "Masks"
|
||||
|
||||
```python
|
||||
results = model(inputs)
|
||||
masks = results[0].masks # Masks object
|
||||
masks.xy # x, y segments (pixels), List[segment] * N
|
||||
masks.xyn # x, y segments (normalized), List[segment] * N
|
||||
masks.data # raw masks tensor, (N, H, W) or masks.masks
|
||||
```
|
||||
|
||||
### probs
|
||||
|
||||
`probs` attribute of `Results` class is a `Tensor` containing class probabilities of a classification operation.
|
||||
|
||||
!!! example "Probs"
|
||||
|
||||
```python
|
||||
results = model(inputs)
|
||||
results[0].probs # cls prob, (num_class, )
|
||||
```
|
||||
|
||||
Class reference documentation for `Results` module and its components can be found [here](../reference/yolo/engine/results.md)
|
||||
|
||||
## Plotting results
|
||||
|
||||
You can use `plot()` function of `Result` object to plot results on in image object. It plots all components(boxes,
|
||||
masks, classification logits, etc.) found in the results object
|
||||
|
||||
!!! example "Plotting"
|
||||
|
||||
```python
|
||||
res = model(img)
|
||||
res_plotted = res[0].plot()
|
||||
cv2.imshow("result", res_plotted)
|
||||
```
|
||||
|
||||
| Argument | Description |
|
||||
|-------------------------------|----------------------------------------------------------------------------------------|
|
||||
| `conf (bool)` | Whether to plot the detection confidence score. |
|
||||
| `line_width (int, optional)` | The line width of the bounding boxes. If None, it is scaled to the image size. |
|
||||
| `font_size (float, optional)` | The font size of the text. If None, it is scaled to the image size. |
|
||||
| `font (str)` | The font to use for the text. |
|
||||
| `pil (bool)` | Whether to use PIL for image plotting. |
|
||||
| `example (str)` | An example string to display. Useful for indicating the expected format of the output. |
|
||||
| `img (numpy.ndarray)` | Plot to another image. if not, plot to original image. |
|
||||
| `labels (bool)` | Whether to plot the label of bounding boxes. |
|
||||
| `boxes (bool)` | Whether to plot the bounding boxes. |
|
||||
| `masks (bool)` | Whether to plot the masks. |
|
||||
| `probs (bool)` | Whether to plot classification probability. |
|
||||
|
||||
## Streaming Source `for`-loop
|
||||
|
||||
Here's a Python script using OpenCV (cv2) and YOLOv8 to run inference on video frames. This script assumes you have already installed the necessary packages (opencv-python and ultralytics).
|
||||
|
||||
!!! example "Streaming for-loop"
|
||||
|
||||
```python
|
||||
import cv2
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load the YOLOv8 model
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Open the video file
|
||||
video_path = "path/to/your/video/file.mp4"
|
||||
cap = cv2.VideoCapture(video_path)
|
||||
|
||||
# Loop through the video frames
|
||||
while cap.isOpened():
|
||||
# Read a frame from the video
|
||||
success, frame = cap.read()
|
||||
|
||||
if success:
|
||||
# Run YOLOv8 inference on the frame
|
||||
results = model(frame)
|
||||
|
||||
# Visualize the results on the frame
|
||||
annotated_frame = results[0].plot()
|
||||
|
||||
# Display the annotated frame
|
||||
cv2.imshow("YOLOv8 Inference", annotated_frame)
|
||||
|
||||
# Break the loop if 'q' is pressed
|
||||
if cv2.waitKey(1) & 0xFF == ord("q"):
|
||||
break
|
||||
else:
|
||||
# Break the loop if the end of the video is reached
|
||||
break
|
||||
|
||||
# Release the video capture object and close the display window
|
||||
cap.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
101
docs/modes/track.md
Normal file
101
docs/modes/track.md
Normal file
@ -0,0 +1,101 @@
|
||||
---
|
||||
comments: true
|
||||
description: Explore YOLOv8n-based object tracking with Ultralytics' BoT-SORT and ByteTrack. Learn configuration, usage, and customization tips.
|
||||
---
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png">
|
||||
|
||||
Object tracking is a task that involves identifying the location and class of objects, then assigning a unique ID to
|
||||
that detection in video streams.
|
||||
|
||||
The output of tracker is the same as detection with an added object ID.
|
||||
|
||||
## Available Trackers
|
||||
|
||||
The following tracking algorithms have been implemented and can be enabled by passing `tracker=tracker_type.yaml`
|
||||
|
||||
* [BoT-SORT](https://github.com/NirAharon/BoT-SORT) - `botsort.yaml`
|
||||
* [ByteTrack](https://github.com/ifzhang/ByteTrack) - `bytetrack.yaml`
|
||||
|
||||
The default tracker is BoT-SORT.
|
||||
|
||||
## Tracking
|
||||
|
||||
Use a trained YOLOv8n/YOLOv8n-seg model to run tracker on video streams.
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load an official detection model
|
||||
model = YOLO('yolov8n-seg.pt') # load an official segmentation model
|
||||
model = YOLO('path/to/best.pt') # load a custom model
|
||||
|
||||
# Track with the model
|
||||
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True)
|
||||
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True, tracker="bytetrack.yaml")
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" # official detection model
|
||||
yolo track model=yolov8n-seg.pt source=... # official segmentation model
|
||||
yolo track model=path/to/best.pt source=... # custom model
|
||||
yolo track model=path/to/best.pt tracker="bytetrack.yaml" # bytetrack tracker
|
||||
|
||||
```
|
||||
|
||||
As in the above usage, we support both the detection and segmentation models for tracking and the only thing you need to
|
||||
do is loading the corresponding (detection or segmentation) model.
|
||||
|
||||
## Configuration
|
||||
|
||||
### Tracking
|
||||
|
||||
Tracking shares the configuration with predict, i.e `conf`, `iou`, `show`. More configurations please refer
|
||||
to [predict page](https://docs.ultralytics.com/modes/predict/).
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
model = YOLO('yolov8n.pt')
|
||||
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", conf=0.3, iou=0.5, show=True)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" conf=0.3, iou=0.5 show
|
||||
|
||||
```
|
||||
|
||||
### Tracker
|
||||
|
||||
We also support using a modified tracker config file, just copy a config file i.e `custom_tracker.yaml`
|
||||
from [ultralytics/tracker/cfg](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/tracker/cfg) and modify
|
||||
any configurations(expect the `tracker_type`) you need to.
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
model = YOLO('yolov8n.pt')
|
||||
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", tracker='custom_tracker.yaml')
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" tracker='custom_tracker.yaml'
|
||||
```
|
||||
|
||||
Please refer to [ultralytics/tracker/cfg](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/tracker/cfg)
|
||||
page
|
||||
|
||||
102
docs/modes/train.md
Normal file
102
docs/modes/train.md
Normal file
@ -0,0 +1,102 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to train custom YOLOv8 models on various datasets, configure hyperparameters, and use Ultralytics' YOLO for seamless training.
|
||||
---
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png">
|
||||
|
||||
**Train mode** is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the
|
||||
specified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can
|
||||
accurately predict the classes and locations of objects in an image.
|
||||
|
||||
!!! tip "Tip"
|
||||
|
||||
* YOLOv8 datasets like COCO, VOC, ImageNet and many others automatically download on first use, i.e. `yolo train data=coco.yaml`
|
||||
|
||||
## Usage Examples
|
||||
|
||||
Train YOLOv8n on the COCO128 dataset for 100 epochs at image size 640. See Arguments section below for a full list of
|
||||
training arguments.
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.yaml') # build a new model from YAML
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
|
||||
|
||||
# Train the model
|
||||
model.train(data='coco128.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Build a new model from YAML and start training from scratch
|
||||
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
|
||||
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
|
||||
# Build a new model from YAML, transfer pretrained weights to it and start training
|
||||
yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Arguments
|
||||
|
||||
Training settings for YOLO models refer to the various hyperparameters and configurations used to train the model on a
|
||||
dataset. These settings can affect the model's performance, speed, and accuracy. Some common YOLO training settings
|
||||
include the batch size, learning rate, momentum, and weight decay. Other factors that may affect the training process
|
||||
include the choice of optimizer, the choice of loss function, and the size and composition of the training dataset. It
|
||||
is important to carefully tune and experiment with these settings to achieve the best possible performance for a given
|
||||
task.
|
||||
|
||||
| Key | Value | Description |
|
||||
|-------------------|----------|-----------------------------------------------------------------------------|
|
||||
| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |
|
||||
| `data` | `None` | path to data file, i.e. coco128.yaml |
|
||||
| `epochs` | `100` | number of epochs to train for |
|
||||
| `patience` | `50` | epochs to wait for no observable improvement for early stopping of training |
|
||||
| `batch` | `16` | number of images per batch (-1 for AutoBatch) |
|
||||
| `imgsz` | `640` | size of input images as integer or w,h |
|
||||
| `save` | `True` | save train checkpoints and predict results |
|
||||
| `save_period` | `-1` | Save checkpoint every x epochs (disabled if < 1) |
|
||||
| `cache` | `False` | True/ram, disk or False. Use cache for data loading |
|
||||
| `device` | `None` | device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |
|
||||
| `workers` | `8` | number of worker threads for data loading (per RANK if DDP) |
|
||||
| `project` | `None` | project name |
|
||||
| `name` | `None` | experiment name |
|
||||
| `exist_ok` | `False` | whether to overwrite existing experiment |
|
||||
| `pretrained` | `False` | whether to use a pretrained model |
|
||||
| `optimizer` | `'SGD'` | optimizer to use, choices=['SGD', 'Adam', 'AdamW', 'RMSProp'] |
|
||||
| `verbose` | `False` | whether to print verbose output |
|
||||
| `seed` | `0` | random seed for reproducibility |
|
||||
| `deterministic` | `True` | whether to enable deterministic mode |
|
||||
| `single_cls` | `False` | train multi-class data as single-class |
|
||||
| `rect` | `False` | rectangular training with each batch collated for minimum padding |
|
||||
| `cos_lr` | `False` | use cosine learning rate scheduler |
|
||||
| `close_mosaic` | `0` | (int) disable mosaic augmentation for final epochs |
|
||||
| `resume` | `False` | resume training from last checkpoint |
|
||||
| `amp` | `True` | Automatic Mixed Precision (AMP) training, choices=[True, False] |
|
||||
| `lr0` | `0.01` | initial learning rate (i.e. SGD=1E-2, Adam=1E-3) |
|
||||
| `lrf` | `0.01` | final learning rate (lr0 * lrf) |
|
||||
| `momentum` | `0.937` | SGD momentum/Adam beta1 |
|
||||
| `weight_decay` | `0.0005` | optimizer weight decay 5e-4 |
|
||||
| `warmup_epochs` | `3.0` | warmup epochs (fractions ok) |
|
||||
| `warmup_momentum` | `0.8` | warmup initial momentum |
|
||||
| `warmup_bias_lr` | `0.1` | warmup initial bias lr |
|
||||
| `box` | `7.5` | box loss gain |
|
||||
| `cls` | `0.5` | cls loss gain (scale with pixels) |
|
||||
| `dfl` | `1.5` | dfl loss gain |
|
||||
| `pose` | `12.0` | pose loss gain (pose-only) |
|
||||
| `kobj` | `2.0` | keypoint obj loss gain (pose-only) |
|
||||
| `label_smoothing` | `0.0` | label smoothing (fraction) |
|
||||
| `nbs` | `64` | nominal batch size |
|
||||
| `overlap_mask` | `True` | masks should overlap during training (segment train only) |
|
||||
| `mask_ratio` | `4` | mask downsample ratio (segment train only) |
|
||||
| `dropout` | `0.0` | use dropout regularization (classify train only) |
|
||||
| `val` | `True` | validate/test during training |
|
||||
91
docs/modes/val.md
Normal file
91
docs/modes/val.md
Normal file
@ -0,0 +1,91 @@
|
||||
---
|
||||
comments: true
|
||||
description: Validate and improve YOLOv8n model accuracy on COCO128 and other datasets using hyperparameter & configuration tuning, in Val mode.
|
||||
---
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png">
|
||||
|
||||
**Val mode** is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a
|
||||
validation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters
|
||||
of the model to improve its performance.
|
||||
|
||||
!!! tip "Tip"
|
||||
|
||||
* YOLOv8 models automatically remember their training settings, so you can validate a model at the same image size and on the original dataset easily with just `yolo val model=yolov8n.pt` or `model('yolov8n.pt').val()`
|
||||
|
||||
## Usage Examples
|
||||
|
||||
Validate trained YOLOv8n model accuracy on the COCO128 dataset. No argument need to passed as the `model` retains it's
|
||||
training `data` and arguments as model attributes. See Arguments section below for a full list of export arguments.
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load an official model
|
||||
model = YOLO('path/to/best.pt') # load a custom model
|
||||
|
||||
# Validate the model
|
||||
metrics = model.val() # no arguments needed, dataset and settings remembered
|
||||
metrics.box.map # map50-95
|
||||
metrics.box.map50 # map50
|
||||
metrics.box.map75 # map75
|
||||
metrics.box.maps # a list contains map50-95 of each category
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo detect val model=yolov8n.pt # val official model
|
||||
yolo detect val model=path/to/best.pt # val custom model
|
||||
```
|
||||
|
||||
## Arguments
|
||||
|
||||
Validation settings for YOLO models refer to the various hyperparameters and configurations used to
|
||||
evaluate the model's performance on a validation dataset. These settings can affect the model's performance, speed, and
|
||||
accuracy. Some common YOLO validation settings include the batch size, the frequency with which validation is performed
|
||||
during training, and the metrics used to evaluate the model's performance. Other factors that may affect the validation
|
||||
process include the size and composition of the validation dataset and the specific task the model is being used for. It
|
||||
is important to carefully tune and experiment with these settings to ensure that the model is performing well on the
|
||||
validation dataset and to detect and prevent overfitting.
|
||||
|
||||
| Key | Value | Description |
|
||||
|---------------|---------|--------------------------------------------------------------------|
|
||||
| `data` | `None` | path to data file, i.e. coco128.yaml |
|
||||
| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
|
||||
| `batch` | `16` | number of images per batch (-1 for AutoBatch) |
|
||||
| `save_json` | `False` | save results to JSON file |
|
||||
| `save_hybrid` | `False` | save hybrid version of labels (labels + additional predictions) |
|
||||
| `conf` | `0.001` | object confidence threshold for detection |
|
||||
| `iou` | `0.6` | intersection over union (IoU) threshold for NMS |
|
||||
| `max_det` | `300` | maximum number of detections per image |
|
||||
| `half` | `True` | use half precision (FP16) |
|
||||
| `device` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |
|
||||
| `dnn` | `False` | use OpenCV DNN for ONNX inference |
|
||||
| `plots` | `False` | show plots during training |
|
||||
| `rect` | `False` | rectangular val with each batch collated for minimum padding |
|
||||
| `split` | `val` | dataset split to use for validation, i.e. 'val', 'test' or 'train' |
|
||||
|
||||
## Export Formats
|
||||
|
||||
Available YOLOv8 export formats are in the table below. You can export to any format using the `format` argument,
|
||||
i.e. `format='onnx'` or `format='engine'`.
|
||||
|
||||
| Format | `format` Argument | Model | Metadata | Arguments |
|
||||
|--------------------------------------------------------------------|-------------------|---------------------------|----------|-----------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ | `imgsz`, `optimize` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ | `imgsz`, `half` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ | `imgsz`, `half`, `int8`, `nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ | `imgsz`, `keras` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |
|
||||
50
docs/overrides/partials/comments.html
Normal file
50
docs/overrides/partials/comments.html
Normal file
@ -0,0 +1,50 @@
|
||||
{% if page.meta.comments %}
|
||||
<h2 id="__comments">{{ lang.t("meta.comments") }}</h2>
|
||||
|
||||
<!-- Insert Giscus code snippet from https://giscus.app/ here -->
|
||||
<script src="https://giscus.app/client.js"
|
||||
data-repo="ultralytics/ultralytics"
|
||||
data-repo-id="R_kgDOH-jzvQ"
|
||||
data-category="Docs"
|
||||
data-category-id="DIC_kwDOH-jzvc4CWLkL"
|
||||
data-mapping="title"
|
||||
data-strict="0"
|
||||
data-reactions-enabled="1"
|
||||
data-emit-metadata="0"
|
||||
data-input-position="bottom"
|
||||
data-theme="preferred_color_scheme"
|
||||
data-lang="en"
|
||||
crossorigin="anonymous"
|
||||
async>
|
||||
</script>
|
||||
|
||||
<!-- Synchronize Giscus theme with palette -->
|
||||
<script>
|
||||
var giscus = document.querySelector("script[src*=giscus]")
|
||||
|
||||
/* Set palette on initial load */
|
||||
var palette = __md_get("__palette")
|
||||
if (palette && typeof palette.color === "object") {
|
||||
var theme = palette.color.scheme === "slate" ? "dark" : "light"
|
||||
giscus.setAttribute("data-theme", theme)
|
||||
}
|
||||
|
||||
/* Register event handlers after documented loaded */
|
||||
document.addEventListener("DOMContentLoaded", function() {
|
||||
var ref = document.querySelector("[data-md-component=palette]")
|
||||
ref.addEventListener("change", function() {
|
||||
var palette = __md_get("__palette")
|
||||
if (palette && typeof palette.color === "object") {
|
||||
var theme = palette.color.scheme === "slate" ? "dark" : "light"
|
||||
|
||||
/* Instruct Giscus to change theme */
|
||||
var frame = document.querySelector(".giscus-frame")
|
||||
frame.contentWindow.postMessage(
|
||||
{ giscus: { setConfig: { theme } } },
|
||||
"https://giscus.app"
|
||||
)
|
||||
}
|
||||
})
|
||||
})
|
||||
</script>
|
||||
{% endif %}
|
||||
26
docs/overrides/partials/source-file.html
Normal file
26
docs/overrides/partials/source-file.html
Normal file
@ -0,0 +1,26 @@
|
||||
{% import "partials/language.html" as lang with context %}
|
||||
|
||||
<!-- taken from
|
||||
https://github.com/squidfunk/mkdocs-material/blob/master/src/partials/source-file.html -->
|
||||
|
||||
<br>
|
||||
<div class="md-source-file">
|
||||
<small>
|
||||
|
||||
<!-- mkdocs-git-revision-date-localized-plugin -->
|
||||
{% if page.meta.git_revision_date_localized %}
|
||||
📅 {{ lang.t("source.file.date.updated") }}:
|
||||
{{ page.meta.git_revision_date_localized }}
|
||||
{% if page.meta.git_creation_date_localized %}
|
||||
<br/>
|
||||
🎂 {{ lang.t("source.file.date.created") }}:
|
||||
{{ page.meta.git_creation_date_localized }}
|
||||
{% endif %}
|
||||
|
||||
<!-- mkdocs-git-revision-date-plugin -->
|
||||
{% elif page.meta.revision_date %}
|
||||
📅 {{ lang.t("source.file.date.updated") }}:
|
||||
{{ page.meta.revision_date }}
|
||||
{% endif %}
|
||||
</small>
|
||||
</div>
|
||||
135
docs/quickstart.md
Normal file
135
docs/quickstart.md
Normal file
@ -0,0 +1,135 @@
|
||||
---
|
||||
comments: true
|
||||
description: Install and use YOLOv8 via CLI or Python. Run single-line commands or integrate with Python projects for object detection, segmentation, and classification.
|
||||
---
|
||||
|
||||
## Install
|
||||
|
||||
Install YOLOv8 via the `ultralytics` pip package for the latest stable release or by cloning
|
||||
the [https://github.com/ultralytics/ultralytics](https://github.com/ultralytics/ultralytics) repository for the most
|
||||
up-to-date version.
|
||||
|
||||
!!! example "Install"
|
||||
|
||||
=== "pip install (recommended)"
|
||||
```bash
|
||||
pip install ultralytics
|
||||
```
|
||||
|
||||
=== "git clone (for development)"
|
||||
```bash
|
||||
git clone https://github.com/ultralytics/ultralytics
|
||||
cd ultralytics
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
See the `ultralytics` [requirements.txt](https://github.com/ultralytics/ultralytics/blob/main/requirements.txt) file for a list of dependencies. Note that `pip` automatically installs all required dependencies.
|
||||
|
||||
!!! tip "Tip"
|
||||
|
||||
PyTorch requirements vary by operating system and CUDA requirements, so it's recommended to install PyTorch first following instructions at [https://pytorch.org/get-started/locally](https://pytorch.org/get-started/locally).
|
||||
|
||||
<a href="https://pytorch.org/get-started/locally/">
|
||||
<img width="800" alt="PyTorch Installation Instructions" src="https://user-images.githubusercontent.com/26833433/228650108-ab0ec98a-b328-4f40-a40d-95355e8a84e3.png">
|
||||
</a>
|
||||
|
||||
## Use with CLI
|
||||
|
||||
The YOLO command line interface (CLI) allows for simple single-line commands without the need for a Python environment.
|
||||
CLI requires no customization or Python code. You can simply run all tasks from the terminal with the `yolo` command. Check out the [CLI Guide](usage/cli.md) to learn more about using YOLOv8 from the command line.
|
||||
|
||||
!!! example
|
||||
|
||||
=== "Syntax"
|
||||
|
||||
Ultralytics `yolo` commands use the following syntax:
|
||||
```bash
|
||||
yolo TASK MODE ARGS
|
||||
|
||||
Where TASK (optional) is one of [detect, segment, classify]
|
||||
MODE (required) is one of [train, val, predict, export, track]
|
||||
ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.
|
||||
```
|
||||
See all ARGS in the full [Configuration Guide](usage/cfg.md) or with `yolo cfg`
|
||||
|
||||
=== "Train"
|
||||
|
||||
Train a detection model for 10 epochs with an initial learning_rate of 0.01
|
||||
```bash
|
||||
yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
|
||||
```
|
||||
|
||||
=== "Predict"
|
||||
|
||||
Predict a YouTube video using a pretrained segmentation model at image size 320:
|
||||
```bash
|
||||
yolo predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320
|
||||
```
|
||||
|
||||
=== "Val"
|
||||
|
||||
Val a pretrained detection model at batch-size 1 and image size 640:
|
||||
```bash
|
||||
yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640
|
||||
```
|
||||
|
||||
=== "Export"
|
||||
|
||||
Export a YOLOv8n classification model to ONNX format at image size 224 by 128 (no TASK required)
|
||||
```bash
|
||||
yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128
|
||||
```
|
||||
|
||||
=== "Special"
|
||||
|
||||
Run special commands to see version, view settings, run checks and more:
|
||||
```bash
|
||||
yolo help
|
||||
yolo checks
|
||||
yolo version
|
||||
yolo settings
|
||||
yolo copy-cfg
|
||||
yolo cfg
|
||||
```
|
||||
|
||||
!!! warning "Warning"
|
||||
|
||||
Arguments must be passed as `arg=val` pairs, split by an equals `=` sign and delimited by spaces ` ` between pairs. Do not use `--` argument prefixes or commas `,` between arguments.
|
||||
|
||||
- `yolo predict model=yolov8n.pt imgsz=640 conf=0.25` ✅
|
||||
- `yolo predict model yolov8n.pt imgsz 640 conf 0.25` ❌
|
||||
- `yolo predict --model yolov8n.pt --imgsz 640 --conf 0.25` ❌
|
||||
|
||||
[CLI Guide](usage/cli.md){ .md-button .md-button--primary}
|
||||
|
||||
## Use with Python
|
||||
|
||||
YOLOv8's Python interface allows for seamless integration into your Python projects, making it easy to load, run, and process the model's output. Designed with simplicity and ease of use in mind, the Python interface enables users to quickly implement object detection, segmentation, and classification in their projects. This makes YOLOv8's Python interface an invaluable tool for anyone looking to incorporate these functionalities into their Python projects.
|
||||
|
||||
For example, users can load a model, train it, evaluate its performance on a validation set, and even export it to ONNX format with just a few lines of code. Check out the [Python Guide](usage/python.md) to learn more about using YOLOv8 within your Python projects.
|
||||
|
||||
!!! example
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Create a new YOLO model from scratch
|
||||
model = YOLO('yolov8n.yaml')
|
||||
|
||||
# Load a pretrained YOLO model (recommended for training)
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Train the model using the 'coco128.yaml' dataset for 3 epochs
|
||||
results = model.train(data='coco128.yaml', epochs=3)
|
||||
|
||||
# Evaluate the model's performance on the validation set
|
||||
results = model.val()
|
||||
|
||||
# Perform object detection on an image using the model
|
||||
results = model('https://ultralytics.com/images/bus.jpg')
|
||||
|
||||
# Export the model to ONNX format
|
||||
success = model.export(format='onnx')
|
||||
```
|
||||
|
||||
[Python Guide](usage/python.md){.md-button .md-button--primary}
|
||||
8
docs/reference/hub/auth.md
Normal file
8
docs/reference/hub/auth.md
Normal file
@ -0,0 +1,8 @@
|
||||
---
|
||||
description: Learn how to use Ultralytics hub authentication in your projects with examples and guidelines from the Auth page on Ultralytics Docs.
|
||||
---
|
||||
|
||||
# Auth
|
||||
---
|
||||
:::ultralytics.hub.auth.Auth
|
||||
<br><br>
|
||||
8
docs/reference/hub/session.md
Normal file
8
docs/reference/hub/session.md
Normal file
@ -0,0 +1,8 @@
|
||||
---
|
||||
description: Accelerate your AI development with the Ultralytics HUB Training Session. High-performance training of object detection models.
|
||||
---
|
||||
|
||||
# HUBTrainingSession
|
||||
---
|
||||
:::ultralytics.hub.session.HUBTrainingSession
|
||||
<br><br>
|
||||
23
docs/reference/hub/utils.md
Normal file
23
docs/reference/hub/utils.md
Normal file
@ -0,0 +1,23 @@
|
||||
---
|
||||
description: Explore Ultralytics events, including 'request_with_credentials' and 'smart_request', to improve your project's performance and efficiency.
|
||||
---
|
||||
|
||||
# Events
|
||||
---
|
||||
:::ultralytics.hub.utils.Events
|
||||
<br><br>
|
||||
|
||||
# request_with_credentials
|
||||
---
|
||||
:::ultralytics.hub.utils.request_with_credentials
|
||||
<br><br>
|
||||
|
||||
# requests_with_progress
|
||||
---
|
||||
:::ultralytics.hub.utils.requests_with_progress
|
||||
<br><br>
|
||||
|
||||
# smart_request
|
||||
---
|
||||
:::ultralytics.hub.utils.smart_request
|
||||
<br><br>
|
||||
13
docs/reference/nn/autobackend.md
Normal file
13
docs/reference/nn/autobackend.md
Normal file
@ -0,0 +1,13 @@
|
||||
---
|
||||
description: Ensure class names match filenames for easy imports. Use AutoBackend to automatically rename and refactor model files.
|
||||
---
|
||||
|
||||
# AutoBackend
|
||||
---
|
||||
:::ultralytics.nn.autobackend.AutoBackend
|
||||
<br><br>
|
||||
|
||||
# check_class_names
|
||||
---
|
||||
:::ultralytics.nn.autobackend.check_class_names
|
||||
<br><br>
|
||||
13
docs/reference/nn/autoshape.md
Normal file
13
docs/reference/nn/autoshape.md
Normal file
@ -0,0 +1,13 @@
|
||||
---
|
||||
description: Detect 80+ object categories with bounding box coordinates and class probabilities using AutoShape in Ultralytics YOLO. Explore Detections now.
|
||||
---
|
||||
|
||||
# AutoShape
|
||||
---
|
||||
:::ultralytics.nn.autoshape.AutoShape
|
||||
<br><br>
|
||||
|
||||
# Detections
|
||||
---
|
||||
:::ultralytics.nn.autoshape.Detections
|
||||
<br><br>
|
||||
88
docs/reference/nn/modules/block.md
Normal file
88
docs/reference/nn/modules/block.md
Normal file
@ -0,0 +1,88 @@
|
||||
---
|
||||
description: Explore ultralytics.nn.modules.block to build powerful YOLO object detection models. Master DFL, HGStem, SPP, CSP components and more.
|
||||
---
|
||||
|
||||
# DFL
|
||||
---
|
||||
:::ultralytics.nn.modules.block.DFL
|
||||
<br><br>
|
||||
|
||||
# Proto
|
||||
---
|
||||
:::ultralytics.nn.modules.block.Proto
|
||||
<br><br>
|
||||
|
||||
# HGStem
|
||||
---
|
||||
:::ultralytics.nn.modules.block.HGStem
|
||||
<br><br>
|
||||
|
||||
# HGBlock
|
||||
---
|
||||
:::ultralytics.nn.modules.block.HGBlock
|
||||
<br><br>
|
||||
|
||||
# SPP
|
||||
---
|
||||
:::ultralytics.nn.modules.block.SPP
|
||||
<br><br>
|
||||
|
||||
# SPPF
|
||||
---
|
||||
:::ultralytics.nn.modules.block.SPPF
|
||||
<br><br>
|
||||
|
||||
# C1
|
||||
---
|
||||
:::ultralytics.nn.modules.block.C1
|
||||
<br><br>
|
||||
|
||||
# C2
|
||||
---
|
||||
:::ultralytics.nn.modules.block.C2
|
||||
<br><br>
|
||||
|
||||
# C2f
|
||||
---
|
||||
:::ultralytics.nn.modules.block.C2f
|
||||
<br><br>
|
||||
|
||||
# C3
|
||||
---
|
||||
:::ultralytics.nn.modules.block.C3
|
||||
<br><br>
|
||||
|
||||
# C3x
|
||||
---
|
||||
:::ultralytics.nn.modules.block.C3x
|
||||
<br><br>
|
||||
|
||||
# RepC3
|
||||
---
|
||||
:::ultralytics.nn.modules.block.RepC3
|
||||
<br><br>
|
||||
|
||||
# C3TR
|
||||
---
|
||||
:::ultralytics.nn.modules.block.C3TR
|
||||
<br><br>
|
||||
|
||||
# C3Ghost
|
||||
---
|
||||
:::ultralytics.nn.modules.block.C3Ghost
|
||||
<br><br>
|
||||
|
||||
# GhostBottleneck
|
||||
---
|
||||
:::ultralytics.nn.modules.block.GhostBottleneck
|
||||
<br><br>
|
||||
|
||||
# Bottleneck
|
||||
---
|
||||
:::ultralytics.nn.modules.block.Bottleneck
|
||||
<br><br>
|
||||
|
||||
# BottleneckCSP
|
||||
---
|
||||
:::ultralytics.nn.modules.block.BottleneckCSP
|
||||
<br><br>
|
||||
68
docs/reference/nn/modules/conv.md
Normal file
68
docs/reference/nn/modules/conv.md
Normal file
@ -0,0 +1,68 @@
|
||||
---
|
||||
description: Explore convolutional neural network modules & techniques such as LightConv, DWConv, ConvTranspose, GhostConv, CBAM & autopad with Ultralytics Docs.
|
||||
---
|
||||
|
||||
# Conv
|
||||
---
|
||||
:::ultralytics.nn.modules.conv.Conv
|
||||
<br><br>
|
||||
|
||||
# LightConv
|
||||
---
|
||||
:::ultralytics.nn.modules.conv.LightConv
|
||||
<br><br>
|
||||
|
||||
# DWConv
|
||||
---
|
||||
:::ultralytics.nn.modules.conv.DWConv
|
||||
<br><br>
|
||||
|
||||
# DWConvTranspose2d
|
||||
---
|
||||
:::ultralytics.nn.modules.conv.DWConvTranspose2d
|
||||
<br><br>
|
||||
|
||||
# ConvTranspose
|
||||
---
|
||||
:::ultralytics.nn.modules.conv.ConvTranspose
|
||||
<br><br>
|
||||
|
||||
# Focus
|
||||
---
|
||||
:::ultralytics.nn.modules.conv.Focus
|
||||
<br><br>
|
||||
|
||||
# GhostConv
|
||||
---
|
||||
:::ultralytics.nn.modules.conv.GhostConv
|
||||
<br><br>
|
||||
|
||||
# RepConv
|
||||
---
|
||||
:::ultralytics.nn.modules.conv.RepConv
|
||||
<br><br>
|
||||
|
||||
# ChannelAttention
|
||||
---
|
||||
:::ultralytics.nn.modules.conv.ChannelAttention
|
||||
<br><br>
|
||||
|
||||
# SpatialAttention
|
||||
---
|
||||
:::ultralytics.nn.modules.conv.SpatialAttention
|
||||
<br><br>
|
||||
|
||||
# CBAM
|
||||
---
|
||||
:::ultralytics.nn.modules.conv.CBAM
|
||||
<br><br>
|
||||
|
||||
# Concat
|
||||
---
|
||||
:::ultralytics.nn.modules.conv.Concat
|
||||
<br><br>
|
||||
|
||||
# autopad
|
||||
---
|
||||
:::ultralytics.nn.modules.conv.autopad
|
||||
<br><br>
|
||||
28
docs/reference/nn/modules/head.md
Normal file
28
docs/reference/nn/modules/head.md
Normal file
@ -0,0 +1,28 @@
|
||||
---
|
||||
description: 'Learn about Ultralytics YOLO modules: Segment, Classify, and RTDETRDecoder. Optimize object detection and classification in your project.'
|
||||
---
|
||||
|
||||
# Detect
|
||||
---
|
||||
:::ultralytics.nn.modules.head.Detect
|
||||
<br><br>
|
||||
|
||||
# Segment
|
||||
---
|
||||
:::ultralytics.nn.modules.head.Segment
|
||||
<br><br>
|
||||
|
||||
# Pose
|
||||
---
|
||||
:::ultralytics.nn.modules.head.Pose
|
||||
<br><br>
|
||||
|
||||
# Classify
|
||||
---
|
||||
:::ultralytics.nn.modules.head.Classify
|
||||
<br><br>
|
||||
|
||||
# RTDETRDecoder
|
||||
---
|
||||
:::ultralytics.nn.modules.head.RTDETRDecoder
|
||||
<br><br>
|
||||
53
docs/reference/nn/modules/transformer.md
Normal file
53
docs/reference/nn/modules/transformer.md
Normal file
@ -0,0 +1,53 @@
|
||||
---
|
||||
description: Explore the Ultralytics nn modules pages on Transformer and MLP blocks, LayerNorm2d, and Deformable Transformer Decoder Layer.
|
||||
---
|
||||
|
||||
# TransformerEncoderLayer
|
||||
---
|
||||
:::ultralytics.nn.modules.transformer.TransformerEncoderLayer
|
||||
<br><br>
|
||||
|
||||
# AIFI
|
||||
---
|
||||
:::ultralytics.nn.modules.transformer.AIFI
|
||||
<br><br>
|
||||
|
||||
# TransformerLayer
|
||||
---
|
||||
:::ultralytics.nn.modules.transformer.TransformerLayer
|
||||
<br><br>
|
||||
|
||||
# TransformerBlock
|
||||
---
|
||||
:::ultralytics.nn.modules.transformer.TransformerBlock
|
||||
<br><br>
|
||||
|
||||
# MLPBlock
|
||||
---
|
||||
:::ultralytics.nn.modules.transformer.MLPBlock
|
||||
<br><br>
|
||||
|
||||
# MLP
|
||||
---
|
||||
:::ultralytics.nn.modules.transformer.MLP
|
||||
<br><br>
|
||||
|
||||
# LayerNorm2d
|
||||
---
|
||||
:::ultralytics.nn.modules.transformer.LayerNorm2d
|
||||
<br><br>
|
||||
|
||||
# MSDeformAttn
|
||||
---
|
||||
:::ultralytics.nn.modules.transformer.MSDeformAttn
|
||||
<br><br>
|
||||
|
||||
# DeformableTransformerDecoderLayer
|
||||
---
|
||||
:::ultralytics.nn.modules.transformer.DeformableTransformerDecoderLayer
|
||||
<br><br>
|
||||
|
||||
# DeformableTransformerDecoder
|
||||
---
|
||||
:::ultralytics.nn.modules.transformer.DeformableTransformerDecoder
|
||||
<br><br>
|
||||
28
docs/reference/nn/modules/utils.md
Normal file
28
docs/reference/nn/modules/utils.md
Normal file
@ -0,0 +1,28 @@
|
||||
---
|
||||
description: 'Learn about Ultralytics NN modules: get_clones, linear_init_, and multi_scale_deformable_attn_pytorch. Code examples and usage tips.'
|
||||
---
|
||||
|
||||
# _get_clones
|
||||
---
|
||||
:::ultralytics.nn.modules.utils._get_clones
|
||||
<br><br>
|
||||
|
||||
# bias_init_with_prob
|
||||
---
|
||||
:::ultralytics.nn.modules.utils.bias_init_with_prob
|
||||
<br><br>
|
||||
|
||||
# linear_init_
|
||||
---
|
||||
:::ultralytics.nn.modules.utils.linear_init_
|
||||
<br><br>
|
||||
|
||||
# inverse_sigmoid
|
||||
---
|
||||
:::ultralytics.nn.modules.utils.inverse_sigmoid
|
||||
<br><br>
|
||||
|
||||
# multi_scale_deformable_attn_pytorch
|
||||
---
|
||||
:::ultralytics.nn.modules.utils.multi_scale_deformable_attn_pytorch
|
||||
<br><br>
|
||||
68
docs/reference/nn/tasks.md
Normal file
68
docs/reference/nn/tasks.md
Normal file
@ -0,0 +1,68 @@
|
||||
---
|
||||
description: Learn how to work with Ultralytics YOLO Detection, Segmentation & Classification Models, load weights and parse models in PyTorch.
|
||||
---
|
||||
|
||||
# BaseModel
|
||||
---
|
||||
:::ultralytics.nn.tasks.BaseModel
|
||||
<br><br>
|
||||
|
||||
# DetectionModel
|
||||
---
|
||||
:::ultralytics.nn.tasks.DetectionModel
|
||||
<br><br>
|
||||
|
||||
# SegmentationModel
|
||||
---
|
||||
:::ultralytics.nn.tasks.SegmentationModel
|
||||
<br><br>
|
||||
|
||||
# PoseModel
|
||||
---
|
||||
:::ultralytics.nn.tasks.PoseModel
|
||||
<br><br>
|
||||
|
||||
# ClassificationModel
|
||||
---
|
||||
:::ultralytics.nn.tasks.ClassificationModel
|
||||
<br><br>
|
||||
|
||||
# Ensemble
|
||||
---
|
||||
:::ultralytics.nn.tasks.Ensemble
|
||||
<br><br>
|
||||
|
||||
# torch_safe_load
|
||||
---
|
||||
:::ultralytics.nn.tasks.torch_safe_load
|
||||
<br><br>
|
||||
|
||||
# attempt_load_weights
|
||||
---
|
||||
:::ultralytics.nn.tasks.attempt_load_weights
|
||||
<br><br>
|
||||
|
||||
# attempt_load_one_weight
|
||||
---
|
||||
:::ultralytics.nn.tasks.attempt_load_one_weight
|
||||
<br><br>
|
||||
|
||||
# parse_model
|
||||
---
|
||||
:::ultralytics.nn.tasks.parse_model
|
||||
<br><br>
|
||||
|
||||
# yaml_model_load
|
||||
---
|
||||
:::ultralytics.nn.tasks.yaml_model_load
|
||||
<br><br>
|
||||
|
||||
# guess_model_scale
|
||||
---
|
||||
:::ultralytics.nn.tasks.guess_model_scale
|
||||
<br><br>
|
||||
|
||||
# guess_model_task
|
||||
---
|
||||
:::ultralytics.nn.tasks.guess_model_task
|
||||
<br><br>
|
||||
18
docs/reference/tracker/track.md
Normal file
18
docs/reference/tracker/track.md
Normal file
@ -0,0 +1,18 @@
|
||||
---
|
||||
description: Learn how to register custom event-tracking and track predictions with Ultralytics YOLO via on_predict_start and register_tracker methods.
|
||||
---
|
||||
|
||||
# on_predict_start
|
||||
---
|
||||
:::ultralytics.tracker.track.on_predict_start
|
||||
<br><br>
|
||||
|
||||
# on_predict_postprocess_end
|
||||
---
|
||||
:::ultralytics.tracker.track.on_predict_postprocess_end
|
||||
<br><br>
|
||||
|
||||
# register_tracker
|
||||
---
|
||||
:::ultralytics.tracker.track.register_tracker
|
||||
<br><br>
|
||||
13
docs/reference/tracker/trackers/basetrack.md
Normal file
13
docs/reference/tracker/trackers/basetrack.md
Normal file
@ -0,0 +1,13 @@
|
||||
---
|
||||
description: 'TrackState: A comprehensive guide to Ultralytics tracker''s BaseTrack for monitoring model performance. Improve your tracking capabilities now!'
|
||||
---
|
||||
|
||||
# TrackState
|
||||
---
|
||||
:::ultralytics.tracker.trackers.basetrack.TrackState
|
||||
<br><br>
|
||||
|
||||
# BaseTrack
|
||||
---
|
||||
:::ultralytics.tracker.trackers.basetrack.BaseTrack
|
||||
<br><br>
|
||||
13
docs/reference/tracker/trackers/bot_sort.md
Normal file
13
docs/reference/tracker/trackers/bot_sort.md
Normal file
@ -0,0 +1,13 @@
|
||||
---
|
||||
description: '"Optimize tracking with Ultralytics BOTrack. Easily sort and track bots with BOTSORT. Streamline data collection for improved performance."'
|
||||
---
|
||||
|
||||
# BOTrack
|
||||
---
|
||||
:::ultralytics.tracker.trackers.bot_sort.BOTrack
|
||||
<br><br>
|
||||
|
||||
# BOTSORT
|
||||
---
|
||||
:::ultralytics.tracker.trackers.bot_sort.BOTSORT
|
||||
<br><br>
|
||||
13
docs/reference/tracker/trackers/byte_tracker.md
Normal file
13
docs/reference/tracker/trackers/byte_tracker.md
Normal file
@ -0,0 +1,13 @@
|
||||
---
|
||||
description: Learn how to track ByteAI model sizes and tips for model optimization with STrack, a byte tracking tool from Ultralytics.
|
||||
---
|
||||
|
||||
# STrack
|
||||
---
|
||||
:::ultralytics.tracker.trackers.byte_tracker.STrack
|
||||
<br><br>
|
||||
|
||||
# BYTETracker
|
||||
---
|
||||
:::ultralytics.tracker.trackers.byte_tracker.BYTETracker
|
||||
<br><br>
|
||||
8
docs/reference/tracker/utils/gmc.md
Normal file
8
docs/reference/tracker/utils/gmc.md
Normal file
@ -0,0 +1,8 @@
|
||||
---
|
||||
description: '"Track Google Marketing Campaigns in GMC with Ultralytics Tracker. Learn to set up and use GMC for detailed analytics. Get started now."'
|
||||
---
|
||||
|
||||
# GMC
|
||||
---
|
||||
:::ultralytics.tracker.utils.gmc.GMC
|
||||
<br><br>
|
||||
13
docs/reference/tracker/utils/kalman_filter.md
Normal file
13
docs/reference/tracker/utils/kalman_filter.md
Normal file
@ -0,0 +1,13 @@
|
||||
---
|
||||
description: Improve object tracking with KalmanFilterXYAH in Ultralytics YOLO - an efficient and accurate algorithm for state estimation.
|
||||
---
|
||||
|
||||
# KalmanFilterXYAH
|
||||
---
|
||||
:::ultralytics.tracker.utils.kalman_filter.KalmanFilterXYAH
|
||||
<br><br>
|
||||
|
||||
# KalmanFilterXYWH
|
||||
---
|
||||
:::ultralytics.tracker.utils.kalman_filter.KalmanFilterXYWH
|
||||
<br><br>
|
||||
63
docs/reference/tracker/utils/matching.md
Normal file
63
docs/reference/tracker/utils/matching.md
Normal file
@ -0,0 +1,63 @@
|
||||
---
|
||||
description: Learn how to match and fuse object detections for accurate target tracking using Ultralytics' YOLO merge_matches, iou_distance, and embedding_distance.
|
||||
---
|
||||
|
||||
# merge_matches
|
||||
---
|
||||
:::ultralytics.tracker.utils.matching.merge_matches
|
||||
<br><br>
|
||||
|
||||
# _indices_to_matches
|
||||
---
|
||||
:::ultralytics.tracker.utils.matching._indices_to_matches
|
||||
<br><br>
|
||||
|
||||
# linear_assignment
|
||||
---
|
||||
:::ultralytics.tracker.utils.matching.linear_assignment
|
||||
<br><br>
|
||||
|
||||
# ious
|
||||
---
|
||||
:::ultralytics.tracker.utils.matching.ious
|
||||
<br><br>
|
||||
|
||||
# iou_distance
|
||||
---
|
||||
:::ultralytics.tracker.utils.matching.iou_distance
|
||||
<br><br>
|
||||
|
||||
# v_iou_distance
|
||||
---
|
||||
:::ultralytics.tracker.utils.matching.v_iou_distance
|
||||
<br><br>
|
||||
|
||||
# embedding_distance
|
||||
---
|
||||
:::ultralytics.tracker.utils.matching.embedding_distance
|
||||
<br><br>
|
||||
|
||||
# gate_cost_matrix
|
||||
---
|
||||
:::ultralytics.tracker.utils.matching.gate_cost_matrix
|
||||
<br><br>
|
||||
|
||||
# fuse_motion
|
||||
---
|
||||
:::ultralytics.tracker.utils.matching.fuse_motion
|
||||
<br><br>
|
||||
|
||||
# fuse_iou
|
||||
---
|
||||
:::ultralytics.tracker.utils.matching.fuse_iou
|
||||
<br><br>
|
||||
|
||||
# fuse_score
|
||||
---
|
||||
:::ultralytics.tracker.utils.matching.fuse_score
|
||||
<br><br>
|
||||
|
||||
# bbox_ious
|
||||
---
|
||||
:::ultralytics.tracker.utils.matching.bbox_ious
|
||||
<br><br>
|
||||
8
docs/reference/yolo/data/annotator.md
Normal file
8
docs/reference/yolo/data/annotator.md
Normal file
@ -0,0 +1,8 @@
|
||||
---
|
||||
description: Learn how to use auto_annotate in Ultralytics YOLO to generate annotations automatically for your dataset. Simplify object detection workflows.
|
||||
---
|
||||
|
||||
# auto_annotate
|
||||
---
|
||||
:::ultralytics.yolo.data.annotator.auto_annotate
|
||||
<br><br>
|
||||
93
docs/reference/yolo/data/augment.md
Normal file
93
docs/reference/yolo/data/augment.md
Normal file
@ -0,0 +1,93 @@
|
||||
---
|
||||
description: Use Ultralytics YOLO Data Augmentation transforms with Base, MixUp, and Albumentations for object detection and classification.
|
||||
---
|
||||
|
||||
# BaseTransform
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.BaseTransform
|
||||
<br><br>
|
||||
|
||||
# Compose
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.Compose
|
||||
<br><br>
|
||||
|
||||
# BaseMixTransform
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.BaseMixTransform
|
||||
<br><br>
|
||||
|
||||
# Mosaic
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.Mosaic
|
||||
<br><br>
|
||||
|
||||
# MixUp
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.MixUp
|
||||
<br><br>
|
||||
|
||||
# RandomPerspective
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.RandomPerspective
|
||||
<br><br>
|
||||
|
||||
# RandomHSV
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.RandomHSV
|
||||
<br><br>
|
||||
|
||||
# RandomFlip
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.RandomFlip
|
||||
<br><br>
|
||||
|
||||
# LetterBox
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.LetterBox
|
||||
<br><br>
|
||||
|
||||
# CopyPaste
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.CopyPaste
|
||||
<br><br>
|
||||
|
||||
# Albumentations
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.Albumentations
|
||||
<br><br>
|
||||
|
||||
# Format
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.Format
|
||||
<br><br>
|
||||
|
||||
# ClassifyLetterBox
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.ClassifyLetterBox
|
||||
<br><br>
|
||||
|
||||
# CenterCrop
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.CenterCrop
|
||||
<br><br>
|
||||
|
||||
# ToTensor
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.ToTensor
|
||||
<br><br>
|
||||
|
||||
# v8_transforms
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.v8_transforms
|
||||
<br><br>
|
||||
|
||||
# classify_transforms
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.classify_transforms
|
||||
<br><br>
|
||||
|
||||
# classify_albumentations
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.classify_albumentations
|
||||
<br><br>
|
||||
8
docs/reference/yolo/data/base.md
Normal file
8
docs/reference/yolo/data/base.md
Normal file
@ -0,0 +1,8 @@
|
||||
---
|
||||
description: Learn about BaseDataset in Ultralytics YOLO, a flexible dataset class for object detection. Maximize your YOLO performance with custom datasets.
|
||||
---
|
||||
|
||||
# BaseDataset
|
||||
---
|
||||
:::ultralytics.yolo.data.base.BaseDataset
|
||||
<br><br>
|
||||
38
docs/reference/yolo/data/build.md
Normal file
38
docs/reference/yolo/data/build.md
Normal file
@ -0,0 +1,38 @@
|
||||
---
|
||||
description: Maximize YOLO performance with Ultralytics' InfiniteDataLoader, seed_worker, build_dataloader, and load_inference_source functions.
|
||||
---
|
||||
|
||||
# InfiniteDataLoader
|
||||
---
|
||||
:::ultralytics.yolo.data.build.InfiniteDataLoader
|
||||
<br><br>
|
||||
|
||||
# _RepeatSampler
|
||||
---
|
||||
:::ultralytics.yolo.data.build._RepeatSampler
|
||||
<br><br>
|
||||
|
||||
# seed_worker
|
||||
---
|
||||
:::ultralytics.yolo.data.build.seed_worker
|
||||
<br><br>
|
||||
|
||||
# build_yolo_dataset
|
||||
---
|
||||
:::ultralytics.yolo.data.build.build_yolo_dataset
|
||||
<br><br>
|
||||
|
||||
# build_dataloader
|
||||
---
|
||||
:::ultralytics.yolo.data.build.build_dataloader
|
||||
<br><br>
|
||||
|
||||
# check_source
|
||||
---
|
||||
:::ultralytics.yolo.data.build.check_source
|
||||
<br><br>
|
||||
|
||||
# load_inference_source
|
||||
---
|
||||
:::ultralytics.yolo.data.build.load_inference_source
|
||||
<br><br>
|
||||
33
docs/reference/yolo/data/converter.md
Normal file
33
docs/reference/yolo/data/converter.md
Normal file
@ -0,0 +1,33 @@
|
||||
---
|
||||
description: Convert COCO-91 to COCO-80 class, RLE to polygon, and merge multi-segment images with Ultralytics YOLO data converter. Improve your object detection.
|
||||
---
|
||||
|
||||
# coco91_to_coco80_class
|
||||
---
|
||||
:::ultralytics.yolo.data.converter.coco91_to_coco80_class
|
||||
<br><br>
|
||||
|
||||
# convert_coco
|
||||
---
|
||||
:::ultralytics.yolo.data.converter.convert_coco
|
||||
<br><br>
|
||||
|
||||
# rle2polygon
|
||||
---
|
||||
:::ultralytics.yolo.data.converter.rle2polygon
|
||||
<br><br>
|
||||
|
||||
# min_index
|
||||
---
|
||||
:::ultralytics.yolo.data.converter.min_index
|
||||
<br><br>
|
||||
|
||||
# merge_multi_segment
|
||||
---
|
||||
:::ultralytics.yolo.data.converter.merge_multi_segment
|
||||
<br><br>
|
||||
|
||||
# delete_dsstore
|
||||
---
|
||||
:::ultralytics.yolo.data.converter.delete_dsstore
|
||||
<br><br>
|
||||
38
docs/reference/yolo/data/dataloaders/stream_loaders.md
Normal file
38
docs/reference/yolo/data/dataloaders/stream_loaders.md
Normal file
@ -0,0 +1,38 @@
|
||||
---
|
||||
description: 'Ultralytics YOLO Docs: Learn about stream loaders for image and tensor data, as well as autocasting techniques. Check out SourceTypes and more.'
|
||||
---
|
||||
|
||||
# SourceTypes
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.stream_loaders.SourceTypes
|
||||
<br><br>
|
||||
|
||||
# LoadStreams
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.stream_loaders.LoadStreams
|
||||
<br><br>
|
||||
|
||||
# LoadScreenshots
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.stream_loaders.LoadScreenshots
|
||||
<br><br>
|
||||
|
||||
# LoadImages
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.stream_loaders.LoadImages
|
||||
<br><br>
|
||||
|
||||
# LoadPilAndNumpy
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.stream_loaders.LoadPilAndNumpy
|
||||
<br><br>
|
||||
|
||||
# LoadTensor
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.stream_loaders.LoadTensor
|
||||
<br><br>
|
||||
|
||||
# autocast_list
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.stream_loaders.autocast_list
|
||||
<br><br>
|
||||
88
docs/reference/yolo/data/dataloaders/v5augmentations.md
Normal file
88
docs/reference/yolo/data/dataloaders/v5augmentations.md
Normal file
@ -0,0 +1,88 @@
|
||||
---
|
||||
description: Enhance image data with Albumentations CenterCrop, normalize, augment_hsv, replicate, random_perspective, cutout, & box_candidates.
|
||||
---
|
||||
|
||||
# Albumentations
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.Albumentations
|
||||
<br><br>
|
||||
|
||||
# LetterBox
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.LetterBox
|
||||
<br><br>
|
||||
|
||||
# CenterCrop
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.CenterCrop
|
||||
<br><br>
|
||||
|
||||
# ToTensor
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.ToTensor
|
||||
<br><br>
|
||||
|
||||
# normalize
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.normalize
|
||||
<br><br>
|
||||
|
||||
# denormalize
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.denormalize
|
||||
<br><br>
|
||||
|
||||
# augment_hsv
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.augment_hsv
|
||||
<br><br>
|
||||
|
||||
# hist_equalize
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.hist_equalize
|
||||
<br><br>
|
||||
|
||||
# replicate
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.replicate
|
||||
<br><br>
|
||||
|
||||
# letterbox
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.letterbox
|
||||
<br><br>
|
||||
|
||||
# random_perspective
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.random_perspective
|
||||
<br><br>
|
||||
|
||||
# copy_paste
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.copy_paste
|
||||
<br><br>
|
||||
|
||||
# cutout
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.cutout
|
||||
<br><br>
|
||||
|
||||
# mixup
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.mixup
|
||||
<br><br>
|
||||
|
||||
# box_candidates
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.box_candidates
|
||||
<br><br>
|
||||
|
||||
# classify_albumentations
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.classify_albumentations
|
||||
<br><br>
|
||||
|
||||
# classify_transforms
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.classify_transforms
|
||||
<br><br>
|
||||
93
docs/reference/yolo/data/dataloaders/v5loader.md
Normal file
93
docs/reference/yolo/data/dataloaders/v5loader.md
Normal file
@ -0,0 +1,93 @@
|
||||
---
|
||||
description: Efficiently load images and labels to models using Ultralytics YOLO's InfiniteDataLoader, LoadScreenshots, and LoadStreams.
|
||||
---
|
||||
|
||||
# InfiniteDataLoader
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.InfiniteDataLoader
|
||||
<br><br>
|
||||
|
||||
# _RepeatSampler
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader._RepeatSampler
|
||||
<br><br>
|
||||
|
||||
# LoadScreenshots
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.LoadScreenshots
|
||||
<br><br>
|
||||
|
||||
# LoadImages
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.LoadImages
|
||||
<br><br>
|
||||
|
||||
# LoadStreams
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.LoadStreams
|
||||
<br><br>
|
||||
|
||||
# LoadImagesAndLabels
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.LoadImagesAndLabels
|
||||
<br><br>
|
||||
|
||||
# ClassificationDataset
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.ClassificationDataset
|
||||
<br><br>
|
||||
|
||||
# get_hash
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.get_hash
|
||||
<br><br>
|
||||
|
||||
# exif_size
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.exif_size
|
||||
<br><br>
|
||||
|
||||
# exif_transpose
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.exif_transpose
|
||||
<br><br>
|
||||
|
||||
# seed_worker
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.seed_worker
|
||||
<br><br>
|
||||
|
||||
# create_dataloader
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.create_dataloader
|
||||
<br><br>
|
||||
|
||||
# img2label_paths
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.img2label_paths
|
||||
<br><br>
|
||||
|
||||
# flatten_recursive
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.flatten_recursive
|
||||
<br><br>
|
||||
|
||||
# extract_boxes
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.extract_boxes
|
||||
<br><br>
|
||||
|
||||
# autosplit
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.autosplit
|
||||
<br><br>
|
||||
|
||||
# verify_image_label
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.verify_image_label
|
||||
<br><br>
|
||||
|
||||
# create_classification_dataloader
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.create_classification_dataloader
|
||||
<br><br>
|
||||
18
docs/reference/yolo/data/dataset.md
Normal file
18
docs/reference/yolo/data/dataset.md
Normal file
@ -0,0 +1,18 @@
|
||||
---
|
||||
description: Create custom YOLOv5 datasets with Ultralytics YOLODataset and SemanticDataset. Streamline your object detection and segmentation projects.
|
||||
---
|
||||
|
||||
# YOLODataset
|
||||
---
|
||||
:::ultralytics.yolo.data.dataset.YOLODataset
|
||||
<br><br>
|
||||
|
||||
# ClassificationDataset
|
||||
---
|
||||
:::ultralytics.yolo.data.dataset.ClassificationDataset
|
||||
<br><br>
|
||||
|
||||
# SemanticDataset
|
||||
---
|
||||
:::ultralytics.yolo.data.dataset.SemanticDataset
|
||||
<br><br>
|
||||
8
docs/reference/yolo/data/dataset_wrappers.md
Normal file
8
docs/reference/yolo/data/dataset_wrappers.md
Normal file
@ -0,0 +1,8 @@
|
||||
---
|
||||
description: Create a custom dataset of mixed and oriented rectangular objects with Ultralytics YOLO's MixAndRectDataset.
|
||||
---
|
||||
|
||||
# MixAndRectDataset
|
||||
---
|
||||
:::ultralytics.yolo.data.dataset_wrappers.MixAndRectDataset
|
||||
<br><br>
|
||||
68
docs/reference/yolo/data/utils.md
Normal file
68
docs/reference/yolo/data/utils.md
Normal file
@ -0,0 +1,68 @@
|
||||
---
|
||||
description: Efficiently handle data in YOLO with Ultralytics. Utilize HUBDatasetStats and customize dataset with these data utility functions.
|
||||
---
|
||||
|
||||
# HUBDatasetStats
|
||||
---
|
||||
:::ultralytics.yolo.data.utils.HUBDatasetStats
|
||||
<br><br>
|
||||
|
||||
# img2label_paths
|
||||
---
|
||||
:::ultralytics.yolo.data.utils.img2label_paths
|
||||
<br><br>
|
||||
|
||||
# get_hash
|
||||
---
|
||||
:::ultralytics.yolo.data.utils.get_hash
|
||||
<br><br>
|
||||
|
||||
# exif_size
|
||||
---
|
||||
:::ultralytics.yolo.data.utils.exif_size
|
||||
<br><br>
|
||||
|
||||
# verify_image_label
|
||||
---
|
||||
:::ultralytics.yolo.data.utils.verify_image_label
|
||||
<br><br>
|
||||
|
||||
# polygon2mask
|
||||
---
|
||||
:::ultralytics.yolo.data.utils.polygon2mask
|
||||
<br><br>
|
||||
|
||||
# polygons2masks
|
||||
---
|
||||
:::ultralytics.yolo.data.utils.polygons2masks
|
||||
<br><br>
|
||||
|
||||
# polygons2masks_overlap
|
||||
---
|
||||
:::ultralytics.yolo.data.utils.polygons2masks_overlap
|
||||
<br><br>
|
||||
|
||||
# check_det_dataset
|
||||
---
|
||||
:::ultralytics.yolo.data.utils.check_det_dataset
|
||||
<br><br>
|
||||
|
||||
# check_cls_dataset
|
||||
---
|
||||
:::ultralytics.yolo.data.utils.check_cls_dataset
|
||||
<br><br>
|
||||
|
||||
# compress_one_image
|
||||
---
|
||||
:::ultralytics.yolo.data.utils.compress_one_image
|
||||
<br><br>
|
||||
|
||||
# delete_dsstore
|
||||
---
|
||||
:::ultralytics.yolo.data.utils.delete_dsstore
|
||||
<br><br>
|
||||
|
||||
# zip_directory
|
||||
---
|
||||
:::ultralytics.yolo.data.utils.zip_directory
|
||||
<br><br>
|
||||
33
docs/reference/yolo/engine/exporter.md
Normal file
33
docs/reference/yolo/engine/exporter.md
Normal file
@ -0,0 +1,33 @@
|
||||
---
|
||||
description: Learn how to export your YOLO model in various formats using Ultralytics' exporter package - iOS, GDC, and more.
|
||||
---
|
||||
|
||||
# Exporter
|
||||
---
|
||||
:::ultralytics.yolo.engine.exporter.Exporter
|
||||
<br><br>
|
||||
|
||||
# iOSDetectModel
|
||||
---
|
||||
:::ultralytics.yolo.engine.exporter.iOSDetectModel
|
||||
<br><br>
|
||||
|
||||
# export_formats
|
||||
---
|
||||
:::ultralytics.yolo.engine.exporter.export_formats
|
||||
<br><br>
|
||||
|
||||
# gd_outputs
|
||||
---
|
||||
:::ultralytics.yolo.engine.exporter.gd_outputs
|
||||
<br><br>
|
||||
|
||||
# try_export
|
||||
---
|
||||
:::ultralytics.yolo.engine.exporter.try_export
|
||||
<br><br>
|
||||
|
||||
# export
|
||||
---
|
||||
:::ultralytics.yolo.engine.exporter.export
|
||||
<br><br>
|
||||
8
docs/reference/yolo/engine/model.md
Normal file
8
docs/reference/yolo/engine/model.md
Normal file
@ -0,0 +1,8 @@
|
||||
---
|
||||
description: Discover the YOLO model of Ultralytics engine to simplify your object detection tasks with state-of-the-art models.
|
||||
---
|
||||
|
||||
# YOLO
|
||||
---
|
||||
:::ultralytics.yolo.engine.model.YOLO
|
||||
<br><br>
|
||||
8
docs/reference/yolo/engine/predictor.md
Normal file
8
docs/reference/yolo/engine/predictor.md
Normal file
@ -0,0 +1,8 @@
|
||||
---
|
||||
description: '"The BasePredictor class in Ultralytics YOLO Engine predicts object detection in images and videos. Learn to implement YOLO with ease."'
|
||||
---
|
||||
|
||||
# BasePredictor
|
||||
---
|
||||
:::ultralytics.yolo.engine.predictor.BasePredictor
|
||||
<br><br>
|
||||
23
docs/reference/yolo/engine/results.md
Normal file
23
docs/reference/yolo/engine/results.md
Normal file
@ -0,0 +1,23 @@
|
||||
---
|
||||
description: Learn about BaseTensor & Boxes in Ultralytics YOLO Engine. Check out Ultralytics Docs for quality tutorials and resources on object detection.
|
||||
---
|
||||
|
||||
# BaseTensor
|
||||
---
|
||||
:::ultralytics.yolo.engine.results.BaseTensor
|
||||
<br><br>
|
||||
|
||||
# Results
|
||||
---
|
||||
:::ultralytics.yolo.engine.results.Results
|
||||
<br><br>
|
||||
|
||||
# Boxes
|
||||
---
|
||||
:::ultralytics.yolo.engine.results.Boxes
|
||||
<br><br>
|
||||
|
||||
# Masks
|
||||
---
|
||||
:::ultralytics.yolo.engine.results.Masks
|
||||
<br><br>
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user