mirror of
https://gitee.com/nanjing-yimao-information/ieemoo-ai-gift.git
synced 2025-08-23 23:50:25 +00:00
update
This commit is contained in:
152
docs/en/guides/azureml-quickstart.md
Normal file
152
docs/en/guides/azureml-quickstart.md
Normal file
@ -0,0 +1,152 @@
|
||||
---
|
||||
comments: true
|
||||
description: Step-by-step Quickstart Guide to Running YOLOv8 Object Detection Models on AzureML for Fast Prototyping and Testing
|
||||
keywords: Ultralytics, YOLOv8, Object Detection, Azure Machine Learning, Quickstart Guide, Prototype, Compute Instance, Terminal, Notebook, IPython Kernel, CLI, Python SDK
|
||||
---
|
||||
|
||||
# YOLOv8 🚀 on AzureML
|
||||
|
||||
## What is Azure?
|
||||
|
||||
[Azure](https://azure.microsoft.com/) is Microsoft's cloud computing platform, designed to help organizations move their workloads to the cloud from on-premises data centers. With the full spectrum of cloud services including those for computing, databases, analytics, machine learning, and networking, users can pick and choose from these services to develop and scale new applications, or run existing applications, in the public cloud.
|
||||
|
||||
## What is Azure Machine Learning (AzureML)?
|
||||
|
||||
Azure Machine Learning, commonly referred to as AzureML, is a fully managed cloud service that enables data scientists and developers to efficiently embed predictive analytics into their applications, helping organizations use massive data sets and bring all the benefits of the cloud to machine learning. AzureML offers a variety of services and capabilities aimed at making machine learning accessible, easy to use, and scalable. It provides capabilities like automated machine learning, drag-and-drop model training, as well as a robust Python SDK so that developers can make the most out of their machine learning models.
|
||||
|
||||
## How Does AzureML Benefit YOLO Users?
|
||||
|
||||
For users of YOLO (You Only Look Once), AzureML provides a robust, scalable, and efficient platform to both train and deploy machine learning models. Whether you are looking to run quick prototypes or scale up to handle more extensive data, AzureML's flexible and user-friendly environment offers various tools and services to fit your needs. You can leverage AzureML to:
|
||||
|
||||
- Easily manage large datasets and computational resources for training.
|
||||
- Utilize built-in tools for data preprocessing, feature selection, and model training.
|
||||
- Collaborate more efficiently with capabilities for MLOps (Machine Learning Operations), including but not limited to monitoring, auditing, and versioning of models and data.
|
||||
|
||||
In the subsequent sections, you will find a quickstart guide detailing how to run YOLOv8 object detection models using AzureML, either from a compute terminal or a notebook.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before you can get started, make sure you have access to an AzureML workspace. If you don't have one, you can create a new [AzureML workspace](https://learn.microsoft.com/azure/machine-learning/concept-workspace?view=azureml-api-2) by following Azure's official documentation. This workspace acts as a centralized place to manage all AzureML resources.
|
||||
|
||||
## Create a compute instance
|
||||
|
||||
From your AzureML workspace, select Compute > Compute instances > New, select the instance with the resources you need.
|
||||
|
||||
<p align="center">
|
||||
<img width="1280" src="https://github.com/ouphi/ultralytics/assets/17216799/3e92fcc0-a08e-41a4-af81-d289cfe3b8f2" alt="Create Azure Compute Instance">
|
||||
</p>
|
||||
|
||||
## Quickstart from Terminal
|
||||
|
||||
Start your compute and open a Terminal:
|
||||
|
||||
<p align="center">
|
||||
<img width="480" src="https://github.com/ouphi/ultralytics/assets/17216799/635152f1-f4a3-4261-b111-d416cb5ef357" alt="Open Terminal">
|
||||
</p>
|
||||
|
||||
### Create virtualenv
|
||||
|
||||
Create your conda virtualenv and install pip in it:
|
||||
|
||||
```bash
|
||||
conda create --name yolov8env -y
|
||||
conda activate yolov8env
|
||||
conda install pip -y
|
||||
```
|
||||
|
||||
Install the required dependencies:
|
||||
|
||||
```bash
|
||||
cd ultralytics
|
||||
pip install -r requirements.txt
|
||||
pip install ultralytics
|
||||
pip install onnx>=1.12.0
|
||||
```
|
||||
|
||||
### Perform YOLOv8 tasks
|
||||
|
||||
Predict:
|
||||
|
||||
```bash
|
||||
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
|
||||
```
|
||||
|
||||
Train a detection model for 10 epochs with an initial learning_rate of 0.01:
|
||||
|
||||
```bash
|
||||
yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
|
||||
```
|
||||
|
||||
You can find more [instructions to use the Ultralytics CLI here](../quickstart.md#use-ultralytics-with-cli).
|
||||
|
||||
## Quickstart from a Notebook
|
||||
|
||||
### Create a new IPython kernel
|
||||
|
||||
Open the compute Terminal.
|
||||
|
||||
<p align="center">
|
||||
<img width="480" src="https://github.com/ouphi/ultralytics/assets/17216799/635152f1-f4a3-4261-b111-d416cb5ef357" alt="Open Terminal">
|
||||
</p>
|
||||
|
||||
From your compute terminal, you need to create a new ipykernel that will be used by your notebook to manage your dependencies:
|
||||
|
||||
```bash
|
||||
conda create --name yolov8env -y
|
||||
conda activate yolov8env
|
||||
conda install pip -y
|
||||
conda install ipykernel -y
|
||||
python -m ipykernel install --user --name yolov8env --display-name "yolov8env"
|
||||
```
|
||||
|
||||
Close your terminal and create a new notebook. From your Notebook, you can select the new kernel.
|
||||
|
||||
Then you can open a Notebook cell and install the required dependencies:
|
||||
|
||||
```bash
|
||||
%%bash
|
||||
source activate yolov8env
|
||||
cd ultralytics
|
||||
pip install -r requirements.txt
|
||||
pip install ultralytics
|
||||
pip install onnx>=1.12.0
|
||||
```
|
||||
|
||||
Note that we need to use the `source activate yolov8env` for all the %%bash cells, to make sure that the %%bash cell uses environment we want.
|
||||
|
||||
Run some predictions using the [Ultralytics CLI](../quickstart.md#use-ultralytics-with-cli):
|
||||
|
||||
```bash
|
||||
%%bash
|
||||
source activate yolov8env
|
||||
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
|
||||
```
|
||||
|
||||
Or with the [Ultralytics Python interface](../quickstart.md#use-ultralytics-with-python), for example to train the model:
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO("yolov8n.pt") # load an official YOLOv8n model
|
||||
|
||||
# Use the model
|
||||
model.train(data="coco128.yaml", epochs=3) # train the model
|
||||
metrics = model.val() # evaluate model performance on the validation set
|
||||
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
|
||||
path = model.export(format="onnx") # export the model to ONNX format
|
||||
```
|
||||
|
||||
You can use either the Ultralytics CLI or Python interface for running YOLOv8 tasks, as described in the terminal section above.
|
||||
|
||||
By following these steps, you should be able to get YOLOv8 running quickly on AzureML for quick trials. For more advanced uses, you may refer to the full AzureML documentation linked at the beginning of this guide.
|
||||
|
||||
## Explore More with AzureML
|
||||
|
||||
This guide serves as an introduction to get you up and running with YOLOv8 on AzureML. However, it only scratches the surface of what AzureML can offer. To delve deeper and unlock the full potential of AzureML for your machine learning projects, consider exploring the following resources:
|
||||
|
||||
- [Create a Data Asset](https://learn.microsoft.com/azure/machine-learning/how-to-create-data-assets): Learn how to set up and manage your data assets effectively within the AzureML environment.
|
||||
- [Initiate an AzureML Job](https://learn.microsoft.com/azure/machine-learning/how-to-train-model): Get a comprehensive understanding of how to kickstart your machine learning training jobs on AzureML.
|
||||
- [Register a Model](https://learn.microsoft.com/azure/machine-learning/how-to-manage-models): Familiarize yourself with model management practices including registration, versioning, and deployment.
|
||||
- [Train YOLOv8 with AzureML Python SDK](https://medium.com/@ouphi/how-to-train-the-yolov8-model-with-azure-machine-learning-python-sdk-8268696be8ba): Explore a step-by-step guide on using the AzureML Python SDK to train your YOLOv8 models.
|
||||
- [Train YOLOv8 with AzureML CLI](https://medium.com/@ouphi/how-to-train-the-yolov8-model-with-azureml-and-the-az-cli-73d3c870ba8e): Discover how to utilize the command-line interface for streamlined training and management of YOLOv8 models on AzureML.
|
||||
132
docs/en/guides/conda-quickstart.md
Normal file
132
docs/en/guides/conda-quickstart.md
Normal file
@ -0,0 +1,132 @@
|
||||
---
|
||||
comments: true
|
||||
description: Comprehensive guide to setting up and using Ultralytics YOLO models in a Conda environment. Learn how to install the package, manage dependencies, and get started with object detection projects.
|
||||
keywords: Ultralytics, YOLO, Conda, environment setup, object detection, package installation, deep learning, machine learning, guide
|
||||
---
|
||||
|
||||
# Conda Quickstart Guide for Ultralytics
|
||||
|
||||
<p align="center">
|
||||
<img width="800" src="https://user-images.githubusercontent.com/26833433/266324397-32119e21-8c86-43e5-a00e-79827d303d10.png" alt="Ultralytics Conda Package Visual">
|
||||
</p>
|
||||
|
||||
This guide provides a comprehensive introduction to setting up a Conda environment for your Ultralytics projects. Conda is an open-source package and environment management system that offers an excellent alternative to pip for installing packages and dependencies. Its isolated environments make it particularly well-suited for data science and machine learning endeavors. For more details, visit the Ultralytics Conda package on [Anaconda](https://anaconda.org/conda-forge/ultralytics) and check out the Ultralytics feedstock repository for package updates on [GitHub](https://github.com/conda-forge/ultralytics-feedstock/).
|
||||
|
||||
[](https://anaconda.org/conda-forge/ultralytics) [](https://anaconda.org/conda-forge/ultralytics) [](https://anaconda.org/conda-forge/ultralytics) [](https://anaconda.org/conda-forge/ultralytics)
|
||||
|
||||
## What You Will Learn
|
||||
|
||||
- Setting up a Conda environment
|
||||
- Installing Ultralytics via Conda
|
||||
- Initializing Ultralytics in your environment
|
||||
- Using Ultralytics Docker images with Conda
|
||||
|
||||
---
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You should have Anaconda or Miniconda installed on your system. If not, download and install it from [Anaconda](https://www.anaconda.com/) or [Miniconda](https://docs.conda.io/projects/miniconda/en/latest/).
|
||||
|
||||
---
|
||||
|
||||
## Setting up a Conda Environment
|
||||
|
||||
First, let's create a new Conda environment. Open your terminal and run the following command:
|
||||
|
||||
```bash
|
||||
conda create --name ultralytics-env python=3.8 -y
|
||||
```
|
||||
|
||||
Activate the new environment:
|
||||
|
||||
```bash
|
||||
conda activate ultralytics-env
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Installing Ultralytics
|
||||
|
||||
You can install the Ultralytics package from the conda-forge channel. Execute the following command:
|
||||
|
||||
```bash
|
||||
conda install -c conda-forge ultralytics
|
||||
```
|
||||
|
||||
### Note on CUDA Environment
|
||||
|
||||
If you're working in a CUDA-enabled environment, it's a good practice to install `ultralytics`, `pytorch`, and `pytorch-cuda` together to resolve any conflicts:
|
||||
|
||||
```bash
|
||||
conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Using Ultralytics
|
||||
|
||||
With Ultralytics installed, you can now start using its robust features for object detection, instance segmentation, and more. For example, to predict an image, you can run:
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
model = YOLO('yolov8n.pt') # initialize model
|
||||
results = model('path/to/image.jpg') # perform inference
|
||||
results[0].show() # display results for the first image
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Ultralytics Conda Docker Image
|
||||
|
||||
If you prefer using Docker, Ultralytics offers Docker images with a Conda environment included. You can pull these images from [DockerHub](https://hub.docker.com/r/ultralytics/ultralytics).
|
||||
|
||||
Pull the latest Ultralytics image:
|
||||
|
||||
```bash
|
||||
# Set image name as a variable
|
||||
t=ultralytics/ultralytics:latest-conda
|
||||
|
||||
# Pull the latest Ultralytics image from Docker Hub
|
||||
sudo docker pull $t
|
||||
```
|
||||
|
||||
Run the image:
|
||||
|
||||
```bash
|
||||
# Run the Ultralytics image in a container with GPU support
|
||||
sudo docker run -it --ipc=host --gpus all $t # all GPUs
|
||||
sudo docker run -it --ipc=host --gpus '"device=2,3"' $t # specify GPUs
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
Certainly, you can include the following section in your Conda guide to inform users about speeding up installation using `libmamba`:
|
||||
|
||||
---
|
||||
|
||||
## Speeding Up Installation with Libmamba
|
||||
|
||||
If you're looking to [speed up the package installation](https://www.anaconda.com/blog/a-faster-conda-for-a-growing-community) process in Conda, you can opt to use `libmamba`, a fast, cross-platform, and dependency-aware package manager that serves as an alternative solver to Conda's default.
|
||||
|
||||
### How to Enable Libmamba
|
||||
|
||||
To enable `libmamba` as the solver for Conda, you can perform the following steps:
|
||||
|
||||
1. First, install the `conda-libmamba-solver` package. This can be skipped if your Conda version is 4.11 or above, as `libmamba` is included by default.
|
||||
|
||||
```bash
|
||||
conda install conda-libmamba-solver
|
||||
```
|
||||
|
||||
2. Next, configure Conda to use `libmamba` as the solver:
|
||||
|
||||
```bash
|
||||
conda config --set solver libmamba
|
||||
```
|
||||
|
||||
And that's it! Your Conda installation will now use `libmamba` as the solver, which should result in a faster package installation process.
|
||||
|
||||
---
|
||||
|
||||
Congratulations! You have successfully set up a Conda environment, installed the Ultralytics package, and are now ready to explore its rich functionalities. Feel free to dive deeper into the [Ultralytics documentation](../index.md) for more advanced tutorials and examples.
|
||||
140
docs/en/guides/coral-edge-tpu-on-raspberry-pi.md
Normal file
140
docs/en/guides/coral-edge-tpu-on-raspberry-pi.md
Normal file
@ -0,0 +1,140 @@
|
||||
---
|
||||
comments: true
|
||||
description: Guide on how to use Ultralytics with a Coral Edge TPU on a Raspberry Pi for increased inference performance.
|
||||
keywords: Ultralytics, YOLOv8, Object Detection, Coral, Edge TPU, Raspberry Pi, embedded, edge compute, sbc, accelerator, mobile
|
||||
---
|
||||
|
||||
# Coral Edge TPU on a Raspberry Pi with Ultralytics YOLOv8 🚀
|
||||
|
||||
<p align="center">
|
||||
<img width="800" src="https://images.ctfassets.net/2lpsze4g694w/5XK2dV0w55U0TefijPli1H/bf0d119d77faef9a5d2cc0dad2aa4b42/Edge-TPU-USB-Accelerator-and-Pi.jpg?w=800" alt="Raspberry Pi single board computer with USB Edge TPU accelerator">
|
||||
</p>
|
||||
|
||||
## What is a Coral Edge TPU?
|
||||
|
||||
The Coral Edge TPU is a compact device that adds an Edge TPU coprocessor to your system. It enables low-power, high-performance ML inference for TensorFlow Lite models. Read more at the [Coral Edge TPU home page](https://coral.ai/products/accelerator).
|
||||
|
||||
## Boost Raspberry Pi Model Performance with Coral Edge TPU
|
||||
|
||||
Many people want to run their models on an embedded or mobile device such as a Raspberry Pi, since they are very power efficient and can be used in many different applications. However, the inference performance on these devices is usually poor even when using formats like [onnx](../integrations/onnx.md) or [openvino](../integrations/openvino.md). The Coral Edge TPU is a great solution to this problem, since it can be used with a Raspberry Pi and accelerate inference performance greatly.
|
||||
|
||||
## Edge TPU on Raspberry Pi with TensorFlow Lite (New)⭐
|
||||
|
||||
The [existing guide](https://coral.ai/docs/accelerator/get-started/) by Coral on how to use the Edge TPU with a Raspberry Pi is outdated, and the current Coral Edge TPU runtime builds do not work with the current TensorFlow Lite runtime versions anymore. In addition to that, Google seems to have completely abandoned the Coral project, and there have not been any updates between 2021 and 2024. This guide will show you how to get the Edge TPU working with the latest versions of the TensorFlow Lite runtime and an updated Coral Edge TPU runtime on a Raspberry Pi single board computer (SBC).
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- [Raspberry Pi 4B](https://www.raspberrypi.com/products/raspberry-pi-4-model-b/) (2GB or more recommended) or [Raspberry Pi 5](https://www.raspberrypi.com/products/raspberry-pi-5/) (Recommended)
|
||||
- [Raspberry Pi OS](https://www.raspberrypi.com/software/) Bullseye/Bookworm (64-bit) with desktop (Recommended)
|
||||
- [Coral USB Accelerator](https://coral.ai/products/accelerator/)
|
||||
- A non-ARM based platform for exporting an Ultralytics PyTorch model
|
||||
|
||||
## Installation Walkthrough
|
||||
|
||||
This guide assumes that you already have a working Raspberry Pi OS install and have installed `ultralytics` and all dependencies. To get `ultralytics` installed, visit the [quickstart guide](../quickstart.md) to get setup before continuing here.
|
||||
|
||||
### Installing the Edge TPU runtime
|
||||
|
||||
First, we need to install the Edge TPU runtime. There are many different versions available, so you need to choose the right version for your operating system.
|
||||
|
||||
| Raspberry Pi OS | High frequency mode | Version to download |
|
||||
|-----------------|:-------------------:|--------------------------------------------|
|
||||
| Bullseye 32bit | No | `libedgetpu1-std_ ... .bullseye_armhf.deb` |
|
||||
| Bullseye 64bit | No | `libedgetpu1-std_ ... .bullseye_arm64.deb` |
|
||||
| Bullseye 32bit | Yes | `libedgetpu1-max_ ... .bullseye_armhf.deb` |
|
||||
| Bullseye 64bit | Yes | `libedgetpu1-max_ ... .bullseye_arm64.deb` |
|
||||
| Bookworm 32bit | No | `libedgetpu1-std_ ... .bookworm_armhf.deb` |
|
||||
| Bookworm 64bit | No | `libedgetpu1-std_ ... .bookworm_arm64.deb` |
|
||||
| Bookworm 32bit | Yes | `libedgetpu1-max_ ... .bookworm_armhf.deb` |
|
||||
| Bookworm 64bit | Yes | `libedgetpu1-max_ ... .bookworm_arm64.deb` |
|
||||
|
||||
[Download the latest version from here](https://github.com/feranick/libedgetpu/releases).
|
||||
|
||||
After downloading the file, you can install it with the following command:
|
||||
|
||||
```bash
|
||||
sudo dpkg -i path/to/package.deb
|
||||
```
|
||||
|
||||
After installing the runtime, you need to plug in your Coral Edge TPU into a USB 3.0 port on your Raspberry Pi. This is because, according to the official guide, a new `udev` rule needs to take effect after installation.
|
||||
|
||||
???+ warning "Important"
|
||||
|
||||
If you already have the Coral Edge TPU runtime installed, uninstall it using the following command.
|
||||
|
||||
```bash
|
||||
# If you installed the standard version
|
||||
sudo apt remove libedgetpu1-std
|
||||
|
||||
# If you installed the high frequency version
|
||||
sudo apt remove libedgetpu1-max
|
||||
```
|
||||
|
||||
## Export your model to a Edge TPU compatible model
|
||||
|
||||
To use the Edge TPU, you need to convert your model into a compatible format. It is recommended that you run export on Google Colab, x86_64 Linux machine, using the official [Ultralytics Docker container](docker-quickstart.md), or using [Ultralytics HUB](../hub/quickstart.md), since the Edge TPU compiler is not available on ARM. See the [Export Mode](../modes/export.md) for the available arguments.
|
||||
|
||||
!!! Exporting the model
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('path/to/model.pt') # Load a official model or custom model
|
||||
|
||||
# Export the model
|
||||
model.export(format='edgetpu')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo export model=path/to/model.pt format=edgetpu # Export a official model or custom model
|
||||
```
|
||||
|
||||
The exported model will be saved in the `<model_name>_saved_model/` folder with the name `<model_name>_full_integer_quant_edgetpu.tflite`.
|
||||
|
||||
## Running the model
|
||||
|
||||
After exporting your model, you can run inference with it using the following code:
|
||||
|
||||
!!! Running the model
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('path/to/edgetpu_model.tflite') # Load a official model or custom model
|
||||
|
||||
# Run Prediction
|
||||
model.predict("path/to/source.png")
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo predict model=path/to/edgetpu_model.tflite source=path/to/source.png # Load a official model or custom model
|
||||
```
|
||||
|
||||
Find comprehensive information on the [Predict](../modes/predict.md) page for full prediction mode details.
|
||||
|
||||
???+ warning "Important"
|
||||
|
||||
You should run the model using `tflite-runtime` and not `tensorflow`.
|
||||
If `tensorflow` is installed, uninstall tensorflow with the following command:
|
||||
|
||||
```bash
|
||||
pip uninstall tensorflow tensorflow-aarch64
|
||||
```
|
||||
|
||||
Then install/update `tflite-runtime`:
|
||||
|
||||
```
|
||||
pip install -U tflite-runtime
|
||||
```
|
||||
|
||||
If you want a `tflite-runtime` wheel for `tensorflow` 2.15.0 download it from [here](https://github.com/feranick/TFlite-builds/releases) and install it using `pip` or your package manager of choice.
|
||||
107
docs/en/guides/distance-calculation.md
Normal file
107
docs/en/guides/distance-calculation.md
Normal file
@ -0,0 +1,107 @@
|
||||
---
|
||||
comments: true
|
||||
description: Distance Calculation Using Ultralytics YOLOv8
|
||||
keywords: Ultralytics, YOLOv8, Object Detection, Distance Calculation, Object Tracking, Notebook, IPython Kernel, CLI, Python SDK
|
||||
---
|
||||
|
||||
# Distance Calculation using Ultralytics YOLOv8 🚀
|
||||
|
||||
## What is Distance Calculation?
|
||||
|
||||
Measuring the gap between two objects is known as distance calculation within a specified space. In the case of [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics), the bounding box centroid is employed to calculate the distance for bounding boxes highlighted by the user.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/LE8am1QoVn4"
|
||||
title="YouTube video player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Watch:</strong> Distance Calculation using Ultralytics YOLOv8
|
||||
</p>
|
||||
|
||||
## Visuals
|
||||
|
||||
| Distance Calculation using Ultralytics YOLOv8 |
|
||||
|:-----------------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
|  |
|
||||
|
||||
## Advantages of Distance Calculation?
|
||||
|
||||
- **Localization Precision:** Enhances accurate spatial positioning in computer vision tasks.
|
||||
- **Size Estimation:** Allows estimation of physical sizes for better contextual understanding.
|
||||
- **Scene Understanding:** Contributes to a 3D understanding of the environment for improved decision-making.
|
||||
|
||||
???+ tip "Distance Calculation"
|
||||
|
||||
- Click on any two bounding boxes with Left Mouse click for distance calculation
|
||||
|
||||
!!! Example "Distance Calculation using YOLOv8 Example"
|
||||
|
||||
=== "Video Stream"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.solutions import distance_calculation
|
||||
import cv2
|
||||
|
||||
model = YOLO("yolov8n.pt")
|
||||
names = model.model.names
|
||||
|
||||
cap = cv2.VideoCapture("path/to/video/file.mp4")
|
||||
assert cap.isOpened(), "Error reading video file"
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
# Video writer
|
||||
video_writer = cv2.VideoWriter("distance_calculation.avi",
|
||||
cv2.VideoWriter_fourcc(*'mp4v'),
|
||||
fps,
|
||||
(w, h))
|
||||
|
||||
# Init distance-calculation obj
|
||||
dist_obj = distance_calculation.DistanceCalculation()
|
||||
dist_obj.set_args(names=names, view_img=True)
|
||||
|
||||
while cap.isOpened():
|
||||
success, im0 = cap.read()
|
||||
if not success:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
|
||||
tracks = model.track(im0, persist=True, show=False)
|
||||
im0 = dist_obj.start_process(im0, tracks)
|
||||
video_writer.write(im0)
|
||||
|
||||
cap.release()
|
||||
video_writer.release()
|
||||
cv2.destroyAllWindows()
|
||||
|
||||
```
|
||||
|
||||
???+ tip "Note"
|
||||
|
||||
- Mouse Right Click will delete all drawn points
|
||||
- Mouse Left Click can be used to draw points
|
||||
|
||||
### Optional Arguments `set_args`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|------------------|--------|-----------------|--------------------------------------------------------|
|
||||
| `names` | `dict` | `None` | Classes names |
|
||||
| `view_img` | `bool` | `False` | Display frames with counts |
|
||||
| `line_thickness` | `int` | `2` | Increase bounding boxes thickness |
|
||||
| `line_color` | `RGB` | `(255, 255, 0)` | Line Color for centroids mapping on two bounding boxes |
|
||||
| `centroid_color` | `RGB` | `(255, 0, 255)` | Centroid color for each bounding box |
|
||||
|
||||
### Arguments `model.track`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------|---------|----------------|-------------------------------------------------------------|
|
||||
| `source` | `im0` | `None` | source directory for images or videos |
|
||||
| `persist` | `bool` | `False` | persisting tracks between frames |
|
||||
| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
|
||||
| `conf` | `float` | `0.3` | Confidence Threshold |
|
||||
| `iou` | `float` | `0.5` | IOU Threshold |
|
||||
| `classes` | `list` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] |
|
||||
| `verbose` | `bool` | `True` | Display the object tracking results |
|
||||
119
docs/en/guides/docker-quickstart.md
Normal file
119
docs/en/guides/docker-quickstart.md
Normal file
@ -0,0 +1,119 @@
|
||||
---
|
||||
comments: true
|
||||
description: Complete guide to setting up and using Ultralytics YOLO models with Docker. Learn how to install Docker, manage GPU support, and run YOLO models in isolated containers.
|
||||
keywords: Ultralytics, YOLO, Docker, GPU, containerization, object detection, package installation, deep learning, machine learning, guide
|
||||
---
|
||||
|
||||
# Docker Quickstart Guide for Ultralytics
|
||||
|
||||
<p align="center">
|
||||
<img width="800" src="https://user-images.githubusercontent.com/26833433/270173601-fc7011bd-e67c-452f-a31a-aa047dcd2771.png" alt="Ultralytics Docker Package Visual">
|
||||
</p>
|
||||
|
||||
This guide serves as a comprehensive introduction to setting up a Docker environment for your Ultralytics projects. [Docker](https://docker.com/) is a platform for developing, shipping, and running applications in containers. It is particularly beneficial for ensuring that the software will always run the same, regardless of where it's deployed. For more details, visit the Ultralytics Docker repository on [Docker Hub](https://hub.docker.com/r/ultralytics/ultralytics).
|
||||
|
||||
[](https://hub.docker.com/r/ultralytics/ultralytics)
|
||||
|
||||
## What You Will Learn
|
||||
|
||||
- Setting up Docker with NVIDIA support
|
||||
- Installing Ultralytics Docker images
|
||||
- Running Ultralytics in a Docker container
|
||||
- Mounting local directories into the container
|
||||
|
||||
---
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- Make sure Docker is installed on your system. If not, you can download and install it from [Docker's website](https://www.docker.com/products/docker-desktop).
|
||||
- Ensure that your system has an NVIDIA GPU and NVIDIA drivers are installed.
|
||||
|
||||
---
|
||||
|
||||
## Setting up Docker with NVIDIA Support
|
||||
|
||||
First, verify that the NVIDIA drivers are properly installed by running:
|
||||
|
||||
```bash
|
||||
nvidia-smi
|
||||
```
|
||||
|
||||
### Installing NVIDIA Docker Runtime
|
||||
|
||||
Now, let's install the NVIDIA Docker runtime to enable GPU support in Docker containers:
|
||||
|
||||
```bash
|
||||
# Add NVIDIA package repositories
|
||||
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
|
||||
distribution=$(lsb_release -cs)
|
||||
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
|
||||
|
||||
# Install NVIDIA Docker runtime
|
||||
sudo apt-get update
|
||||
sudo apt-get install -y nvidia-docker2
|
||||
|
||||
# Restart Docker service to apply changes
|
||||
sudo systemctl restart docker
|
||||
```
|
||||
|
||||
### Verify NVIDIA Runtime with Docker
|
||||
|
||||
Run `docker info | grep -i runtime` to ensure that `nvidia` appears in the list of runtimes:
|
||||
|
||||
```bash
|
||||
docker info | grep -i runtime
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Installing Ultralytics Docker Images
|
||||
|
||||
Ultralytics offers several Docker images optimized for various platforms and use-cases:
|
||||
|
||||
- **Dockerfile:** GPU image, ideal for training.
|
||||
- **Dockerfile-arm64:** For ARM64 architecture, suitable for devices like [Raspberry Pi](raspberry-pi.md).
|
||||
- **Dockerfile-cpu:** CPU-only version for inference and non-GPU environments.
|
||||
- **Dockerfile-jetson:** Optimized for NVIDIA Jetson devices.
|
||||
- **Dockerfile-python:** Minimal Python environment for lightweight applications.
|
||||
- **Dockerfile-conda:** Includes [Miniconda3](https://docs.conda.io/projects/miniconda/en/latest/) and Ultralytics package installed via Conda.
|
||||
|
||||
To pull the latest image:
|
||||
|
||||
```bash
|
||||
# Set image name as a variable
|
||||
t=ultralytics/ultralytics:latest
|
||||
|
||||
# Pull the latest Ultralytics image from Docker Hub
|
||||
sudo docker pull $t
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Running Ultralytics in Docker Container
|
||||
|
||||
Here's how to execute the Ultralytics Docker container:
|
||||
|
||||
```bash
|
||||
# Run with all GPUs
|
||||
sudo docker run -it --ipc=host --gpus all $t
|
||||
|
||||
# Run specifying which GPUs to use
|
||||
sudo docker run -it --ipc=host --gpus '"device=2,3"' $t
|
||||
```
|
||||
|
||||
The `-it` flag assigns a pseudo-TTY and keeps stdin open, allowing you to interact with the container. The `--ipc=host` flag enables sharing of host's IPC namespace, essential for sharing memory between processes. The `--gpus` flag allows the container to access the host's GPUs.
|
||||
|
||||
### Note on File Accessibility
|
||||
|
||||
To work with files on your local machine within the container, you can use Docker volumes:
|
||||
|
||||
```bash
|
||||
# Mount a local directory into the container
|
||||
sudo docker run -it --ipc=host --gpus all -v /path/on/host:/path/in/container $t
|
||||
```
|
||||
|
||||
Replace `/path/on/host` with the directory path on your local machine and `/path/in/container` with the desired path inside the Docker container.
|
||||
|
||||
---
|
||||
|
||||
Congratulations! You're now set up to use Ultralytics with Docker and ready to take advantage of its powerful capabilities. For alternate installation methods, feel free to explore the [Ultralytics quickstart documentation](../quickstart.md).
|
||||
301
docs/en/guides/heatmaps.md
Normal file
301
docs/en/guides/heatmaps.md
Normal file
@ -0,0 +1,301 @@
|
||||
---
|
||||
comments: true
|
||||
description: Advanced Data Visualization with Ultralytics YOLOv8 Heatmaps
|
||||
keywords: Ultralytics, YOLOv8, Advanced Data Visualization, Heatmap Technology, Object Detection and Tracking, Jupyter Notebook, Python SDK, Command Line Interface
|
||||
---
|
||||
|
||||
# Advanced Data Visualization: Heatmaps using Ultralytics YOLOv8 🚀
|
||||
|
||||
## Introduction to Heatmaps
|
||||
|
||||
A heatmap generated with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) transforms complex data into a vibrant, color-coded matrix. This visual tool employs a spectrum of colors to represent varying data values, where warmer hues indicate higher intensities and cooler tones signify lower values. Heatmaps excel in visualizing intricate data patterns, correlations, and anomalies, offering an accessible and engaging approach to data interpretation across diverse domains.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/4ezde5-nZZw"
|
||||
title="YouTube video player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Watch:</strong> Heatmaps using Ultralytics YOLOv8
|
||||
</p>
|
||||
|
||||
## Why Choose Heatmaps for Data Analysis?
|
||||
|
||||
- **Intuitive Data Distribution Visualization:** Heatmaps simplify the comprehension of data concentration and distribution, converting complex datasets into easy-to-understand visual formats.
|
||||
- **Efficient Pattern Detection:** By visualizing data in heatmap format, it becomes easier to spot trends, clusters, and outliers, facilitating quicker analysis and insights.
|
||||
- **Enhanced Spatial Analysis and Decision-Making:** Heatmaps are instrumental in illustrating spatial relationships, aiding in decision-making processes in sectors such as business intelligence, environmental studies, and urban planning.
|
||||
|
||||
## Real World Applications
|
||||
|
||||
| Transportation | Retail |
|
||||
|:-----------------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
|  |  |
|
||||
| Ultralytics YOLOv8 Transportation Heatmap | Ultralytics YOLOv8 Retail Heatmap |
|
||||
|
||||
!!! tip "Heatmap Configuration"
|
||||
|
||||
- `heatmap_alpha`: Ensure this value is within the range (0.0 - 1.0).
|
||||
- `decay_factor`: Used for removing heatmap after an object is no longer in the frame, its value should also be in the range (0.0 - 1.0).
|
||||
|
||||
!!! Example "Heatmaps using Ultralytics YOLOv8 Example"
|
||||
|
||||
=== "Heatmap"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.solutions import heatmap
|
||||
import cv2
|
||||
|
||||
model = YOLO("yolov8n.pt")
|
||||
cap = cv2.VideoCapture("path/to/video/file.mp4")
|
||||
assert cap.isOpened(), "Error reading video file"
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
# Video writer
|
||||
video_writer = cv2.VideoWriter("heatmap_output.avi",
|
||||
cv2.VideoWriter_fourcc(*'mp4v'),
|
||||
fps,
|
||||
(w, h))
|
||||
|
||||
# Init heatmap
|
||||
heatmap_obj = heatmap.Heatmap()
|
||||
heatmap_obj.set_args(colormap=cv2.COLORMAP_PARULA,
|
||||
imw=w,
|
||||
imh=h,
|
||||
view_img=True,
|
||||
shape="circle")
|
||||
|
||||
while cap.isOpened():
|
||||
success, im0 = cap.read()
|
||||
if not success:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
tracks = model.track(im0, persist=True, show=False)
|
||||
|
||||
im0 = heatmap_obj.generate_heatmap(im0, tracks)
|
||||
video_writer.write(im0)
|
||||
|
||||
cap.release()
|
||||
video_writer.release()
|
||||
cv2.destroyAllWindows()
|
||||
|
||||
```
|
||||
|
||||
=== "Line Counting"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.solutions import heatmap
|
||||
import cv2
|
||||
|
||||
model = YOLO("yolov8n.pt")
|
||||
cap = cv2.VideoCapture("path/to/video/file.mp4")
|
||||
assert cap.isOpened(), "Error reading video file"
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
# Video writer
|
||||
video_writer = cv2.VideoWriter("heatmap_output.avi",
|
||||
cv2.VideoWriter_fourcc(*'mp4v'),
|
||||
fps,
|
||||
(w, h))
|
||||
|
||||
line_points = [(20, 400), (1080, 404)] # line for object counting
|
||||
|
||||
# Init heatmap
|
||||
heatmap_obj = heatmap.Heatmap()
|
||||
heatmap_obj.set_args(colormap=cv2.COLORMAP_PARULA,
|
||||
imw=w,
|
||||
imh=h,
|
||||
view_img=True,
|
||||
shape="circle",
|
||||
count_reg_pts=line_points)
|
||||
|
||||
while cap.isOpened():
|
||||
success, im0 = cap.read()
|
||||
if not success:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
tracks = model.track(im0, persist=True, show=False)
|
||||
|
||||
im0 = heatmap_obj.generate_heatmap(im0, tracks)
|
||||
video_writer.write(im0)
|
||||
|
||||
cap.release()
|
||||
video_writer.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
=== "Region Counting"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.solutions import heatmap
|
||||
import cv2
|
||||
|
||||
model = YOLO("yolov8n.pt")
|
||||
cap = cv2.VideoCapture("path/to/video/file.mp4")
|
||||
assert cap.isOpened(), "Error reading video file"
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
# Video writer
|
||||
video_writer = cv2.VideoWriter("heatmap_output.avi",
|
||||
cv2.VideoWriter_fourcc(*'mp4v'),
|
||||
fps,
|
||||
(w, h))
|
||||
|
||||
# Define region points
|
||||
region_points = [(20, 400), (1080, 404), (1080, 360), (20, 360)]
|
||||
|
||||
# Init heatmap
|
||||
heatmap_obj = heatmap.Heatmap()
|
||||
heatmap_obj.set_args(colormap=cv2.COLORMAP_PARULA,
|
||||
imw=w,
|
||||
imh=h,
|
||||
view_img=True,
|
||||
shape="circle",
|
||||
count_reg_pts=region_points)
|
||||
|
||||
while cap.isOpened():
|
||||
success, im0 = cap.read()
|
||||
if not success:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
tracks = model.track(im0, persist=True, show=False)
|
||||
|
||||
im0 = heatmap_obj.generate_heatmap(im0, tracks)
|
||||
video_writer.write(im0)
|
||||
|
||||
cap.release()
|
||||
video_writer.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
=== "Im0"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.solutions import heatmap
|
||||
import cv2
|
||||
|
||||
model = YOLO("yolov8s.pt") # YOLOv8 custom/pretrained model
|
||||
|
||||
im0 = cv2.imread("path/to/image.png") # path to image file
|
||||
h, w = im0.shape[:2] # image height and width
|
||||
|
||||
# Heatmap Init
|
||||
heatmap_obj = heatmap.Heatmap()
|
||||
heatmap_obj.set_args(colormap=cv2.COLORMAP_PARULA,
|
||||
imw=w,
|
||||
imh=h,
|
||||
view_img=True,
|
||||
shape="circle")
|
||||
|
||||
results = model.track(im0, persist=True)
|
||||
im0 = heatmap_obj.generate_heatmap(im0, tracks=results)
|
||||
cv2.imwrite("ultralytics_output.png", im0)
|
||||
```
|
||||
|
||||
=== "Specific Classes"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.solutions import heatmap
|
||||
import cv2
|
||||
|
||||
model = YOLO("yolov8n.pt")
|
||||
cap = cv2.VideoCapture("path/to/video/file.mp4")
|
||||
assert cap.isOpened(), "Error reading video file"
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
# Video writer
|
||||
video_writer = cv2.VideoWriter("heatmap_output.avi",
|
||||
cv2.VideoWriter_fourcc(*'mp4v'),
|
||||
fps,
|
||||
(w, h))
|
||||
|
||||
classes_for_heatmap = [0, 2] # classes for heatmap
|
||||
|
||||
# Init heatmap
|
||||
heatmap_obj = heatmap.Heatmap()
|
||||
heatmap_obj.set_args(colormap=cv2.COLORMAP_PARULA,
|
||||
imw=w,
|
||||
imh=h,
|
||||
view_img=True,
|
||||
shape="circle")
|
||||
|
||||
while cap.isOpened():
|
||||
success, im0 = cap.read()
|
||||
if not success:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
tracks = model.track(im0, persist=True, show=False,
|
||||
classes=classes_for_heatmap)
|
||||
|
||||
im0 = heatmap_obj.generate_heatmap(im0, tracks)
|
||||
video_writer.write(im0)
|
||||
|
||||
cap.release()
|
||||
video_writer.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
### Arguments `set_args`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------------------|----------------|-------------------|-----------------------------------------------------------|
|
||||
| `view_img` | `bool` | `False` | Display the frame with heatmap |
|
||||
| `colormap` | `cv2.COLORMAP` | `None` | cv2.COLORMAP for heatmap |
|
||||
| `imw` | `int` | `None` | Width of Heatmap |
|
||||
| `imh` | `int` | `None` | Height of Heatmap |
|
||||
| `heatmap_alpha` | `float` | `0.5` | Heatmap alpha value |
|
||||
| `count_reg_pts` | `list` | `None` | Object counting region points |
|
||||
| `count_txt_thickness` | `int` | `2` | Count values text size |
|
||||
| `count_txt_color` | `RGB Color` | `(0, 0, 0)` | Foreground color for Object counts text |
|
||||
| `count_color` | `RGB Color` | `(255, 255, 255)` | Background color for Object counts text |
|
||||
| `count_reg_color` | `RGB Color` | `(255, 0, 255)` | Counting region color |
|
||||
| `region_thickness` | `int` | `5` | Counting region thickness value |
|
||||
| `decay_factor` | `float` | `0.99` | Decay factor for heatmap area removal after specific time |
|
||||
| `shape` | `str` | `circle` | Heatmap shape for display "rect" or "circle" supported |
|
||||
| `line_dist_thresh` | `int` | `15` | Euclidean Distance threshold for line counter |
|
||||
|
||||
### Arguments `model.track`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------|---------|----------------|-------------------------------------------------------------|
|
||||
| `source` | `im0` | `None` | source directory for images or videos |
|
||||
| `persist` | `bool` | `False` | persisting tracks between frames |
|
||||
| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
|
||||
| `conf` | `float` | `0.3` | Confidence Threshold |
|
||||
| `iou` | `float` | `0.5` | IOU Threshold |
|
||||
| `classes` | `list` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] |
|
||||
|
||||
### Heatmap COLORMAPs
|
||||
|
||||
| Colormap Name | Description |
|
||||
|---------------------------------|----------------------------------------|
|
||||
| `cv::COLORMAP_AUTUMN` | Autumn color map |
|
||||
| `cv::COLORMAP_BONE` | Bone color map |
|
||||
| `cv::COLORMAP_JET` | Jet color map |
|
||||
| `cv::COLORMAP_WINTER` | Winter color map |
|
||||
| `cv::COLORMAP_RAINBOW` | Rainbow color map |
|
||||
| `cv::COLORMAP_OCEAN` | Ocean color map |
|
||||
| `cv::COLORMAP_SUMMER` | Summer color map |
|
||||
| `cv::COLORMAP_SPRING` | Spring color map |
|
||||
| `cv::COLORMAP_COOL` | Cool color map |
|
||||
| `cv::COLORMAP_HSV` | HSV (Hue, Saturation, Value) color map |
|
||||
| `cv::COLORMAP_PINK` | Pink color map |
|
||||
| `cv::COLORMAP_HOT` | Hot color map |
|
||||
| `cv::COLORMAP_PARULA` | Parula color map |
|
||||
| `cv::COLORMAP_MAGMA` | Magma color map |
|
||||
| `cv::COLORMAP_INFERNO` | Inferno color map |
|
||||
| `cv::COLORMAP_PLASMA` | Plasma color map |
|
||||
| `cv::COLORMAP_VIRIDIS` | Viridis color map |
|
||||
| `cv::COLORMAP_CIVIDIS` | Cividis color map |
|
||||
| `cv::COLORMAP_TWILIGHT` | Twilight color map |
|
||||
| `cv::COLORMAP_TWILIGHT_SHIFTED` | Shifted Twilight color map |
|
||||
| `cv::COLORMAP_TURBO` | Turbo color map |
|
||||
| `cv::COLORMAP_DEEPGREEN` | Deep Green color map |
|
||||
|
||||
These colormaps are commonly used for visualizing data with different color representations.
|
||||
206
docs/en/guides/hyperparameter-tuning.md
Normal file
206
docs/en/guides/hyperparameter-tuning.md
Normal file
@ -0,0 +1,206 @@
|
||||
---
|
||||
comments: true
|
||||
description: Dive into hyperparameter tuning in Ultralytics YOLO models. Learn how to optimize performance using the Tuner class and genetic evolution.
|
||||
keywords: Ultralytics, YOLO, Hyperparameter Tuning, Tuner Class, Genetic Evolution, Optimization
|
||||
---
|
||||
|
||||
# Ultralytics YOLO Hyperparameter Tuning Guide
|
||||
|
||||
## Introduction
|
||||
|
||||
Hyperparameter tuning is not just a one-time set-up but an iterative process aimed at optimizing the machine learning model's performance metrics, such as accuracy, precision, and recall. In the context of Ultralytics YOLO, these hyperparameters could range from learning rate to architectural details, such as the number of layers or types of activation functions used.
|
||||
|
||||
### What are Hyperparameters?
|
||||
|
||||
Hyperparameters are high-level, structural settings for the algorithm. They are set prior to the training phase and remain constant during it. Here are some commonly tuned hyperparameters in Ultralytics YOLO:
|
||||
|
||||
- **Learning Rate** `lr0`: Determines the step size at each iteration while moving towards a minimum in the loss function.
|
||||
- **Batch Size** `batch`: Number of images processed simultaneously in a forward pass.
|
||||
- **Number of Epochs** `epochs`: An epoch is one complete forward and backward pass of all the training examples.
|
||||
- **Architecture Specifics**: Such as channel counts, number of layers, types of activation functions, etc.
|
||||
|
||||
<p align="center">
|
||||
<img width="640" src="https://user-images.githubusercontent.com/26833433/263858934-4f109a2f-82d9-4d08-8bd6-6fd1ff520bcd.png" alt="Hyperparameter Tuning Visual">
|
||||
</p>
|
||||
|
||||
For a full list of augmentation hyperparameters used in YOLOv8 please refer to the [configurations page](../usage/cfg.md#augmentation-settings).
|
||||
|
||||
### Genetic Evolution and Mutation
|
||||
|
||||
Ultralytics YOLO uses genetic algorithms to optimize hyperparameters. Genetic algorithms are inspired by the mechanism of natural selection and genetics.
|
||||
|
||||
- **Mutation**: In the context of Ultralytics YOLO, mutation helps in locally searching the hyperparameter space by applying small, random changes to existing hyperparameters, producing new candidates for evaluation.
|
||||
- **Crossover**: Although crossover is a popular genetic algorithm technique, it is not currently used in Ultralytics YOLO for hyperparameter tuning. The focus is mainly on mutation for generating new hyperparameter sets.
|
||||
|
||||
## Preparing for Hyperparameter Tuning
|
||||
|
||||
Before you begin the tuning process, it's important to:
|
||||
|
||||
1. **Identify the Metrics**: Determine the metrics you will use to evaluate the model's performance. This could be AP50, F1-score, or others.
|
||||
2. **Set the Tuning Budget**: Define how much computational resources you're willing to allocate. Hyperparameter tuning can be computationally intensive.
|
||||
|
||||
## Steps Involved
|
||||
|
||||
### Initialize Hyperparameters
|
||||
|
||||
Start with a reasonable set of initial hyperparameters. This could either be the default hyperparameters set by Ultralytics YOLO or something based on your domain knowledge or previous experiments.
|
||||
|
||||
### Mutate Hyperparameters
|
||||
|
||||
Use the `_mutate` method to produce a new set of hyperparameters based on the existing set.
|
||||
|
||||
### Train Model
|
||||
|
||||
Training is performed using the mutated set of hyperparameters. The training performance is then assessed.
|
||||
|
||||
### Evaluate Model
|
||||
|
||||
Use metrics like AP50, F1-score, or custom metrics to evaluate the model's performance.
|
||||
|
||||
### Log Results
|
||||
|
||||
It's crucial to log both the performance metrics and the corresponding hyperparameters for future reference.
|
||||
|
||||
### Repeat
|
||||
|
||||
The process is repeated until either the set number of iterations is reached or the performance metric is satisfactory.
|
||||
|
||||
## Usage Example
|
||||
|
||||
Here's how to use the `model.tune()` method to utilize the `Tuner` class for hyperparameter tuning of YOLOv8n on COCO8 for 30 epochs with an AdamW optimizer and skipping plotting, checkpointing and validation other than on final epoch for faster Tuning.
|
||||
|
||||
!!! Example
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Initialize the YOLO model
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Tune hyperparameters on COCO8 for 30 epochs
|
||||
model.tune(data='coco8.yaml', epochs=30, iterations=300, optimizer='AdamW', plots=False, save=False, val=False)
|
||||
```
|
||||
|
||||
## Results
|
||||
|
||||
After you've successfully completed the hyperparameter tuning process, you will obtain several files and directories that encapsulate the results of the tuning. The following describes each:
|
||||
|
||||
### File Structure
|
||||
|
||||
Here's what the directory structure of the results will look like. Training directories like `train1/` contain individual tuning iterations, i.e. one model trained with one set of hyperparameters. The `tune/` directory contains tuning results from all the individual model trainings:
|
||||
|
||||
```plaintext
|
||||
runs/
|
||||
└── detect/
|
||||
├── train1/
|
||||
├── train2/
|
||||
├── ...
|
||||
└── tune/
|
||||
├── best_hyperparameters.yaml
|
||||
├── best_fitness.png
|
||||
├── tune_results.csv
|
||||
├── tune_scatter_plots.png
|
||||
└── weights/
|
||||
├── last.pt
|
||||
└── best.pt
|
||||
```
|
||||
|
||||
### File Descriptions
|
||||
|
||||
#### best_hyperparameters.yaml
|
||||
|
||||
This YAML file contains the best-performing hyperparameters found during the tuning process. You can use this file to initialize future trainings with these optimized settings.
|
||||
|
||||
- **Format**: YAML
|
||||
- **Usage**: Hyperparameter results
|
||||
- **Example**:
|
||||
```yaml
|
||||
# 558/900 iterations complete ✅ (45536.81s)
|
||||
# Results saved to /usr/src/ultralytics/runs/detect/tune
|
||||
# Best fitness=0.64297 observed at iteration 498
|
||||
# Best fitness metrics are {'metrics/precision(B)': 0.87247, 'metrics/recall(B)': 0.71387, 'metrics/mAP50(B)': 0.79106, 'metrics/mAP50-95(B)': 0.62651, 'val/box_loss': 2.79884, 'val/cls_loss': 2.72386, 'val/dfl_loss': 0.68503, 'fitness': 0.64297}
|
||||
# Best fitness model is /usr/src/ultralytics/runs/detect/train498
|
||||
# Best fitness hyperparameters are printed below.
|
||||
|
||||
lr0: 0.00269
|
||||
lrf: 0.00288
|
||||
momentum: 0.73375
|
||||
weight_decay: 0.00015
|
||||
warmup_epochs: 1.22935
|
||||
warmup_momentum: 0.1525
|
||||
box: 18.27875
|
||||
cls: 1.32899
|
||||
dfl: 0.56016
|
||||
hsv_h: 0.01148
|
||||
hsv_s: 0.53554
|
||||
hsv_v: 0.13636
|
||||
degrees: 0.0
|
||||
translate: 0.12431
|
||||
scale: 0.07643
|
||||
shear: 0.0
|
||||
perspective: 0.0
|
||||
flipud: 0.0
|
||||
fliplr: 0.08631
|
||||
mosaic: 0.42551
|
||||
mixup: 0.0
|
||||
copy_paste: 0.0
|
||||
```
|
||||
|
||||
#### best_fitness.png
|
||||
|
||||
This is a plot displaying fitness (typically a performance metric like AP50) against the number of iterations. It helps you visualize how well the genetic algorithm performed over time.
|
||||
|
||||
- **Format**: PNG
|
||||
- **Usage**: Performance visualization
|
||||
|
||||
<p align="center">
|
||||
<img width="640" src="https://user-images.githubusercontent.com/26833433/266847423-9d0aea13-d5c4-4771-b06e-0b817a498260.png" alt="Hyperparameter Tuning Fitness vs Iteration">
|
||||
</p>
|
||||
|
||||
#### tune_results.csv
|
||||
|
||||
A CSV file containing detailed results of each iteration during the tuning. Each row in the file represents one iteration, and it includes metrics like fitness score, precision, recall, as well as the hyperparameters used.
|
||||
|
||||
- **Format**: CSV
|
||||
- **Usage**: Per-iteration results tracking.
|
||||
- **Example**:
|
||||
```csv
|
||||
fitness,lr0,lrf,momentum,weight_decay,warmup_epochs,warmup_momentum,box,cls,dfl,hsv_h,hsv_s,hsv_v,degrees,translate,scale,shear,perspective,flipud,fliplr,mosaic,mixup,copy_paste
|
||||
0.05021,0.01,0.01,0.937,0.0005,3.0,0.8,7.5,0.5,1.5,0.015,0.7,0.4,0.0,0.1,0.5,0.0,0.0,0.0,0.5,1.0,0.0,0.0
|
||||
0.07217,0.01003,0.00967,0.93897,0.00049,2.79757,0.81075,7.5,0.50746,1.44826,0.01503,0.72948,0.40658,0.0,0.0987,0.4922,0.0,0.0,0.0,0.49729,1.0,0.0,0.0
|
||||
0.06584,0.01003,0.00855,0.91009,0.00073,3.42176,0.95,8.64301,0.54594,1.72261,0.01503,0.59179,0.40658,0.0,0.0987,0.46955,0.0,0.0,0.0,0.49729,0.80187,0.0,0.0
|
||||
```
|
||||
|
||||
#### tune_scatter_plots.png
|
||||
|
||||
This file contains scatter plots generated from `tune_results.csv`, helping you visualize relationships between different hyperparameters and performance metrics. Note that hyperparameters initialized to 0 will not be tuned, such as `degrees` and `shear` below.
|
||||
|
||||
- **Format**: PNG
|
||||
- **Usage**: Exploratory data analysis
|
||||
|
||||
<p align="center">
|
||||
<img width="1000" src="https://user-images.githubusercontent.com/26833433/266847488-ec382f3d-79bc-4087-a0e0-42fb8b62cad2.png" alt="Hyperparameter Tuning Scatter Plots">
|
||||
</p>
|
||||
|
||||
#### weights/
|
||||
|
||||
This directory contains the saved PyTorch models for the last and the best iterations during the hyperparameter tuning process.
|
||||
|
||||
- **`last.pt`**: The last.pt are the weights from the last epoch of training.
|
||||
- **`best.pt`**: The best.pt weights for the iteration that achieved the best fitness score.
|
||||
|
||||
Using these results, you can make more informed decisions for your future model trainings and analyses. Feel free to consult these artifacts to understand how well your model performed and how you might improve it further.
|
||||
|
||||
## Conclusion
|
||||
|
||||
The hyperparameter tuning process in Ultralytics YOLO is simplified yet powerful, thanks to its genetic algorithm-based approach focused on mutation. Following the steps outlined in this guide will assist you in systematically tuning your model to achieve better performance.
|
||||
|
||||
### Further Reading
|
||||
|
||||
1. [Hyperparameter Optimization in Wikipedia](https://en.wikipedia.org/wiki/Hyperparameter_optimization)
|
||||
2. [YOLOv5 Hyperparameter Evolution Guide](../yolov5/tutorials/hyperparameter_evolution.md)
|
||||
3. [Efficient Hyperparameter Tuning with Ray Tune and YOLOv8](../integrations/ray-tune.md)
|
||||
|
||||
For deeper insights, you can explore the `Tuner` class source code and accompanying documentation. Should you have any questions, feature requests, or need further assistance, feel free to reach out to us on [GitHub](https://github.com/ultralytics/ultralytics/issues/new/choose) or [Discord](https://ultralytics.com/discord).
|
||||
65
docs/en/guides/index.md
Normal file
65
docs/en/guides/index.md
Normal file
@ -0,0 +1,65 @@
|
||||
---
|
||||
comments: true
|
||||
description: In-depth exploration of Ultralytics' YOLO. Learn about the YOLO object detection model, how to train it on custom data, multi-GPU training, exporting, predicting, deploying, and more.
|
||||
keywords: Ultralytics, YOLO, Deep Learning, Object detection, PyTorch, Tutorial, Multi-GPU training, Custom data training, SAHI, Tiled Inference
|
||||
---
|
||||
|
||||
# Comprehensive Tutorials to Ultralytics YOLO
|
||||
|
||||
Welcome to the Ultralytics' YOLO 🚀 Guides! Our comprehensive tutorials cover various aspects of the YOLO object detection model, ranging from training and prediction to deployment. Built on PyTorch, YOLO stands out for its exceptional speed and accuracy in real-time object detection tasks.
|
||||
|
||||
Whether you're a beginner or an expert in deep learning, our tutorials offer valuable insights into the implementation and optimization of YOLO for your computer vision projects. Let's dive in!
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/96NkhsV-W1U"
|
||||
title="YouTube video player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Watch:</strong> Ultralytics YOLOv8 Guides Overview
|
||||
</p>
|
||||
|
||||
## Guides
|
||||
|
||||
Here's a compilation of in-depth guides to help you master different aspects of Ultralytics YOLO.
|
||||
|
||||
- [YOLO Common Issues](yolo-common-issues.md) ⭐ RECOMMENDED: Practical solutions and troubleshooting tips to the most frequently encountered issues when working with Ultralytics YOLO models.
|
||||
- [YOLO Performance Metrics](yolo-performance-metrics.md) ⭐ ESSENTIAL: Understand the key metrics like mAP, IoU, and F1 score used to evaluate the performance of your YOLO models. Includes practical examples and tips on how to improve detection accuracy and speed.
|
||||
- [Model Deployment Options](model-deployment-options.md): Overview of YOLO model deployment formats like ONNX, OpenVINO, and TensorRT, with pros and cons for each to inform your deployment strategy.
|
||||
- [K-Fold Cross Validation](kfold-cross-validation.md) 🚀 NEW: Learn how to improve model generalization using K-Fold cross-validation technique.
|
||||
- [Hyperparameter Tuning](hyperparameter-tuning.md) 🚀 NEW: Discover how to optimize your YOLO models by fine-tuning hyperparameters using the Tuner class and genetic evolution algorithms.
|
||||
- [SAHI Tiled Inference](sahi-tiled-inference.md) 🚀 NEW: Comprehensive guide on leveraging SAHI's sliced inference capabilities with YOLOv8 for object detection in high-resolution images.
|
||||
- [AzureML Quickstart](azureml-quickstart.md) 🚀 NEW: Get up and running with Ultralytics YOLO models on Microsoft's Azure Machine Learning platform. Learn how to train, deploy, and scale your object detection projects in the cloud.
|
||||
- [Conda Quickstart](conda-quickstart.md) 🚀 NEW: Step-by-step guide to setting up a [Conda](https://anaconda.org/conda-forge/ultralytics) environment for Ultralytics. Learn how to install and start using the Ultralytics package efficiently with Conda.
|
||||
- [Docker Quickstart](docker-quickstart.md) 🚀 NEW: Complete guide to setting up and using Ultralytics YOLO models with [Docker](https://hub.docker.com/r/ultralytics/ultralytics). Learn how to install Docker, manage GPU support, and run YOLO models in isolated containers for consistent development and deployment.
|
||||
- [Raspberry Pi](raspberry-pi.md) 🚀 NEW: Quickstart tutorial to run YOLO models to the latest Raspberry Pi hardware.
|
||||
- [Triton Inference Server Integration](triton-inference-server.md) 🚀 NEW: Dive into the integration of Ultralytics YOLOv8 with NVIDIA's Triton Inference Server for scalable and efficient deep learning inference deployments.
|
||||
- [YOLO Thread-Safe Inference](yolo-thread-safe-inference.md) 🚀 NEW: Guidelines for performing inference with YOLO models in a thread-safe manner. Learn the importance of thread safety and best practices to prevent race conditions and ensure consistent predictions.
|
||||
- [Isolating Segmentation Objects](isolating-segmentation-objects.md) 🚀 NEW: Step-by-step recipe and explanation on how to extract and/or isolate objects from images using Ultralytics Segmentation.
|
||||
- [Edge TPU on Raspberry Pi](coral-edge-tpu-on-raspberry-pi.md): [Google Edge TPU](https://coral.ai/products/accelerator) accelerates YOLO inference on [Raspberry Pi](https://www.raspberrypi.com/).
|
||||
- [View Inference Images in a Terminal](view-results-in-terminal.md): Use VSCode's integrated terminal to view inference results when using Remote Tunnel or SSH sessions.
|
||||
- [OpenVINO Latency vs Throughput Modes](optimizing-openvino-latency-vs-throughput-modes.md) - Learn latency and throughput optimization techniques for peak YOLO inference performance.
|
||||
|
||||
## Real-World Projects
|
||||
|
||||
- [Object Counting](object-counting.md) 🚀 NEW: Explore the process of real-time object counting with Ultralytics YOLOv8 and acquire the knowledge to effectively count objects in a live video stream.
|
||||
- [Object Cropping](object-cropping.md) 🚀 NEW: Explore object cropping using YOLOv8 for precise extraction of objects from images and videos.
|
||||
- [Object Blurring](object-blurring.md) 🚀 NEW: Apply object blurring with YOLOv8 for privacy protection in image and video processing.
|
||||
- [Workouts Monitoring](workouts-monitoring.md) 🚀 NEW: Discover the comprehensive approach to monitoring workouts with Ultralytics YOLOv8. Acquire the skills and insights necessary to effectively use YOLOv8 for tracking and analyzing various aspects of fitness routines in real time.
|
||||
- [Objects Counting in Regions](region-counting.md) 🚀 NEW: Explore counting objects in specific regions with Ultralytics YOLOv8 for precise and efficient object detection in varied areas.
|
||||
- [Security Alarm System](security-alarm-system.md) 🚀 NEW: Discover the process of creating a security alarm system with Ultralytics YOLOv8. This system triggers alerts upon detecting new objects in the frame. Subsequently, you can customize the code to align with your specific use case.
|
||||
- [Heatmaps](heatmaps.md) 🚀 NEW: Elevate your understanding of data with our Detection Heatmaps! These intuitive visual tools use vibrant color gradients to vividly illustrate the intensity of data values across a matrix. Essential in computer vision, heatmaps are skillfully designed to highlight areas of interest, providing an immediate, impactful way to interpret spatial information.
|
||||
- [Instance Segmentation with Object Tracking](instance-segmentation-and-tracking.md) 🚀 NEW: Explore our feature on [Object Segmentation](https://docs.ultralytics.com/tasks/segment/) in Bounding Boxes Shape, providing a visual representation of precise object boundaries for enhanced understanding and analysis.
|
||||
- [VisionEye View Objects Mapping](vision-eye.md) 🚀 NEW: This feature aim computers to discern and focus on specific objects, much like the way the human eye observes details from a particular viewpoint.
|
||||
- [Speed Estimation](speed-estimation.md) 🚀 NEW: Speed estimation in computer vision relies on analyzing object motion through techniques like [object tracking](https://docs.ultralytics.com/modes/track/), crucial for applications like autonomous vehicles and traffic monitoring.
|
||||
- [Distance Calculation](distance-calculation.md) 🚀 NEW: Distance calculation, which involves measuring the separation between two objects within a defined space, is a crucial aspect. In the context of Ultralytics YOLOv8, the method employed for this involves using the bounding box centroid to determine the distance associated with user-highlighted bounding boxes.
|
||||
|
||||
## Contribute to Our Guides
|
||||
|
||||
We welcome contributions from the community! If you've mastered a particular aspect of Ultralytics YOLO that's not yet covered in our guides, we encourage you to share your expertise. Writing a guide is a great way to give back to the community and help us make our documentation more comprehensive and user-friendly.
|
||||
|
||||
To get started, please read our [Contributing Guide](../help/contributing.md) for guidelines on how to open up a Pull Request (PR) 🛠️. We look forward to your contributions!
|
||||
|
||||
Let's work together to make the Ultralytics YOLO ecosystem more robust and versatile 🙏!
|
||||
140
docs/en/guides/instance-segmentation-and-tracking.md
Normal file
140
docs/en/guides/instance-segmentation-and-tracking.md
Normal file
@ -0,0 +1,140 @@
|
||||
---
|
||||
comments: true
|
||||
description: Instance Segmentation with Object Tracking using Ultralytics YOLOv8
|
||||
keywords: Ultralytics, YOLOv8, Instance Segmentation, Object Detection, Object Tracking, Bounding Box, Computer Vision, Notebook, IPython Kernel, CLI, Python SDK
|
||||
---
|
||||
|
||||
# Instance Segmentation and Tracking using Ultralytics YOLOv8 🚀
|
||||
|
||||
## What is Instance Segmentation?
|
||||
|
||||
[Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) instance segmentation involves identifying and outlining individual objects in an image, providing a detailed understanding of spatial distribution. Unlike semantic segmentation, it uniquely labels and precisely delineates each object, crucial for tasks like object detection and medical imaging.
|
||||
|
||||
There are two types of instance segmentation tracking available in the Ultralytics package:
|
||||
|
||||
- **Instance Segmentation with Class Objects:** Each class object is assigned a unique color for clear visual separation.
|
||||
|
||||
- **Instance Segmentation with Object Tracks:** Every track is represented by a distinct color, facilitating easy identification and tracking.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/75G_S1Ngji8"
|
||||
title="YouTube video player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Watch:</strong> Instance Segmentation with Object Tracking using Ultralytics YOLOv8
|
||||
</p>
|
||||
|
||||
## Samples
|
||||
|
||||
| Instance Segmentation | Instance Segmentation + Object Tracking |
|
||||
|:---------------------------------------------------------------------------------------------------------------------------------------:|:------------------------------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
|  | 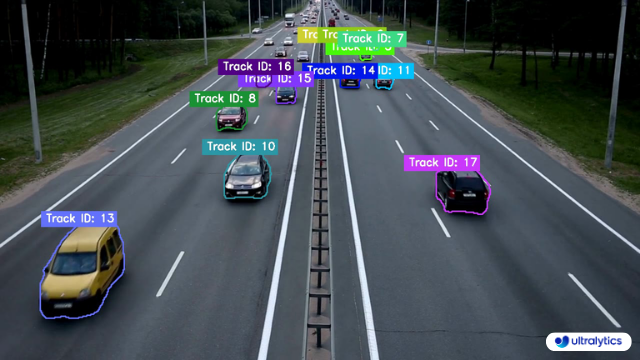 |
|
||||
| Ultralytics Instance Segmentation 😍 | Ultralytics Instance Segmentation with Object Tracking 🔥 |
|
||||
|
||||
!!! Example "Instance Segmentation and Tracking"
|
||||
|
||||
=== "Instance Segmentation"
|
||||
|
||||
```python
|
||||
import cv2
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.utils.plotting import Annotator, colors
|
||||
|
||||
model = YOLO("yolov8n-seg.pt") # segmentation model
|
||||
names = model.model.names
|
||||
cap = cv2.VideoCapture("path/to/video/file.mp4")
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
out = cv2.VideoWriter('instance-segmentation.avi', cv2.VideoWriter_fourcc(*'MJPG'), fps, (w, h))
|
||||
|
||||
while True:
|
||||
ret, im0 = cap.read()
|
||||
if not ret:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
|
||||
results = model.predict(im0)
|
||||
annotator = Annotator(im0, line_width=2)
|
||||
|
||||
if results[0].masks is not None:
|
||||
clss = results[0].boxes.cls.cpu().tolist()
|
||||
masks = results[0].masks.xy
|
||||
for mask, cls in zip(masks, clss):
|
||||
annotator.seg_bbox(mask=mask,
|
||||
mask_color=colors(int(cls), True),
|
||||
det_label=names[int(cls)])
|
||||
|
||||
out.write(im0)
|
||||
cv2.imshow("instance-segmentation", im0)
|
||||
|
||||
if cv2.waitKey(1) & 0xFF == ord('q'):
|
||||
break
|
||||
|
||||
out.release()
|
||||
cap.release()
|
||||
cv2.destroyAllWindows()
|
||||
|
||||
```
|
||||
|
||||
=== "Instance Segmentation with Object Tracking"
|
||||
|
||||
```python
|
||||
import cv2
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.utils.plotting import Annotator, colors
|
||||
|
||||
from collections import defaultdict
|
||||
|
||||
track_history = defaultdict(lambda: [])
|
||||
|
||||
model = YOLO("yolov8n-seg.pt") # segmentation model
|
||||
cap = cv2.VideoCapture("path/to/video/file.mp4")
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
out = cv2.VideoWriter('instance-segmentation-object-tracking.avi', cv2.VideoWriter_fourcc(*'MJPG'), fps, (w, h))
|
||||
|
||||
while True:
|
||||
ret, im0 = cap.read()
|
||||
if not ret:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
|
||||
annotator = Annotator(im0, line_width=2)
|
||||
|
||||
results = model.track(im0, persist=True)
|
||||
|
||||
if results[0].boxes.id is not None and results[0].masks is not None:
|
||||
masks = results[0].masks.xy
|
||||
track_ids = results[0].boxes.id.int().cpu().tolist()
|
||||
|
||||
for mask, track_id in zip(masks, track_ids):
|
||||
annotator.seg_bbox(mask=mask,
|
||||
mask_color=colors(track_id, True),
|
||||
track_label=str(track_id))
|
||||
|
||||
out.write(im0)
|
||||
cv2.imshow("instance-segmentation-object-tracking", im0)
|
||||
|
||||
if cv2.waitKey(1) & 0xFF == ord('q'):
|
||||
break
|
||||
|
||||
out.release()
|
||||
cap.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
### `seg_bbox` Arguments
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|---------------|---------|-----------------|----------------------------------------|
|
||||
| `mask` | `array` | `None` | Segmentation mask coordinates |
|
||||
| `mask_color` | `tuple` | `(255, 0, 255)` | Mask color for every segmented box |
|
||||
| `det_label` | `str` | `None` | Label for segmented object |
|
||||
| `track_label` | `str` | `None` | Label for segmented and tracked object |
|
||||
|
||||
## Note
|
||||
|
||||
For any inquiries, feel free to post your questions in the [Ultralytics Issue Section](https://github.com/ultralytics/ultralytics/issues/new/choose) or the discussion section mentioned below.
|
||||
325
docs/en/guides/isolating-segmentation-objects.md
Normal file
325
docs/en/guides/isolating-segmentation-objects.md
Normal file
@ -0,0 +1,325 @@
|
||||
---
|
||||
comments: true
|
||||
description: A concise guide on isolating segmented objects using Ultralytics.
|
||||
keywords: Ultralytics, YOLO, segmentation, Python, object detection, inference, dataset, prediction, instance segmentation, contours, binary mask, object mask, image processing
|
||||
---
|
||||
|
||||
# Isolating Segmentation Objects
|
||||
|
||||
After performing the [Segment Task](../tasks/segment.md), it's sometimes desirable to extract the isolated objects from the inference results. This guide provides a generic recipe on how to accomplish this using the Ultralytics [Predict Mode](../modes/predict.md).
|
||||
|
||||
<p align="center">
|
||||
<img src="https://github.com/ultralytics/ultralytics/assets/62214284/1787d76b-ad5f-43f9-a39c-d45c9157f38a" alt="Example Isolated Object Segmentation">
|
||||
</p>
|
||||
|
||||
## Recipe Walk Through
|
||||
|
||||
1. Begin with the necessary imports
|
||||
|
||||
```python
|
||||
from pathlib import Path
|
||||
|
||||
import cv2
|
||||
import numpy as np
|
||||
from ultralytics import YOLO
|
||||
```
|
||||
|
||||
???+ tip "Ultralytics Install"
|
||||
|
||||
See the Ultralytics [Quickstart](../quickstart.md/#install-ultralytics) Installation section for a quick walkthrough on installing the required libraries.
|
||||
|
||||
***
|
||||
|
||||
2. Load a model and run `predict()` method on a source.
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n-seg.pt')
|
||||
|
||||
# Run inference
|
||||
results = model.predict()
|
||||
```
|
||||
|
||||
!!! question "No Prediction Arguments?"
|
||||
|
||||
Without specifying a source, the example images from the library will be used:
|
||||
|
||||
```
|
||||
'ultralytics/assets/bus.jpg'
|
||||
'ultralytics/assets/zidane.jpg'
|
||||
```
|
||||
|
||||
This is helpful for rapid testing with the `predict()` method.
|
||||
|
||||
For additional information about Segmentation Models, visit the [Segment Task](../tasks/segment.md#models) page. To learn more about `predict()` method, see [Predict Mode](../modes/predict.md) section of the Documentation.
|
||||
|
||||
***
|
||||
|
||||
3. Now iterate over the results and the contours. For workflows that want to save an image to file, the source image `base-name` and the detection `class-label` are retrieved for later use (optional).
|
||||
|
||||
```{ .py .annotate }
|
||||
# (2) Iterate detection results (helpful for multiple images)
|
||||
for r in res:
|
||||
img = np.copy(r.orig_img)
|
||||
img_name = Path(r.path).stem # source image base-name
|
||||
|
||||
# Iterate each object contour (multiple detections)
|
||||
for ci,c in enumerate(r):
|
||||
# (1) Get detection class name
|
||||
label = c.names[c.boxes.cls.tolist().pop()]
|
||||
|
||||
```
|
||||
|
||||
1. To learn more about working with detection results, see [Boxes Section for Predict Mode](../modes/predict.md#boxes).
|
||||
2. To learn more about `predict()` results see [Working with Results for Predict Mode](../modes/predict.md#working-with-results)
|
||||
|
||||
??? info "For-Loop"
|
||||
|
||||
A single image will only iterate the first loop once. A single image with only a single detection will iterate each loop _only_ once.
|
||||
|
||||
***
|
||||
|
||||
4. Start with generating a binary mask from the source image and then draw a filled contour onto the mask. This will allow the object to be isolated from the other parts of the image. An example from `bus.jpg` for one of the detected `person` class objects is shown on the right.
|
||||
|
||||
{ width="240", align="right" }
|
||||
|
||||
```{ .py .annotate }
|
||||
# Create binary mask
|
||||
b_mask = np.zeros(img.shape[:2], np.uint8)
|
||||
|
||||
# (1) Extract contour result
|
||||
contour = c.masks.xy.pop()
|
||||
# (2) Changing the type
|
||||
contour = contour.astype(np.int32)
|
||||
# (3) Reshaping
|
||||
contour = contour.reshape(-1, 1, 2)
|
||||
|
||||
|
||||
# Draw contour onto mask
|
||||
_ = cv2.drawContours(b_mask,
|
||||
[contour],
|
||||
-1,
|
||||
(255, 255, 255),
|
||||
cv2.FILLED)
|
||||
|
||||
```
|
||||
|
||||
1. For more info on `c.masks.xy` see [Masks Section from Predict Mode](../modes/predict.md#masks).
|
||||
|
||||
2. Here, the values are cast into `np.int32` for compatibility with `drawContours()` function from OpenCV.
|
||||
|
||||
3. The OpenCV `drawContours()` function expects contours to have a shape of `[N, 1, 2]` expand section below for more details.
|
||||
|
||||
<details>
|
||||
<summary> Expand to understand what is happening when defining the <code>contour</code> variable.</summary>
|
||||
<p>
|
||||
|
||||
- `c.masks.xy` :: Provides the coordinates of the mask contour points in the format `(x, y)`. For more details, refer to the [Masks Section from Predict Mode](../modes/predict.md#masks).
|
||||
|
||||
- `.pop()` :: As `masks.xy` is a list containing a single element, this element is extracted using the `pop()` method.
|
||||
|
||||
- `.astype(np.int32)` :: Using `masks.xy` will return with a data type of `float32`, but this won't be compatible with the OpenCV `drawContours()` function, so this will change the data type to `int32` for compatibility.
|
||||
|
||||
- `.reshape(-1, 1, 2)` :: Reformats the data into the required shape of `[N, 1, 2]` where `N` is the number of contour points, with each point represented by a single entry `1`, and the entry is composed of `2` values. The `-1` denotes that the number of values along this dimension is flexible.
|
||||
|
||||
</details>
|
||||
<p></p>
|
||||
<details>
|
||||
<summary> Expand for an explanation of the <code>drawContours()</code> configuration.</summary>
|
||||
<p>
|
||||
|
||||
- Encapsulating the `contour` variable within square brackets, `[contour]`, was found to effectively generate the desired contour mask during testing.
|
||||
|
||||
- The value `-1` specified for the `drawContours()` parameter instructs the function to draw all contours present in the image.
|
||||
|
||||
- The `tuple` `(255, 255, 255)` represents the color white, which is the desired color for drawing the contour in this binary mask.
|
||||
|
||||
- The addition of `cv2.FILLED` will color all pixels enclosed by the contour boundary the same, in this case, all enclosed pixels will be white.
|
||||
|
||||
- See [OpenCV Documentation on `drawContours()`](https://docs.opencv.org/4.8.0/d6/d6e/group__imgproc__draw.html#ga746c0625f1781f1ffc9056259103edbc) for more information.
|
||||
|
||||
</details>
|
||||
<p></p>
|
||||
|
||||
***
|
||||
|
||||
5. Next the there are 2 options for how to move forward with the image from this point and a subsequent option for each.
|
||||
|
||||
### Object Isolation Options
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Black Background Pixels"
|
||||
|
||||
```py
|
||||
# Create 3-channel mask
|
||||
mask3ch = cv2.cvtColor(b_mask, cv2.COLOR_GRAY2BGR)
|
||||
|
||||
# Isolate object with binary mask
|
||||
isolated = cv2.bitwise_and(mask3ch, img)
|
||||
|
||||
```
|
||||
|
||||
??? question "How does this work?"
|
||||
|
||||
- First, the binary mask is first converted from a single-channel image to a three-channel image. This conversion is necessary for the subsequent step where the mask and the original image are combined. Both images must have the same number of channels to be compatible with the blending operation.
|
||||
|
||||
- The original image and the three-channel binary mask are merged using the OpenCV function `bitwise_and()`. This operation retains <u>only</u> pixel values that are greater than zero `(> 0)` from both images. Since the mask pixels are greater than zero `(> 0)` <u>only</u> within the contour region, the pixels remaining from the original image are those that overlap with the contour.
|
||||
|
||||
### Isolate with Black Pixels: Sub-options
|
||||
|
||||
??? info "Full-size Image"
|
||||
|
||||
There are no additional steps required if keeping full size image.
|
||||
|
||||
<figure markdown>
|
||||
{ width=240 }
|
||||
<figcaption>Example full-size output</figcaption>
|
||||
</figure>
|
||||
|
||||
??? info "Cropped object Image"
|
||||
|
||||
Additional steps required to crop image to only include object region.
|
||||
|
||||
{ align="right" }
|
||||
``` { .py .annotate }
|
||||
# (1) Bounding box coordinates
|
||||
x1, y1, x2, y2 = c.boxes.xyxy.cpu().numpy().squeeze().astype(np.int32)
|
||||
# Crop image to object region
|
||||
iso_crop = isolated[y1:y2, x1:x2]
|
||||
|
||||
```
|
||||
|
||||
1. For more information on bounding box results, see [Boxes Section from Predict Mode](../modes/predict.md/#boxes)
|
||||
|
||||
??? question "What does this code do?"
|
||||
|
||||
- The `c.boxes.xyxy.cpu().numpy()` call retrieves the bounding boxes as a NumPy array in the `xyxy` format, where `xmin`, `ymin`, `xmax`, and `ymax` represent the coordinates of the bounding box rectangle. See [Boxes Section from Predict Mode](../modes/predict.md/#boxes) for more details.
|
||||
|
||||
- The `squeeze()` operation removes any unnecessary dimensions from the NumPy array, ensuring it has the expected shape.
|
||||
|
||||
- Converting the coordinate values using `.astype(np.int32)` changes the box coordinates data type from `float32` to `int32`, making them compatible for image cropping using index slices.
|
||||
|
||||
- Finally, the bounding box region is cropped from the image using index slicing. The bounds are defined by the `[ymin:ymax, xmin:xmax]` coordinates of the detection bounding box.
|
||||
|
||||
=== "Transparent Background Pixels"
|
||||
|
||||
```py
|
||||
# Isolate object with transparent background (when saved as PNG)
|
||||
isolated = np.dstack([img, b_mask])
|
||||
|
||||
```
|
||||
|
||||
??? question "How does this work?"
|
||||
|
||||
- Using the NumPy `dstack()` function (array stacking along depth-axis) in conjunction with the binary mask generated, will create an image with four channels. This allows for all pixels outside of the object contour to be transparent when saving as a `PNG` file.
|
||||
|
||||
### Isolate with Transparent Pixels: Sub-options
|
||||
|
||||
??? info "Full-size Image"
|
||||
|
||||
There are no additional steps required if keeping full size image.
|
||||
|
||||
<figure markdown>
|
||||
{ width=240 }
|
||||
<figcaption>Example full-size output + transparent background</figcaption>
|
||||
</figure>
|
||||
|
||||
??? info "Cropped object Image"
|
||||
|
||||
Additional steps required to crop image to only include object region.
|
||||
|
||||
{ align="right" }
|
||||
``` { .py .annotate }
|
||||
# (1) Bounding box coordinates
|
||||
x1, y1, x2, y2 = c.boxes.xyxy.cpu().numpy().squeeze().astype(np.int32)
|
||||
# Crop image to object region
|
||||
iso_crop = isolated[y1:y2, x1:x2]
|
||||
|
||||
```
|
||||
|
||||
1. For more information on bounding box results, see [Boxes Section from Predict Mode](../modes/predict.md/#boxes)
|
||||
|
||||
??? question "What does this code do?"
|
||||
|
||||
- When using `c.boxes.xyxy.cpu().numpy()`, the bounding boxes are returned as a NumPy array, using the `xyxy` box coordinates format, which correspond to the points `xmin, ymin, xmax, ymax` for the bounding box (rectangle), see [Boxes Section from Predict Mode](../modes/predict.md/#boxes) for more information.
|
||||
|
||||
- Adding `squeeze()` ensures that any extraneous dimensions are removed from the NumPy array.
|
||||
|
||||
- Converting the coordinate values using `.astype(np.int32)` changes the box coordinates data type from `float32` to `int32` which will be compatible when cropping the image using index slices.
|
||||
|
||||
- Finally the image region for the bounding box is cropped using index slicing, where the bounds are set using the `[ymin:ymax, xmin:xmax]` coordinates of the detection bounding box.
|
||||
|
||||
??? question "What if I want the cropped object **including** the background?"
|
||||
|
||||
This is a built in feature for the Ultralytics library. See the `save_crop` argument for [Predict Mode Inference Arguments](../modes/predict.md/#inference-arguments) for details.
|
||||
|
||||
***
|
||||
|
||||
6. <u>What to do next is entirely left to you as the developer.</u> A basic example of one possible next step (saving the image to file for future use) is shown.
|
||||
|
||||
- **NOTE:** this step is optional and can be skipped if not required for your specific use case.
|
||||
|
||||
??? example "Example Final Step"
|
||||
|
||||
```py
|
||||
# Save isolated object to file
|
||||
_ = cv2.imwrite(f'{img_name}_{label}-{ci}.png', iso_crop)
|
||||
```
|
||||
|
||||
- In this example, the `img_name` is the base-name of the source image file, `label` is the detected class-name, and `ci` is the index of the object detection (in case of multiple instances with the same class name).
|
||||
|
||||
## Full Example code
|
||||
|
||||
Here, all steps from the previous section are combined into a single block of code. For repeated use, it would be optimal to define a function to do some or all commands contained in the `for`-loops, but that is an exercise left to the reader.
|
||||
|
||||
```{ .py .annotate }
|
||||
from pathlib import Path
|
||||
|
||||
import cv2
|
||||
import numpy as np
|
||||
from ultralytics import YOLO
|
||||
|
||||
m = YOLO('yolov8n-seg.pt')#(4)!
|
||||
res = m.predict()#(3)!
|
||||
|
||||
# iterate detection results (5)
|
||||
for r in res:
|
||||
img = np.copy(r.orig_img)
|
||||
img_name = Path(r.path).stem
|
||||
|
||||
# iterate each object contour (6)
|
||||
for ci,c in enumerate(r):
|
||||
label = c.names[c.boxes.cls.tolist().pop()]
|
||||
|
||||
b_mask = np.zeros(img.shape[:2], np.uint8)
|
||||
|
||||
# Create contour mask (1)
|
||||
contour = c.masks.xy.pop().astype(np.int32).reshape(-1, 1, 2)
|
||||
_ = cv2.drawContours(b_mask, [contour], -1, (255, 255, 255), cv2.FILLED)
|
||||
|
||||
# Choose one:
|
||||
|
||||
# OPTION-1: Isolate object with black background
|
||||
mask3ch = cv2.cvtColor(b_mask, cv2.COLOR_GRAY2BGR)
|
||||
isolated = cv2.bitwise_and(mask3ch, img)
|
||||
|
||||
# OPTION-2: Isolate object with transparent background (when saved as PNG)
|
||||
isolated = np.dstack([img, b_mask])
|
||||
|
||||
# OPTIONAL: detection crop (from either OPT1 or OPT2)
|
||||
x1, y1, x2, y2 = c.boxes.xyxy.cpu().numpy().squeeze().astype(np.int32)
|
||||
iso_crop = isolated[y1:y2, x1:x2]
|
||||
|
||||
# TODO your actions go here (2)
|
||||
|
||||
```
|
||||
|
||||
1. The line populating `contour` is combined into a single line here, where it was split to multiple above.
|
||||
2. {==What goes here is up to you!==}
|
||||
3. See [Predict Mode](../modes/predict.md) for additional information.
|
||||
4. See [Segment Task](../tasks/segment.md#models) for more information.
|
||||
5. Learn more about [Working with Results](../modes/predict.md#working-with-results)
|
||||
6. Learn more about [Segmentation Mask Results](../modes/predict.md#masks)
|
||||
278
docs/en/guides/kfold-cross-validation.md
Normal file
278
docs/en/guides/kfold-cross-validation.md
Normal file
@ -0,0 +1,278 @@
|
||||
---
|
||||
comments: true
|
||||
description: An in-depth guide demonstrating the implementation of K-Fold Cross Validation with the Ultralytics ecosystem for object detection datasets, leveraging Python, YOLO, and sklearn.
|
||||
keywords: K-Fold cross validation, Ultralytics, YOLO detection format, Python, sklearn, object detection
|
||||
---
|
||||
|
||||
# K-Fold Cross Validation with Ultralytics
|
||||
|
||||
## Introduction
|
||||
|
||||
This comprehensive guide illustrates the implementation of K-Fold Cross Validation for object detection datasets within the Ultralytics ecosystem. We'll leverage the YOLO detection format and key Python libraries such as sklearn, pandas, and PyYaml to guide you through the necessary setup, the process of generating feature vectors, and the execution of a K-Fold dataset split.
|
||||
|
||||
<p align="center">
|
||||
<img width="800" src="https://user-images.githubusercontent.com/26833433/258589390-8d815058-ece8-48b9-a94e-0e1ab53ea0f6.png" alt="K-Fold Cross Validation Overview">
|
||||
</p>
|
||||
|
||||
Whether your project involves the Fruit Detection dataset or a custom data source, this tutorial aims to help you comprehend and apply K-Fold Cross Validation to bolster the reliability and robustness of your machine learning models. While we're applying `k=5` folds for this tutorial, keep in mind that the optimal number of folds can vary depending on your dataset and the specifics of your project.
|
||||
|
||||
Without further ado, let's dive in!
|
||||
|
||||
## Setup
|
||||
|
||||
- Your annotations should be in the [YOLO detection format](../datasets/detect/index.md).
|
||||
|
||||
- This guide assumes that annotation files are locally available.
|
||||
|
||||
- For our demonstration, we use the [Fruit Detection](https://www.kaggle.com/datasets/lakshaytyagi01/fruit-detection/code) dataset.
|
||||
- This dataset contains a total of 8479 images.
|
||||
- It includes 6 class labels, each with its total instance counts listed below.
|
||||
|
||||
| Class Label | Instance Count |
|
||||
|:------------|:--------------:|
|
||||
| Apple | 7049 |
|
||||
| Grapes | 7202 |
|
||||
| Pineapple | 1613 |
|
||||
| Orange | 15549 |
|
||||
| Banana | 3536 |
|
||||
| Watermelon | 1976 |
|
||||
|
||||
- Necessary Python packages include:
|
||||
|
||||
- `ultralytics`
|
||||
- `sklearn`
|
||||
- `pandas`
|
||||
- `pyyaml`
|
||||
|
||||
- This tutorial operates with `k=5` folds. However, you should determine the best number of folds for your specific dataset.
|
||||
|
||||
1. Initiate a new Python virtual environment (`venv`) for your project and activate it. Use `pip` (or your preferred package manager) to install:
|
||||
|
||||
- The Ultralytics library: `pip install -U ultralytics`. Alternatively, you can clone the official [repo](https://github.com/ultralytics/ultralytics).
|
||||
- Scikit-learn, pandas, and PyYAML: `pip install -U scikit-learn pandas pyyaml`.
|
||||
|
||||
2. Verify that your annotations are in the [YOLO detection format](../datasets/detect/index.md).
|
||||
|
||||
- For this tutorial, all annotation files are found in the `Fruit-Detection/labels` directory.
|
||||
|
||||
## Generating Feature Vectors for Object Detection Dataset
|
||||
|
||||
1. Start by creating a new Python file and import the required libraries.
|
||||
|
||||
```python
|
||||
import datetime
|
||||
import shutil
|
||||
from pathlib import Path
|
||||
from collections import Counter
|
||||
|
||||
import yaml
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
from ultralytics import YOLO
|
||||
from sklearn.model_selection import KFold
|
||||
```
|
||||
|
||||
2. Proceed to retrieve all label files for your dataset.
|
||||
|
||||
```python
|
||||
dataset_path = Path('./Fruit-detection') # replace with 'path/to/dataset' for your custom data
|
||||
labels = sorted(dataset_path.rglob("*labels/*.txt")) # all data in 'labels'
|
||||
```
|
||||
|
||||
3. Now, read the contents of the dataset YAML file and extract the indices of the class labels.
|
||||
|
||||
```python
|
||||
yaml_file = 'path/to/data.yaml' # your data YAML with data directories and names dictionary
|
||||
with open(yaml_file, 'r', encoding="utf8") as y:
|
||||
classes = yaml.safe_load(y)['names']
|
||||
cls_idx = sorted(classes.keys())
|
||||
```
|
||||
|
||||
4. Initialize an empty `pandas` DataFrame.
|
||||
|
||||
```python
|
||||
indx = [l.stem for l in labels] # uses base filename as ID (no extension)
|
||||
labels_df = pd.DataFrame([], columns=cls_idx, index=indx)
|
||||
```
|
||||
|
||||
5. Count the instances of each class-label present in the annotation files.
|
||||
|
||||
```python
|
||||
for label in labels:
|
||||
lbl_counter = Counter()
|
||||
|
||||
with open(label,'r') as lf:
|
||||
lines = lf.readlines()
|
||||
|
||||
for l in lines:
|
||||
# classes for YOLO label uses integer at first position of each line
|
||||
lbl_counter[int(l.split(' ')[0])] += 1
|
||||
|
||||
labels_df.loc[label.stem] = lbl_counter
|
||||
|
||||
labels_df = labels_df.fillna(0.0) # replace `nan` values with `0.0`
|
||||
```
|
||||
|
||||
6. The following is a sample view of the populated DataFrame:
|
||||
|
||||
```pandas
|
||||
0 1 2 3 4 5
|
||||
'0000a16e4b057580_jpg.rf.00ab48988370f64f5ca8ea4...' 0.0 0.0 0.0 0.0 0.0 7.0
|
||||
'0000a16e4b057580_jpg.rf.7e6dce029fb67f01eb19aa7...' 0.0 0.0 0.0 0.0 0.0 7.0
|
||||
'0000a16e4b057580_jpg.rf.bc4d31cdcbe229dd022957a...' 0.0 0.0 0.0 0.0 0.0 7.0
|
||||
'00020ebf74c4881c_jpg.rf.508192a0a97aa6c4a3b6882...' 0.0 0.0 0.0 1.0 0.0 0.0
|
||||
'00020ebf74c4881c_jpg.rf.5af192a2254c8ecc4188a25...' 0.0 0.0 0.0 1.0 0.0 0.0
|
||||
... ... ... ... ... ... ...
|
||||
'ff4cd45896de38be_jpg.rf.c4b5e967ca10c7ced3b9e97...' 0.0 0.0 0.0 0.0 0.0 2.0
|
||||
'ff4cd45896de38be_jpg.rf.ea4c1d37d2884b3e3cbce08...' 0.0 0.0 0.0 0.0 0.0 2.0
|
||||
'ff5fd9c3c624b7dc_jpg.rf.bb519feaa36fc4bf630a033...' 1.0 0.0 0.0 0.0 0.0 0.0
|
||||
'ff5fd9c3c624b7dc_jpg.rf.f0751c9c3aa4519ea3c9d6a...' 1.0 0.0 0.0 0.0 0.0 0.0
|
||||
'fffe28b31f2a70d4_jpg.rf.7ea16bd637ba0711c53b540...' 0.0 6.0 0.0 0.0 0.0 0.0
|
||||
```
|
||||
|
||||
The rows index the label files, each corresponding to an image in your dataset, and the columns correspond to your class-label indices. Each row represents a pseudo feature-vector, with the count of each class-label present in your dataset. This data structure enables the application of K-Fold Cross Validation to an object detection dataset.
|
||||
|
||||
## K-Fold Dataset Split
|
||||
|
||||
1. Now we will use the `KFold` class from `sklearn.model_selection` to generate `k` splits of the dataset.
|
||||
|
||||
- Important:
|
||||
- Setting `shuffle=True` ensures a randomized distribution of classes in your splits.
|
||||
- By setting `random_state=M` where `M` is a chosen integer, you can obtain repeatable results.
|
||||
|
||||
```python
|
||||
ksplit = 5
|
||||
kf = KFold(n_splits=ksplit, shuffle=True, random_state=20) # setting random_state for repeatable results
|
||||
|
||||
kfolds = list(kf.split(labels_df))
|
||||
```
|
||||
|
||||
2. The dataset has now been split into `k` folds, each having a list of `train` and `val` indices. We will construct a DataFrame to display these results more clearly.
|
||||
|
||||
```python
|
||||
folds = [f'split_{n}' for n in range(1, ksplit + 1)]
|
||||
folds_df = pd.DataFrame(index=indx, columns=folds)
|
||||
|
||||
for idx, (train, val) in enumerate(kfolds, start=1):
|
||||
folds_df[f'split_{idx}'].loc[labels_df.iloc[train].index] = 'train'
|
||||
folds_df[f'split_{idx}'].loc[labels_df.iloc[val].index] = 'val'
|
||||
```
|
||||
|
||||
3. Now we will calculate the distribution of class labels for each fold as a ratio of the classes present in `val` to those present in `train`.
|
||||
|
||||
```python
|
||||
fold_lbl_distrb = pd.DataFrame(index=folds, columns=cls_idx)
|
||||
|
||||
for n, (train_indices, val_indices) in enumerate(kfolds, start=1):
|
||||
train_totals = labels_df.iloc[train_indices].sum()
|
||||
val_totals = labels_df.iloc[val_indices].sum()
|
||||
|
||||
# To avoid division by zero, we add a small value (1E-7) to the denominator
|
||||
ratio = val_totals / (train_totals + 1E-7)
|
||||
fold_lbl_distrb.loc[f'split_{n}'] = ratio
|
||||
```
|
||||
|
||||
The ideal scenario is for all class ratios to be reasonably similar for each split and across classes. This, however, will be subject to the specifics of your dataset.
|
||||
|
||||
4. Next, we create the directories and dataset YAML files for each split.
|
||||
|
||||
```python
|
||||
supported_extensions = ['.jpg', '.jpeg', '.png']
|
||||
|
||||
# Initialize an empty list to store image file paths
|
||||
images = []
|
||||
|
||||
# Loop through supported extensions and gather image files
|
||||
for ext in supported_extensions:
|
||||
images.extend(sorted((dataset_path / 'images').rglob(f"*{ext}")))
|
||||
|
||||
# Create the necessary directories and dataset YAML files (unchanged)
|
||||
save_path = Path(dataset_path / f'{datetime.date.today().isoformat()}_{ksplit}-Fold_Cross-val')
|
||||
save_path.mkdir(parents=True, exist_ok=True)
|
||||
ds_yamls = []
|
||||
|
||||
for split in folds_df.columns:
|
||||
# Create directories
|
||||
split_dir = save_path / split
|
||||
split_dir.mkdir(parents=True, exist_ok=True)
|
||||
(split_dir / 'train' / 'images').mkdir(parents=True, exist_ok=True)
|
||||
(split_dir / 'train' / 'labels').mkdir(parents=True, exist_ok=True)
|
||||
(split_dir / 'val' / 'images').mkdir(parents=True, exist_ok=True)
|
||||
(split_dir / 'val' / 'labels').mkdir(parents=True, exist_ok=True)
|
||||
|
||||
# Create dataset YAML files
|
||||
dataset_yaml = split_dir / f'{split}_dataset.yaml'
|
||||
ds_yamls.append(dataset_yaml)
|
||||
|
||||
with open(dataset_yaml, 'w') as ds_y:
|
||||
yaml.safe_dump({
|
||||
'path': split_dir.as_posix(),
|
||||
'train': 'train',
|
||||
'val': 'val',
|
||||
'names': classes
|
||||
}, ds_y)
|
||||
```
|
||||
|
||||
5. Lastly, copy images and labels into the respective directory ('train' or 'val') for each split.
|
||||
|
||||
- __NOTE:__ The time required for this portion of the code will vary based on the size of your dataset and your system hardware.
|
||||
|
||||
```python
|
||||
for image, label in zip(images, labels):
|
||||
for split, k_split in folds_df.loc[image.stem].items():
|
||||
# Destination directory
|
||||
img_to_path = save_path / split / k_split / 'images'
|
||||
lbl_to_path = save_path / split / k_split / 'labels'
|
||||
|
||||
# Copy image and label files to new directory (SamefileError if file already exists)
|
||||
shutil.copy(image, img_to_path / image.name)
|
||||
shutil.copy(label, lbl_to_path / label.name)
|
||||
```
|
||||
|
||||
## Save Records (Optional)
|
||||
|
||||
Optionally, you can save the records of the K-Fold split and label distribution DataFrames as CSV files for future reference.
|
||||
|
||||
```python
|
||||
folds_df.to_csv(save_path / "kfold_datasplit.csv")
|
||||
fold_lbl_distrb.to_csv(save_path / "kfold_label_distribution.csv")
|
||||
```
|
||||
|
||||
## Train YOLO using K-Fold Data Splits
|
||||
|
||||
1. First, load the YOLO model.
|
||||
|
||||
```python
|
||||
weights_path = 'path/to/weights.pt'
|
||||
model = YOLO(weights_path, task='detect')
|
||||
```
|
||||
|
||||
2. Next, iterate over the dataset YAML files to run training. The results will be saved to a directory specified by the `project` and `name` arguments. By default, this directory is 'exp/runs#' where # is an integer index.
|
||||
|
||||
```python
|
||||
results = {}
|
||||
|
||||
# Define your additional arguments here
|
||||
batch = 16
|
||||
project = 'kfold_demo'
|
||||
epochs = 100
|
||||
|
||||
for k in range(ksplit):
|
||||
dataset_yaml = ds_yamls[k]
|
||||
model.train(data=dataset_yaml,epochs=epochs, batch=batch, project=project) # include any train arguments
|
||||
results[k] = model.metrics # save output metrics for further analysis
|
||||
```
|
||||
|
||||
## Conclusion
|
||||
|
||||
In this guide, we have explored the process of using K-Fold cross-validation for training the YOLO object detection model. We learned how to split our dataset into K partitions, ensuring a balanced class distribution across the different folds.
|
||||
|
||||
We also explored the procedure for creating report DataFrames to visualize the data splits and label distributions across these splits, providing us a clear insight into the structure of our training and validation sets.
|
||||
|
||||
Optionally, we saved our records for future reference, which could be particularly useful in large-scale projects or when troubleshooting model performance.
|
||||
|
||||
Finally, we implemented the actual model training using each split in a loop, saving our training results for further analysis and comparison.
|
||||
|
||||
This technique of K-Fold cross-validation is a robust way of making the most out of your available data, and it helps to ensure that your model performance is reliable and consistent across different data subsets. This results in a more generalizable and reliable model that is less likely to overfit to specific data patterns.
|
||||
|
||||
Remember that although we used YOLO in this guide, these steps are mostly transferable to other machine learning models. Understanding these steps allows you to apply cross-validation effectively in your own machine learning projects. Happy coding!
|
||||
305
docs/en/guides/model-deployment-options.md
Normal file
305
docs/en/guides/model-deployment-options.md
Normal file
@ -0,0 +1,305 @@
|
||||
---
|
||||
comments: true
|
||||
description: A guide to help determine which deployment option to choose for your YOLOv8 model, including essential considerations.
|
||||
keywords: YOLOv8, Deployment, PyTorch, TorchScript, ONNX, OpenVINO, TensorRT, CoreML, TensorFlow, Export
|
||||
---
|
||||
|
||||
# Understanding YOLOv8’s Deployment Options
|
||||
|
||||
## Introduction
|
||||
|
||||
You've come a long way on your journey with YOLOv8. You've diligently collected data, meticulously annotated it, and put in the hours to train and rigorously evaluate your custom YOLOv8 model. Now, it’s time to put your model to work for your specific application, use case, or project. But there's a critical decision that stands before you: how to export and deploy your model effectively.
|
||||
|
||||
This guide walks you through YOLOv8’s deployment options and the essential factors to consider to choose the right option for your project.
|
||||
|
||||
## How to Select the Right Deployment Option for Your YOLOv8 Model
|
||||
|
||||
When it's time to deploy your YOLOv8 model, selecting a suitable export format is very important. As outlined in the [Ultralytics YOLOv8 Modes documentation](../modes/export.md#usage-examples), the model.export() function allows for converting your trained model into a variety of formats tailored to diverse environments and performance requirements.
|
||||
|
||||
The ideal format depends on your model's intended operational context, balancing speed, hardware constraints, and ease of integration. In the following section, we'll take a closer look at each export option, understanding when to choose each one.
|
||||
|
||||
### YOLOv8’s Deployment Options
|
||||
|
||||
Let’s walk through the different YOLOv8 deployment options. For a detailed walkthrough of the export process, visit the [Ultralytics documentation page on exporting](../modes/export.md).
|
||||
|
||||
#### PyTorch
|
||||
|
||||
PyTorch is an open-source machine learning library widely used for applications in deep learning and artificial intelligence. It provides a high level of flexibility and speed, which has made it a favorite among researchers and developers.
|
||||
|
||||
- **Performance Benchmarks**: PyTorch is known for its ease of use and flexibility, which may result in a slight trade-off in raw performance when compared to other frameworks that are more specialized and optimized.
|
||||
|
||||
- **Compatibility and Integration**: Offers excellent compatibility with various data science and machine learning libraries in Python.
|
||||
|
||||
- **Community Support and Ecosystem**: One of the most vibrant communities, with extensive resources for learning and troubleshooting.
|
||||
|
||||
- **Case Studies**: Commonly used in research prototypes, many academic papers reference models deployed in PyTorch.
|
||||
|
||||
- **Maintenance and Updates**: Regular updates with active development and support for new features.
|
||||
|
||||
- **Security Considerations**: Regular patches for security issues, but security is largely dependent on the overall environment it’s deployed in.
|
||||
|
||||
- **Hardware Acceleration**: Supports CUDA for GPU acceleration, essential for speeding up model training and inference.
|
||||
|
||||
#### TorchScript
|
||||
|
||||
TorchScript extends PyTorch’s capabilities by allowing the exportation of models to be run in a C++ runtime environment. This makes it suitable for production environments where Python is unavailable.
|
||||
|
||||
- **Performance Benchmarks**: Can offer improved performance over native PyTorch, especially in production environments.
|
||||
|
||||
- **Compatibility and Integration**: Designed for seamless transition from PyTorch to C++ production environments, though some advanced features might not translate perfectly.
|
||||
|
||||
- **Community Support and Ecosystem**: Benefits from PyTorch’s large community but has a narrower scope of specialized developers.
|
||||
|
||||
- **Case Studies**: Widely used in industry settings where Python’s performance overhead is a bottleneck.
|
||||
|
||||
- **Maintenance and Updates**: Maintained alongside PyTorch with consistent updates.
|
||||
|
||||
- **Security Considerations**: Offers improved security by enabling the running of models in environments without full Python installations.
|
||||
|
||||
- **Hardware Acceleration**: Inherits PyTorch’s CUDA support, ensuring efficient GPU utilization.
|
||||
|
||||
#### ONNX
|
||||
|
||||
The Open Neural Network Exchange (ONNX) is a format that allows for model interoperability across different frameworks, which can be critical when deploying to various platforms.
|
||||
|
||||
- **Performance Benchmarks**: ONNX models may experience a variable performance depending on the specific runtime they are deployed on.
|
||||
|
||||
- **Compatibility and Integration**: High interoperability across multiple platforms and hardware due to its framework-agnostic nature.
|
||||
|
||||
- **Community Support and Ecosystem**: Supported by many organizations, leading to a broad ecosystem and a variety of tools for optimization.
|
||||
|
||||
- **Case Studies**: Frequently used to move models between different machine learning frameworks, demonstrating its flexibility.
|
||||
|
||||
- **Maintenance and Updates**: As an open standard, ONNX is regularly updated to support new operations and models.
|
||||
|
||||
- **Security Considerations**: As with any cross-platform tool, it's essential to ensure secure practices in the conversion and deployment pipeline.
|
||||
|
||||
- **Hardware Acceleration**: With ONNX Runtime, models can leverage various hardware optimizations.
|
||||
|
||||
#### OpenVINO
|
||||
|
||||
OpenVINO is an Intel toolkit designed to facilitate the deployment of deep learning models across Intel hardware, enhancing performance and speed.
|
||||
|
||||
- **Performance Benchmarks**: Specifically optimized for Intel CPUs, GPUs, and VPUs, offering significant performance boosts on compatible hardware.
|
||||
|
||||
- **Compatibility and Integration**: Works best within the Intel ecosystem but also supports a range of other platforms.
|
||||
|
||||
- **Community Support and Ecosystem**: Backed by Intel, with a solid user base especially in the computer vision domain.
|
||||
|
||||
- **Case Studies**: Often utilized in IoT and edge computing scenarios where Intel hardware is prevalent.
|
||||
|
||||
- **Maintenance and Updates**: Intel regularly updates OpenVINO to support the latest deep learning models and Intel hardware.
|
||||
|
||||
- **Security Considerations**: Provides robust security features suitable for deployment in sensitive applications.
|
||||
|
||||
- **Hardware Acceleration**: Tailored for acceleration on Intel hardware, leveraging dedicated instruction sets and hardware features.
|
||||
|
||||
For more details on deployment using OpenVINO, refer to the Ultralytics Integration documentation: [Intel OpenVINO Export](../integrations/openvino.md).
|
||||
|
||||
#### TensorRT
|
||||
|
||||
TensorRT is a high-performance deep learning inference optimizer and runtime from NVIDIA, ideal for applications needing speed and efficiency.
|
||||
|
||||
- **Performance Benchmarks**: Delivers top-tier performance on NVIDIA GPUs with support for high-speed inference.
|
||||
|
||||
- **Compatibility and Integration**: Best suited for NVIDIA hardware, with limited support outside this environment.
|
||||
|
||||
- **Community Support and Ecosystem**: Strong support network through NVIDIA’s developer forums and documentation.
|
||||
|
||||
- **Case Studies**: Widely adopted in industries requiring real-time inference on video and image data.
|
||||
|
||||
- **Maintenance and Updates**: NVIDIA maintains TensorRT with frequent updates to enhance performance and support new GPU architectures.
|
||||
|
||||
- **Security Considerations**: Like many NVIDIA products, it has a strong emphasis on security, but specifics depend on the deployment environment.
|
||||
|
||||
- **Hardware Acceleration**: Exclusively designed for NVIDIA GPUs, providing deep optimization and acceleration.
|
||||
|
||||
#### CoreML
|
||||
|
||||
CoreML is Apple’s machine learning framework, optimized for on-device performance in the Apple ecosystem, including iOS, macOS, watchOS, and tvOS.
|
||||
|
||||
- **Performance Benchmarks**: Optimized for on-device performance on Apple hardware with minimal battery usage.
|
||||
|
||||
- **Compatibility and Integration**: Exclusively for Apple's ecosystem, providing a streamlined workflow for iOS and macOS applications.
|
||||
|
||||
- **Community Support and Ecosystem**: Strong support from Apple and a dedicated developer community, with extensive documentation and tools.
|
||||
|
||||
- **Case Studies**: Commonly used in applications that require on-device machine learning capabilities on Apple products.
|
||||
|
||||
- **Maintenance and Updates**: Regularly updated by Apple to support the latest machine learning advancements and Apple hardware.
|
||||
|
||||
- **Security Considerations**: Benefits from Apple's focus on user privacy and data security.
|
||||
|
||||
- **Hardware Acceleration**: Takes full advantage of Apple's neural engine and GPU for accelerated machine learning tasks.
|
||||
|
||||
#### TF SavedModel
|
||||
|
||||
TF SavedModel is TensorFlow’s format for saving and serving machine learning models, particularly suited for scalable server environments.
|
||||
|
||||
- **Performance Benchmarks**: Offers scalable performance in server environments, especially when used with TensorFlow Serving.
|
||||
|
||||
- **Compatibility and Integration**: Wide compatibility across TensorFlow's ecosystem, including cloud and enterprise server deployments.
|
||||
|
||||
- **Community Support and Ecosystem**: Large community support due to TensorFlow's popularity, with a vast array of tools for deployment and optimization.
|
||||
|
||||
- **Case Studies**: Extensively used in production environments for serving deep learning models at scale.
|
||||
|
||||
- **Maintenance and Updates**: Supported by Google and the TensorFlow community, ensuring regular updates and new features.
|
||||
|
||||
- **Security Considerations**: Deployment using TensorFlow Serving includes robust security features for enterprise-grade applications.
|
||||
|
||||
- **Hardware Acceleration**: Supports various hardware accelerations through TensorFlow's backends.
|
||||
|
||||
#### TF GraphDef
|
||||
|
||||
TF GraphDef is a TensorFlow format that represents the model as a graph, which is beneficial for environments where a static computation graph is required.
|
||||
|
||||
- **Performance Benchmarks**: Provides stable performance for static computation graphs, with a focus on consistency and reliability.
|
||||
|
||||
- **Compatibility and Integration**: Easily integrates within TensorFlow's infrastructure but less flexible compared to SavedModel.
|
||||
|
||||
- **Community Support and Ecosystem**: Good support from TensorFlow's ecosystem, with many resources available for optimizing static graphs.
|
||||
|
||||
- **Case Studies**: Useful in scenarios where a static graph is necessary, such as in certain embedded systems.
|
||||
|
||||
- **Maintenance and Updates**: Regular updates alongside TensorFlow's core updates.
|
||||
|
||||
- **Security Considerations**: Ensures safe deployment with TensorFlow's established security practices.
|
||||
|
||||
- **Hardware Acceleration**: Can utilize TensorFlow's hardware acceleration options, though not as flexible as SavedModel.
|
||||
|
||||
#### TF Lite
|
||||
|
||||
TF Lite is TensorFlow’s solution for mobile and embedded device machine learning, providing a lightweight library for on-device inference.
|
||||
|
||||
- **Performance Benchmarks**: Designed for speed and efficiency on mobile and embedded devices.
|
||||
|
||||
- **Compatibility and Integration**: Can be used on a wide range of devices due to its lightweight nature.
|
||||
|
||||
- **Community Support and Ecosystem**: Backed by Google, it has a robust community and a growing number of resources for developers.
|
||||
|
||||
- **Case Studies**: Popular in mobile applications that require on-device inference with minimal footprint.
|
||||
|
||||
- **Maintenance and Updates**: Regularly updated to include the latest features and optimizations for mobile devices.
|
||||
|
||||
- **Security Considerations**: Provides a secure environment for running models on end-user devices.
|
||||
|
||||
- **Hardware Acceleration**: Supports a variety of hardware acceleration options, including GPU and DSP.
|
||||
|
||||
#### TF Edge TPU
|
||||
|
||||
TF Edge TPU is designed for high-speed, efficient computing on Google's Edge TPU hardware, perfect for IoT devices requiring real-time processing.
|
||||
|
||||
- **Performance Benchmarks**: Specifically optimized for high-speed, efficient computing on Google's Edge TPU hardware.
|
||||
|
||||
- **Compatibility and Integration**: Works exclusively with TensorFlow Lite models on Edge TPU devices.
|
||||
|
||||
- **Community Support and Ecosystem**: Growing support with resources provided by Google and third-party developers.
|
||||
|
||||
- **Case Studies**: Used in IoT devices and applications that require real-time processing with low latency.
|
||||
|
||||
- **Maintenance and Updates**: Continually improved upon to leverage the capabilities of new Edge TPU hardware releases.
|
||||
|
||||
- **Security Considerations**: Integrates with Google's robust security for IoT and edge devices.
|
||||
|
||||
- **Hardware Acceleration**: Custom-designed to take full advantage of Google Coral devices.
|
||||
|
||||
#### TF.js
|
||||
|
||||
TensorFlow.js (TF.js) is a library that brings machine learning capabilities directly to the browser, offering a new realm of possibilities for web developers and users alike. It allows for the integration of machine learning models in web applications without the need for back-end infrastructure.
|
||||
|
||||
- **Performance Benchmarks**: Enables machine learning directly in the browser with reasonable performance, depending on the client device.
|
||||
|
||||
- **Compatibility and Integration**: High compatibility with web technologies, allowing for easy integration into web applications.
|
||||
|
||||
- **Community Support and Ecosystem**: Support from a community of web and Node.js developers, with a variety of tools for deploying ML models in browsers.
|
||||
|
||||
- **Case Studies**: Ideal for interactive web applications that benefit from client-side machine learning without the need for server-side processing.
|
||||
|
||||
- **Maintenance and Updates**: Maintained by the TensorFlow team with contributions from the open-source community.
|
||||
|
||||
- **Security Considerations**: Runs within the browser's secure context, utilizing the security model of the web platform.
|
||||
|
||||
- **Hardware Acceleration**: Performance can be enhanced with web-based APIs that access hardware acceleration like WebGL.
|
||||
|
||||
#### PaddlePaddle
|
||||
|
||||
PaddlePaddle is an open-source deep learning framework developed by Baidu. It is designed to be both efficient for researchers and easy to use for developers. It's particularly popular in China and offers specialized support for Chinese language processing.
|
||||
|
||||
- **Performance Benchmarks**: Offers competitive performance with a focus on ease of use and scalability.
|
||||
|
||||
- **Compatibility and Integration**: Well-integrated within Baidu's ecosystem and supports a wide range of applications.
|
||||
|
||||
- **Community Support and Ecosystem**: While the community is smaller globally, it's rapidly growing, especially in China.
|
||||
|
||||
- **Case Studies**: Commonly used in Chinese markets and by developers looking for alternatives to other major frameworks.
|
||||
|
||||
- **Maintenance and Updates**: Regularly updated with a focus on serving Chinese language AI applications and services.
|
||||
|
||||
- **Security Considerations**: Emphasizes data privacy and security, catering to Chinese data governance standards.
|
||||
|
||||
- **Hardware Acceleration**: Supports various hardware accelerations, including Baidu's own Kunlun chips.
|
||||
|
||||
#### NCNN
|
||||
|
||||
NCNN is a high-performance neural network inference framework optimized for the mobile platform. It stands out for its lightweight nature and efficiency, making it particularly well-suited for mobile and embedded devices where resources are limited.
|
||||
|
||||
- **Performance Benchmarks**: Highly optimized for mobile platforms, offering efficient inference on ARM-based devices.
|
||||
|
||||
- **Compatibility and Integration**: Suitable for applications on mobile phones and embedded systems with ARM architecture.
|
||||
|
||||
- **Community Support and Ecosystem**: Supported by a niche but active community focused on mobile and embedded ML applications.
|
||||
|
||||
- **Case Studies**: Favoured for mobile applications where efficiency and speed are critical on Android and other ARM-based systems.
|
||||
|
||||
- **Maintenance and Updates**: Continuously improved to maintain high performance on a range of ARM devices.
|
||||
|
||||
- **Security Considerations**: Focuses on running locally on the device, leveraging the inherent security of on-device processing.
|
||||
|
||||
- **Hardware Acceleration**: Tailored for ARM CPUs and GPUs, with specific optimizations for these architectures.
|
||||
|
||||
## Comparative Analysis of YOLOv8 Deployment Options
|
||||
|
||||
The following table provides a snapshot of the various deployment options available for YOLOv8 models, helping you to assess which may best fit your project needs based on several critical criteria. For an in-depth look at each deployment option's format, please see the [Ultralytics documentation page on export formats](../modes/export.md#export-formats).
|
||||
|
||||
| Deployment Option | Performance Benchmarks | Compatibility and Integration | Community Support and Ecosystem | Case Studies | Maintenance and Updates | Security Considerations | Hardware Acceleration |
|
||||
|-------------------|-------------------------------------------------|------------------------------------------------|-----------------------------------------------|--------------------------------------------|---------------------------------------------|---------------------------------------------------|------------------------------------|
|
||||
| PyTorch | Good flexibility; may trade off raw performance | Excellent with Python libraries | Extensive resources and community | Research and prototypes | Regular, active development | Dependent on deployment environment | CUDA support for GPU acceleration |
|
||||
| TorchScript | Better for production than PyTorch | Smooth transition from PyTorch to C++ | Specialized but narrower than PyTorch | Industry where Python is a bottleneck | Consistent updates with PyTorch | Improved security without full Python | Inherits CUDA support from PyTorch |
|
||||
| ONNX | Variable depending on runtime | High across different frameworks | Broad ecosystem, supported by many orgs | Flexibility across ML frameworks | Regular updates for new operations | Ensure secure conversion and deployment practices | Various hardware optimizations |
|
||||
| OpenVINO | Optimized for Intel hardware | Best within Intel ecosystem | Solid in computer vision domain | IoT and edge with Intel hardware | Regular updates for Intel hardware | Robust features for sensitive applications | Tailored for Intel hardware |
|
||||
| TensorRT | Top-tier on NVIDIA GPUs | Best for NVIDIA hardware | Strong network through NVIDIA | Real-time video and image inference | Frequent updates for new GPUs | Emphasis on security | Designed for NVIDIA GPUs |
|
||||
| CoreML | Optimized for on-device Apple hardware | Exclusive to Apple ecosystem | Strong Apple and developer support | On-device ML on Apple products | Regular Apple updates | Focus on privacy and security | Apple neural engine and GPU |
|
||||
| TF SavedModel | Scalable in server environments | Wide compatibility in TensorFlow ecosystem | Large support due to TensorFlow popularity | Serving models at scale | Regular updates by Google and community | Robust features for enterprise | Various hardware accelerations |
|
||||
| TF GraphDef | Stable for static computation graphs | Integrates well with TensorFlow infrastructure | Resources for optimizing static graphs | Scenarios requiring static graphs | Updates alongside TensorFlow core | Established TensorFlow security practices | TensorFlow acceleration options |
|
||||
| TF Lite | Speed and efficiency on mobile/embedded | Wide range of device support | Robust community, Google backed | Mobile applications with minimal footprint | Latest features for mobile | Secure environment on end-user devices | GPU and DSP among others |
|
||||
| TF Edge TPU | Optimized for Google's Edge TPU hardware | Exclusive to Edge TPU devices | Growing with Google and third-party resources | IoT devices requiring real-time processing | Improvements for new Edge TPU hardware | Google's robust IoT security | Custom-designed for Google Coral |
|
||||
| TF.js | Reasonable in-browser performance | High with web technologies | Web and Node.js developers support | Interactive web applications | TensorFlow team and community contributions | Web platform security model | Enhanced with WebGL and other APIs |
|
||||
| PaddlePaddle | Competitive, easy to use and scalable | Baidu ecosystem, wide application support | Rapidly growing, especially in China | Chinese market and language processing | Focus on Chinese AI applications | Emphasizes data privacy and security | Including Baidu's Kunlun chips |
|
||||
| NCNN | Optimized for mobile ARM-based devices | Mobile and embedded ARM systems | Niche but active mobile/embedded ML community | Android and ARM systems efficiency | High performance maintenance on ARM | On-device security advantages | ARM CPUs and GPUs optimizations |
|
||||
|
||||
This comparative analysis gives you a high-level overview. For deployment, it's essential to consider the specific requirements and constraints of your project, and consult the detailed documentation and resources available for each option.
|
||||
|
||||
## Community and Support
|
||||
|
||||
When you're getting started with YOLOv8, having a helpful community and support can make a significant impact. Here's how to connect with others who share your interests and get the assistance you need.
|
||||
|
||||
### Engage with the Broader Community
|
||||
|
||||
- **GitHub Discussions:** The YOLOv8 repository on GitHub has a "Discussions" section where you can ask questions, report issues, and suggest improvements.
|
||||
|
||||
- **Ultralytics Discord Server:** Ultralytics has a [Discord server](https://ultralytics.com/discord/) where you can interact with other users and developers.
|
||||
|
||||
### Official Documentation and Resources
|
||||
|
||||
- **Ultralytics YOLOv8 Docs:** The [official documentation](../index.md) provides a comprehensive overview of YOLOv8, along with guides on installation, usage, and troubleshooting.
|
||||
|
||||
These resources will help you tackle challenges and stay updated on the latest trends and best practices in the YOLOv8 community.
|
||||
|
||||
## Conclusion
|
||||
|
||||
In this guide, we've explored the different deployment options for YOLOv8. We've also discussed the important factors to consider when making your choice. These options allow you to customize your model for various environments and performance requirements, making it suitable for real-world applications.
|
||||
|
||||
Don't forget that the YOLOv8 and Ultralytics community is a valuable source of help. Connect with other developers and experts to learn unique tips and solutions you might not find in regular documentation. Keep seeking knowledge, exploring new ideas, and sharing your experiences.
|
||||
|
||||
Happy deploying!
|
||||
91
docs/en/guides/object-blurring.md
Normal file
91
docs/en/guides/object-blurring.md
Normal file
@ -0,0 +1,91 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn to blur objects using Ultralytics YOLOv8 for privacy in images and videos.
|
||||
keywords: Ultralytics, YOLOv8, Object Detection, Object Blurring, Privacy Protection, Image Processing, Video Analysis, AI, Machine Learning
|
||||
---
|
||||
|
||||
# Object Blurring using Ultralytics YOLOv8 🚀
|
||||
|
||||
## What is Object Blurring?
|
||||
|
||||
Object blurring with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves applying a blurring effect to specific detected objects in an image or video. This can be achieved using the YOLOv8 model capabilities to identify and manipulate objects within a given scene.
|
||||
|
||||
## Advantages of Object Blurring?
|
||||
|
||||
- **Privacy Protection**: Object blurring is an effective tool for safeguarding privacy by concealing sensitive or personally identifiable information in images or videos.
|
||||
- **Selective Focus**: YOLOv8 allows for selective blurring, enabling users to target specific objects, ensuring a balance between privacy and retaining relevant visual information.
|
||||
- **Real-time Processing**: YOLOv8's efficiency enables object blurring in real-time, making it suitable for applications requiring on-the-fly privacy enhancements in dynamic environments.
|
||||
|
||||
!!! Example "Object Blurring using YOLOv8 Example"
|
||||
|
||||
=== "Object Blurring"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.utils.plotting import Annotator, colors
|
||||
import cv2
|
||||
|
||||
model = YOLO("yolov8n.pt")
|
||||
names = model.names
|
||||
|
||||
cap = cv2.VideoCapture("path/to/video/file.mp4")
|
||||
assert cap.isOpened(), "Error reading video file"
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
# Blur ratio
|
||||
blur_ratio = 50
|
||||
|
||||
# Video writer
|
||||
video_writer = cv2.VideoWriter("object_blurring_output.avi",
|
||||
cv2.VideoWriter_fourcc(*'mp4v'),
|
||||
fps, (w, h))
|
||||
|
||||
while cap.isOpened():
|
||||
success, im0 = cap.read()
|
||||
if not success:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
|
||||
results = model.predict(im0, show=False)
|
||||
boxes = results[0].boxes.xyxy.cpu().tolist()
|
||||
clss = results[0].boxes.cls.cpu().tolist()
|
||||
annotator = Annotator(im0, line_width=2, example=names)
|
||||
|
||||
if boxes is not None:
|
||||
for box, cls in zip(boxes, clss):
|
||||
annotator.box_label(box, color=colors(int(cls), True), label=names[int(cls)])
|
||||
|
||||
obj = im0[int(box[1]):int(box[3]), int(box[0]):int(box[2])]
|
||||
blur_obj = cv2.blur(obj, (blur_ratio, blur_ratio))
|
||||
|
||||
im0[int(box[1]):int(box[3]), int(box[0]):int(box[2])] = blur_obj
|
||||
|
||||
cv2.imshow("ultralytics", im0)
|
||||
video_writer.write(im0)
|
||||
if cv2.waitKey(1) & 0xFF == ord('q'):
|
||||
break
|
||||
|
||||
cap.release()
|
||||
video_writer.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
### Arguments `model.predict`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------------|----------------|------------------------|----------------------------------------------------------------------------|
|
||||
| `source` | `str` | `'ultralytics/assets'` | source directory for images or videos |
|
||||
| `conf` | `float` | `0.25` | object confidence threshold for detection |
|
||||
| `iou` | `float` | `0.7` | intersection over union (IoU) threshold for NMS |
|
||||
| `imgsz` | `int or tuple` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
|
||||
| `half` | `bool` | `False` | use half precision (FP16) |
|
||||
| `device` | `None or str` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |
|
||||
| `max_det` | `int` | `300` | maximum number of detections per image |
|
||||
| `vid_stride` | `bool` | `False` | video frame-rate stride |
|
||||
| `stream_buffer` | `bool` | `False` | buffer all streaming frames (True) or return the most recent frame (False) |
|
||||
| `visualize` | `bool` | `False` | visualize model features |
|
||||
| `augment` | `bool` | `False` | apply image augmentation to prediction sources |
|
||||
| `agnostic_nms` | `bool` | `False` | class-agnostic NMS |
|
||||
| `classes` | `list[int]` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] |
|
||||
| `retina_masks` | `bool` | `False` | use high-resolution segmentation masks |
|
||||
| `embed` | `list[int]` | `None` | return feature vectors/embeddings from given layers |
|
||||
246
docs/en/guides/object-counting.md
Normal file
246
docs/en/guides/object-counting.md
Normal file
@ -0,0 +1,246 @@
|
||||
---
|
||||
comments: true
|
||||
description: Object Counting Using Ultralytics YOLOv8
|
||||
keywords: Ultralytics, YOLOv8, Object Detection, Object Counting, Object Tracking, Notebook, IPython Kernel, CLI, Python SDK
|
||||
---
|
||||
|
||||
# Object Counting using Ultralytics YOLOv8 🚀
|
||||
|
||||
## What is Object Counting?
|
||||
|
||||
Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves accurate identification and counting of specific objects in videos and camera streams. YOLOv8 excels in real-time applications, providing efficient and precise object counting for various scenarios like crowd analysis and surveillance, thanks to its state-of-the-art algorithms and deep learning capabilities.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/Ag2e-5_NpS0"
|
||||
title="YouTube video player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Watch:</strong> Object Counting using Ultralytics YOLOv8
|
||||
</p>
|
||||
|
||||
## Advantages of Object Counting?
|
||||
|
||||
- **Resource Optimization:** Object counting facilitates efficient resource management by providing accurate counts, and optimizing resource allocation in applications like inventory management.
|
||||
- **Enhanced Security:** Object counting enhances security and surveillance by accurately tracking and counting entities, aiding in proactive threat detection.
|
||||
- **Informed Decision-Making:** Object counting offers valuable insights for decision-making, optimizing processes in retail, traffic management, and various other domains.
|
||||
|
||||
## Real World Applications
|
||||
|
||||
| Logistics | Aquaculture |
|
||||
|:-------------------------------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
|  |  |
|
||||
| Conveyor Belt Packets Counting Using Ultralytics YOLOv8 | Fish Counting in Sea using Ultralytics YOLOv8 |
|
||||
|
||||
!!! Example "Object Counting using YOLOv8 Example"
|
||||
|
||||
=== "Count in Region"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.solutions import object_counter
|
||||
import cv2
|
||||
|
||||
model = YOLO("yolov8n.pt")
|
||||
cap = cv2.VideoCapture("path/to/video/file.mp4")
|
||||
assert cap.isOpened(), "Error reading video file"
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
# Define region points
|
||||
region_points = [(20, 400), (1080, 404), (1080, 360), (20, 360)]
|
||||
|
||||
# Video writer
|
||||
video_writer = cv2.VideoWriter("object_counting_output.avi",
|
||||
cv2.VideoWriter_fourcc(*'mp4v'),
|
||||
fps,
|
||||
(w, h))
|
||||
|
||||
# Init Object Counter
|
||||
counter = object_counter.ObjectCounter()
|
||||
counter.set_args(view_img=True,
|
||||
reg_pts=region_points,
|
||||
classes_names=model.names,
|
||||
draw_tracks=True)
|
||||
|
||||
while cap.isOpened():
|
||||
success, im0 = cap.read()
|
||||
if not success:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
tracks = model.track(im0, persist=True, show=False)
|
||||
|
||||
im0 = counter.start_counting(im0, tracks)
|
||||
video_writer.write(im0)
|
||||
|
||||
cap.release()
|
||||
video_writer.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
=== "Count in Polygon"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.solutions import object_counter
|
||||
import cv2
|
||||
|
||||
model = YOLO("yolov8n.pt")
|
||||
cap = cv2.VideoCapture("path/to/video/file.mp4")
|
||||
assert cap.isOpened(), "Error reading video file"
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
# Define region points as a polygon with 5 points
|
||||
region_points = [(20, 400), (1080, 404), (1080, 360), (20, 360), (20, 400)]
|
||||
|
||||
# Video writer
|
||||
video_writer = cv2.VideoWriter("object_counting_output.avi",
|
||||
cv2.VideoWriter_fourcc(*'mp4v'),
|
||||
fps,
|
||||
(w, h))
|
||||
|
||||
# Init Object Counter
|
||||
counter = object_counter.ObjectCounter()
|
||||
counter.set_args(view_img=True,
|
||||
reg_pts=region_points,
|
||||
classes_names=model.names,
|
||||
draw_tracks=True)
|
||||
|
||||
while cap.isOpened():
|
||||
success, im0 = cap.read()
|
||||
if not success:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
tracks = model.track(im0, persist=True, show=False)
|
||||
|
||||
im0 = counter.start_counting(im0, tracks)
|
||||
video_writer.write(im0)
|
||||
|
||||
cap.release()
|
||||
video_writer.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
=== "Count in Line"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.solutions import object_counter
|
||||
import cv2
|
||||
|
||||
model = YOLO("yolov8n.pt")
|
||||
cap = cv2.VideoCapture("path/to/video/file.mp4")
|
||||
assert cap.isOpened(), "Error reading video file"
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
# Define line points
|
||||
line_points = [(20, 400), (1080, 400)]
|
||||
|
||||
# Video writer
|
||||
video_writer = cv2.VideoWriter("object_counting_output.avi",
|
||||
cv2.VideoWriter_fourcc(*'mp4v'),
|
||||
fps,
|
||||
(w, h))
|
||||
|
||||
# Init Object Counter
|
||||
counter = object_counter.ObjectCounter()
|
||||
counter.set_args(view_img=True,
|
||||
reg_pts=line_points,
|
||||
classes_names=model.names,
|
||||
draw_tracks=True)
|
||||
|
||||
while cap.isOpened():
|
||||
success, im0 = cap.read()
|
||||
if not success:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
tracks = model.track(im0, persist=True, show=False)
|
||||
|
||||
im0 = counter.start_counting(im0, tracks)
|
||||
video_writer.write(im0)
|
||||
|
||||
cap.release()
|
||||
video_writer.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
=== "Specific Classes"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.solutions import object_counter
|
||||
import cv2
|
||||
|
||||
model = YOLO("yolov8n.pt")
|
||||
cap = cv2.VideoCapture("path/to/video/file.mp4")
|
||||
assert cap.isOpened(), "Error reading video file"
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
line_points = [(20, 400), (1080, 400)] # line or region points
|
||||
classes_to_count = [0, 2] # person and car classes for count
|
||||
|
||||
# Video writer
|
||||
video_writer = cv2.VideoWriter("object_counting_output.avi",
|
||||
cv2.VideoWriter_fourcc(*'mp4v'),
|
||||
fps,
|
||||
(w, h))
|
||||
|
||||
# Init Object Counter
|
||||
counter = object_counter.ObjectCounter()
|
||||
counter.set_args(view_img=True,
|
||||
reg_pts=line_points,
|
||||
classes_names=model.names,
|
||||
draw_tracks=True)
|
||||
|
||||
while cap.isOpened():
|
||||
success, im0 = cap.read()
|
||||
if not success:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
tracks = model.track(im0, persist=True, show=False,
|
||||
classes=classes_to_count)
|
||||
|
||||
im0 = counter.start_counting(im0, tracks)
|
||||
video_writer.write(im0)
|
||||
|
||||
cap.release()
|
||||
video_writer.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
???+ tip "Region is Movable"
|
||||
|
||||
You can move the region anywhere in the frame by clicking on its edges
|
||||
|
||||
### Optional Arguments `set_args`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------------------|-------------|----------------------------|-----------------------------------------------|
|
||||
| `view_img` | `bool` | `False` | Display frames with counts |
|
||||
| `view_in_counts` | `bool` | `True` | Display in-counts only on video frame |
|
||||
| `view_out_counts` | `bool` | `True` | Display out-counts only on video frame |
|
||||
| `line_thickness` | `int` | `2` | Increase bounding boxes thickness |
|
||||
| `reg_pts` | `list` | `[(20, 400), (1260, 400)]` | Points defining the Region Area |
|
||||
| `classes_names` | `dict` | `model.model.names` | Dictionary of Class Names |
|
||||
| `region_color` | `RGB Color` | `(255, 0, 255)` | Color of the Object counting Region or Line |
|
||||
| `track_thickness` | `int` | `2` | Thickness of Tracking Lines |
|
||||
| `draw_tracks` | `bool` | `False` | Enable drawing Track lines |
|
||||
| `track_color` | `RGB Color` | `(0, 255, 0)` | Color for each track line |
|
||||
| `line_dist_thresh` | `int` | `15` | Euclidean Distance threshold for line counter |
|
||||
| `count_txt_thickness` | `int` | `2` | Thickness of Object counts text |
|
||||
| `count_txt_color` | `RGB Color` | `(0, 0, 0)` | Foreground color for Object counts text |
|
||||
| `count_color` | `RGB Color` | `(255, 255, 255)` | Background color for Object counts text |
|
||||
| `region_thickness` | `int` | `5` | Thickness for object counter region or line |
|
||||
|
||||
### Arguments `model.track`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------|---------|----------------|-------------------------------------------------------------|
|
||||
| `source` | `im0` | `None` | source directory for images or videos |
|
||||
| `persist` | `bool` | `False` | persisting tracks between frames |
|
||||
| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
|
||||
| `conf` | `float` | `0.3` | Confidence Threshold |
|
||||
| `iou` | `float` | `0.5` | IOU Threshold |
|
||||
| `classes` | `list` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] |
|
||||
| `verbose` | `bool` | `True` | Display the object tracking results |
|
||||
102
docs/en/guides/object-cropping.md
Normal file
102
docs/en/guides/object-cropping.md
Normal file
@ -0,0 +1,102 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to isolate and extract specific objects from images and videos using YOLOv8 object cropping.
|
||||
keywords: Ultralytics, YOLOv8, Object Detection, Object Cropping, Image Analysis, Video Processing, Data Extraction, Python
|
||||
---
|
||||
|
||||
# Object Cropping using Ultralytics YOLOv8 🚀
|
||||
|
||||
## What is Object Cropping?
|
||||
|
||||
Object cropping with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves isolating and extracting specific detected objects from an image or video. The YOLOv8 model capabilities are utilized to accurately identify and delineate objects, enabling precise cropping for further analysis or manipulation.
|
||||
|
||||
## Advantages of Object Cropping?
|
||||
|
||||
- **Focused Analysis**: YOLOv8 facilitates targeted object cropping, allowing for in-depth examination or processing of individual items within a scene.
|
||||
- **Reduced Data Volume**: By extracting only relevant objects, object cropping helps in minimizing data size, making it efficient for storage, transmission, or subsequent computational tasks.
|
||||
- **Enhanced Precision**: YOLOv8's object detection accuracy ensures that the cropped objects maintain their spatial relationships, preserving the integrity of the visual information for detailed analysis.
|
||||
|
||||
## Visuals
|
||||
|
||||
| Airport Luggage |
|
||||
|:----------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
|  |
|
||||
| Suitcases Cropping at airport conveyor belt using Ultralytics YOLOv8 |
|
||||
|
||||
!!! Example "Object Cropping using YOLOv8 Example"
|
||||
|
||||
=== "Object Cropping"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.utils.plotting import Annotator, colors
|
||||
import cv2
|
||||
import os
|
||||
|
||||
model = YOLO("yolov8n.pt")
|
||||
names = model.names
|
||||
|
||||
cap = cv2.VideoCapture("path/to/video/file.mp4")
|
||||
assert cap.isOpened(), "Error reading video file"
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
crop_dir_name = "ultralytics_crop"
|
||||
if not os.path.exists(crop_dir_name):
|
||||
os.mkdir(crop_dir_name)
|
||||
|
||||
# Video writer
|
||||
video_writer = cv2.VideoWriter("object_cropping_output.avi",
|
||||
cv2.VideoWriter_fourcc(*'mp4v'),
|
||||
fps, (w, h))
|
||||
|
||||
idx = 0
|
||||
while cap.isOpened():
|
||||
success, im0 = cap.read()
|
||||
if not success:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
|
||||
results = model.predict(im0, show=False)
|
||||
boxes = results[0].boxes.xyxy.cpu().tolist()
|
||||
clss = results[0].boxes.cls.cpu().tolist()
|
||||
annotator = Annotator(im0, line_width=2, example=names)
|
||||
|
||||
if boxes is not None:
|
||||
for box, cls in zip(boxes, clss):
|
||||
idx += 1
|
||||
annotator.box_label(box, color=colors(int(cls), True), label=names[int(cls)])
|
||||
|
||||
crop_obj = im0[int(box[1]):int(box[3]), int(box[0]):int(box[2])]
|
||||
|
||||
cv2.imwrite(os.path.join(crop_dir_name, str(idx)+".png"), crop_obj)
|
||||
|
||||
cv2.imshow("ultralytics", im0)
|
||||
video_writer.write(im0)
|
||||
|
||||
if cv2.waitKey(1) & 0xFF == ord('q'):
|
||||
break
|
||||
|
||||
cap.release()
|
||||
video_writer.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
### Arguments `model.predict`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------------|----------------|------------------------|----------------------------------------------------------------------------|
|
||||
| `source` | `str` | `'ultralytics/assets'` | source directory for images or videos |
|
||||
| `conf` | `float` | `0.25` | object confidence threshold for detection |
|
||||
| `iou` | `float` | `0.7` | intersection over union (IoU) threshold for NMS |
|
||||
| `imgsz` | `int or tuple` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
|
||||
| `half` | `bool` | `False` | use half precision (FP16) |
|
||||
| `device` | `None or str` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |
|
||||
| `max_det` | `int` | `300` | maximum number of detections per image |
|
||||
| `vid_stride` | `bool` | `False` | video frame-rate stride |
|
||||
| `stream_buffer` | `bool` | `False` | buffer all streaming frames (True) or return the most recent frame (False) |
|
||||
| `visualize` | `bool` | `False` | visualize model features |
|
||||
| `augment` | `bool` | `False` | apply image augmentation to prediction sources |
|
||||
| `agnostic_nms` | `bool` | `False` | class-agnostic NMS |
|
||||
| `classes` | `list[int]` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] |
|
||||
| `retina_masks` | `bool` | `False` | use high-resolution segmentation masks |
|
||||
| `embed` | `list[int]` | `None` | return feature vectors/embeddings from given layers |
|
||||
@ -0,0 +1,69 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to optimize Ultralytics YOLOv8 models with Intel OpenVINO for maximum performance. Discover expert techniques to minimize latency and maximize throughput for real-time object detection applications.
|
||||
keywords: Ultralytics, YOLOv8, OpenVINO, optimization, latency, throughput, inference, object detection, deep learning, machine learning, guide, Intel
|
||||
---
|
||||
|
||||
# Optimizing OpenVINO Inference for Ultralytics YOLO Models: A Comprehensive Guide
|
||||
|
||||
<img width="1024" src="https://github.com/RizwanMunawar/RizwanMunawar/assets/62513924/2b181f68-aa91-4514-ba09-497cc3c83b00" alt="OpenVINO Ecosystem">
|
||||
|
||||
## Introduction
|
||||
|
||||
When deploying deep learning models, particularly those for object detection such as Ultralytics YOLO models, achieving optimal performance is crucial. This guide delves into leveraging Intel's OpenVINO toolkit to optimize inference, focusing on latency and throughput. Whether you're working on consumer-grade applications or large-scale deployments, understanding and applying these optimization strategies will ensure your models run efficiently on various devices.
|
||||
|
||||
## Optimizing for Latency
|
||||
|
||||
Latency optimization is vital for applications requiring immediate response from a single model given a single input, typical in consumer scenarios. The goal is to minimize the delay between input and inference result. However, achieving low latency involves careful consideration, especially when running concurrent inferences or managing multiple models.
|
||||
|
||||
### Key Strategies for Latency Optimization:
|
||||
|
||||
- **Single Inference per Device:** The simplest way to achieve low latency is by limiting to one inference at a time per device. Additional concurrency often leads to increased latency.
|
||||
- **Leveraging Sub-Devices:** Devices like multi-socket CPUs or multi-tile GPUs can execute multiple requests with minimal latency increase by utilizing their internal sub-devices.
|
||||
- **OpenVINO Performance Hints:** Utilizing OpenVINO's `ov::hint::PerformanceMode::LATENCY` for the `ov::hint::performance_mode` property during model compilation simplifies performance tuning, offering a device-agnostic and future-proof approach.
|
||||
|
||||
### Managing First-Inference Latency:
|
||||
|
||||
- **Model Caching:** To mitigate model load and compile times impacting latency, use model caching where possible. For scenarios where caching isn't viable, CPUs generally offer the fastest model load times.
|
||||
- **Model Mapping vs. Reading:** To reduce load times, OpenVINO replaced model reading with mapping. However, if the model is on a removable or network drive, consider using `ov::enable_mmap(false)` to switch back to reading.
|
||||
- **AUTO Device Selection:** This mode begins inference on the CPU, shifting to an accelerator once ready, seamlessly reducing first-inference latency.
|
||||
|
||||
## Optimizing for Throughput
|
||||
|
||||
Throughput optimization is crucial for scenarios serving numerous inference requests simultaneously, maximizing resource utilization without significantly sacrificing individual request performance.
|
||||
|
||||
### Approaches to Throughput Optimization:
|
||||
|
||||
1. **OpenVINO Performance Hints:** A high-level, future-proof method to enhance throughput across devices using performance hints.
|
||||
|
||||
```python
|
||||
import openvino.properties as props
|
||||
import openvino.properties.hint as hints
|
||||
|
||||
config = {hints.performance_mode: hints.PerformanceMode.THROUGHPUT}
|
||||
compiled_model = core.compile_model(model, "GPU", config)
|
||||
```
|
||||
|
||||
2. **Explicit Batching and Streams:** A more granular approach involving explicit batching and the use of streams for advanced performance tuning.
|
||||
|
||||
### Designing Throughput-Oriented Applications:
|
||||
|
||||
To maximize throughput, applications should:
|
||||
|
||||
- Process inputs in parallel, making full use of the device's capabilities.
|
||||
- Decompose data flow into concurrent inference requests, scheduled for parallel execution.
|
||||
- Utilize the Async API with callbacks to maintain efficiency and avoid device starvation.
|
||||
|
||||
### Multi-Device Execution:
|
||||
|
||||
OpenVINO's multi-device mode simplifies scaling throughput by automatically balancing inference requests across devices without requiring application-level device management.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Optimizing Ultralytics YOLO models for latency and throughput with OpenVINO can significantly enhance your application's performance. By carefully applying the strategies outlined in this guide, developers can ensure their models run efficiently, meeting the demands of various deployment scenarios. Remember, the choice between optimizing for latency or throughput depends on your specific application needs and the characteristics of the deployment environment.
|
||||
|
||||
For more detailed technical information and the latest updates, refer to the [OpenVINO documentation](https://docs.openvino.ai/latest/index.html) and [Ultralytics YOLO repository](https://github.com/ultralytics/ultralytics). These resources provide in-depth guides, tutorials, and community support to help you get the most out of your deep learning models.
|
||||
|
||||
---
|
||||
|
||||
Ensuring your models achieve optimal performance is not just about tweaking configurations; it's about understanding your application's needs and making informed decisions. Whether you're optimizing for real-time responses or maximizing throughput for large-scale processing, the combination of Ultralytics YOLO models and OpenVINO offers a powerful toolkit for developers to deploy high-performance AI solutions.
|
||||
196
docs/en/guides/raspberry-pi.md
Normal file
196
docs/en/guides/raspberry-pi.md
Normal file
@ -0,0 +1,196 @@
|
||||
---
|
||||
comments: true
|
||||
description: Quick start guide to setting up YOLO on a Raspberry Pi with a Pi Camera using the libcamera stack. Detailed comparison between Raspberry Pi 3, 4 and 5 models.
|
||||
keywords: Ultralytics, YOLO, Raspberry Pi, Pi Camera, libcamera, quick start guide, Raspberry Pi 4 vs Raspberry Pi 5, YOLO on Raspberry Pi, hardware setup, machine learning, AI
|
||||
---
|
||||
|
||||
# Quick Start Guide: Raspberry Pi and Pi Camera with YOLOv5 and YOLOv8
|
||||
|
||||
This comprehensive guide aims to expedite your journey with YOLO object detection models on a [Raspberry Pi](https://www.raspberrypi.com/) using a [Pi Camera](https://www.raspberrypi.com/products/camera-module-v2/). Whether you're a student, hobbyist, or a professional, this guide is designed to get you up and running in less than 30 minutes. The instructions here are rigorously tested to minimize setup issues, allowing you to focus on utilizing YOLO for your specific projects.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/yul4gq_LrOI"
|
||||
title="Introducing Raspberry Pi 5" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Watch:</strong> Raspberry Pi 5 updates and improvements.
|
||||
</p>
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- Raspberry Pi 3, 4 or 5
|
||||
- Pi Camera
|
||||
- 64-bit Raspberry Pi Operating System
|
||||
|
||||
Connect the Pi Camera to your Raspberry Pi via a CSI cable and install the 64-bit Raspberry Pi Operating System. Verify your camera with the following command:
|
||||
|
||||
```bash
|
||||
libcamera-hello
|
||||
```
|
||||
|
||||
You should see a video feed from your camera.
|
||||
|
||||
## Choose Your YOLO Version: YOLOv5 or YOLOv8
|
||||
|
||||
This guide offers you the flexibility to start with either [YOLOv5](https://github.com/ultralytics/yolov5) or [YOLOv8](https://github.com/ultralytics/ultralytics). Both versions have their unique advantages and use-cases. The choice is yours, but remember, the guide's aim is not just quick setup but also a robust foundation for your future work in object detection.
|
||||
|
||||
## Hardware Specifics: At a Glance
|
||||
|
||||
To assist you in making an informed hardware decision, we've summarized the key hardware specifics of Raspberry Pi 3, 4, and 5 in the table below:
|
||||
|
||||
| Feature | Raspberry Pi 3 | Raspberry Pi 4 | Raspberry Pi 5 |
|
||||
|----------------------------|------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------|----------------------------------------------------------------------|
|
||||
| **CPU** | 1.2GHz Quad-Core ARM Cortex-A53 | 1.5GHz Quad-core 64-bit ARM Cortex-A72 | 2.4GHz Quad-core 64-bit Arm Cortex-A76 |
|
||||
| **RAM** | 1GB LPDDR2 | 2GB, 4GB or 8GB LPDDR4 | *Details not yet available* |
|
||||
| **USB Ports** | 4 x USB 2.0 | 2 x USB 2.0, 2 x USB 3.0 | 2 x USB 3.0, 2 x USB 2.0 |
|
||||
| **Network** | Ethernet & Wi-Fi 802.11n | Gigabit Ethernet & Wi-Fi 802.11ac | Gigabit Ethernet with PoE+ support, Dual-band 802.11ac Wi-Fi® |
|
||||
| **Performance** | Slower, may require lighter YOLO models | Faster, can run complex YOLO models | *Details not yet available* |
|
||||
| **Power Requirement** | 2.5A power supply | 3.0A USB-C power supply | *Details not yet available* |
|
||||
| **Official Documentation** | [Link](https://www.raspberrypi.org/documentation/hardware/raspberrypi/bcm2837/README.md) | [Link](https://www.raspberrypi.org/documentation/hardware/raspberrypi/bcm2711/README.md) | [Link](https://www.raspberrypi.com/news/introducing-raspberry-pi-5/) |
|
||||
|
||||
Please make sure to follow the instructions specific to your Raspberry Pi model to ensure a smooth setup process.
|
||||
|
||||
## Quick Start with YOLOv5
|
||||
|
||||
This section outlines how to set up YOLOv5 on a Raspberry Pi with a Pi Camera. These steps are designed to be compatible with the libcamera camera stack introduced in Raspberry Pi OS Bullseye.
|
||||
|
||||
### Install Necessary Packages
|
||||
|
||||
1. Update the Raspberry Pi:
|
||||
|
||||
```bash
|
||||
sudo apt-get update
|
||||
sudo apt-get upgrade -y
|
||||
sudo apt-get autoremove -y
|
||||
```
|
||||
|
||||
2. Clone the YOLOv5 repository:
|
||||
|
||||
```bash
|
||||
cd ~
|
||||
git clone https://github.com/Ultralytics/yolov5.git
|
||||
```
|
||||
|
||||
3. Install the required dependencies:
|
||||
|
||||
```bash
|
||||
cd ~/yolov5
|
||||
pip3 install -r requirements.txt
|
||||
```
|
||||
|
||||
4. For Raspberry Pi 3, install compatible versions of PyTorch and Torchvision (skip for Raspberry Pi 4):
|
||||
|
||||
```bash
|
||||
pip3 uninstall torch torchvision
|
||||
pip3 install torch==1.11.0 torchvision==0.12.0
|
||||
```
|
||||
|
||||
### Modify `detect.py`
|
||||
|
||||
To enable TCP streams via SSH or the CLI, minor modifications are needed in `detect.py`.
|
||||
|
||||
1. Open `detect.py`:
|
||||
|
||||
```bash
|
||||
sudo nano ~/yolov5/detect.py
|
||||
```
|
||||
|
||||
2. Find and modify the `is_url` line to accept TCP streams:
|
||||
|
||||
```python
|
||||
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://', 'tcp://'))
|
||||
```
|
||||
|
||||
3. Comment out the `view_img` line:
|
||||
|
||||
```python
|
||||
# view_img = check_imshow(warn=True)
|
||||
```
|
||||
|
||||
4. Save and exit:
|
||||
|
||||
```bash
|
||||
CTRL + O -> ENTER -> CTRL + X
|
||||
```
|
||||
|
||||
### Initiate TCP Stream with Libcamera
|
||||
|
||||
1. Start the TCP stream:
|
||||
|
||||
```bash
|
||||
libcamera-vid -n -t 0 --width 1280 --height 960 --framerate 1 --inline --listen -o tcp://127.0.0.1:8888
|
||||
```
|
||||
|
||||
Keep this terminal session running for the next steps.
|
||||
|
||||
### Perform YOLOv5 Inference
|
||||
|
||||
1. Run the YOLOv5 detection:
|
||||
|
||||
```bash
|
||||
cd ~/yolov5
|
||||
python3 detect.py --source=tcp://127.0.0.1:8888
|
||||
```
|
||||
|
||||
## Quick Start with YOLOv8
|
||||
|
||||
Follow this section if you are interested in setting up YOLOv8 instead. The steps are quite similar but are tailored for YOLOv8's specific needs.
|
||||
|
||||
### Install Necessary Packages
|
||||
|
||||
1. Update the Raspberry Pi:
|
||||
|
||||
```bash
|
||||
sudo apt-get update
|
||||
sudo apt-get upgrade -y
|
||||
sudo apt-get autoremove -y
|
||||
```
|
||||
|
||||
2. Install the `ultralytics` Python package:
|
||||
|
||||
```bash
|
||||
pip3 install ultralytics
|
||||
```
|
||||
|
||||
3. Reboot:
|
||||
|
||||
```bash
|
||||
sudo reboot
|
||||
```
|
||||
|
||||
### Initiate TCP Stream with Libcamera
|
||||
|
||||
1. Start the TCP stream:
|
||||
|
||||
```bash
|
||||
libcamera-vid -n -t 0 --width 1280 --height 960 --framerate 1 --inline --listen -o tcp://127.0.0.1:8888
|
||||
```
|
||||
|
||||
### Perform YOLOv8 Inference
|
||||
|
||||
To perform inference with YOLOv8, you can use the following Python code snippet:
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
model = YOLO('yolov8n.pt')
|
||||
results = model('tcp://127.0.0.1:8888', stream=True)
|
||||
|
||||
while True:
|
||||
for result in results:
|
||||
boxes = result.boxes
|
||||
probs = result.probs
|
||||
```
|
||||
|
||||
## Next Steps
|
||||
|
||||
Congratulations on successfully setting up YOLO on your Raspberry Pi! For further learning and support, visit [Ultralytics](https://ultralytics.com/) and [Kashmir World Foundation](https://www.kashmirworldfoundation.org/).
|
||||
|
||||
## Acknowledgements and Citations
|
||||
|
||||
This guide was initially created by Daan Eeltink for Kashmir World Foundation, an organization dedicated to the use of YOLO for the conservation of endangered species. We acknowledge their pioneering work and educational focus in the realm of object detection technologies.
|
||||
|
||||
For more information about Kashmir World Foundation's activities, you can visit their [website](https://www.kashmirworldfoundation.org/).
|
||||
86
docs/en/guides/region-counting.md
Normal file
86
docs/en/guides/region-counting.md
Normal file
@ -0,0 +1,86 @@
|
||||
---
|
||||
comments: true
|
||||
description: Object Counting in Different Region using Ultralytics YOLOv8
|
||||
keywords: Ultralytics, YOLOv8, Object Detection, Object Counting, Object Tracking, Notebook, IPython Kernel, CLI, Python SDK
|
||||
---
|
||||
|
||||
# Object Counting in Different Regions using Ultralytics YOLOv8 🚀
|
||||
|
||||
## What is Object Counting in Regions?
|
||||
|
||||
[Object counting](https://docs.ultralytics.com/guides/object-counting/) in regions with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves precisely determining the number of objects within specified areas using advanced computer vision. This approach is valuable for optimizing processes, enhancing security, and improving efficiency in various applications.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/okItf1iHlV8"
|
||||
title="YouTube video player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Watch:</strong> Ultralytics YOLOv8 Object Counting in Multiple & Movable Regions
|
||||
</p>
|
||||
|
||||
## Advantages of Object Counting in Regions?
|
||||
|
||||
- **Precision and Accuracy:** Object counting in regions with advanced computer vision ensures precise and accurate counts, minimizing errors often associated with manual counting.
|
||||
- **Efficiency Improvement:** Automated object counting enhances operational efficiency, providing real-time results and streamlining processes across different applications.
|
||||
- **Versatility and Application:** The versatility of object counting in regions makes it applicable across various domains, from manufacturing and surveillance to traffic monitoring, contributing to its widespread utility and effectiveness.
|
||||
|
||||
## Real World Applications
|
||||
|
||||
| Retail | Market Streets |
|
||||
|:------------------------------------------------------------------------------------------------------------------------------------------------------------------:|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
|  |  |
|
||||
| People Counting in Different Region using Ultralytics YOLOv8 | Crowd Counting in Different Region using Ultralytics YOLOv8 |
|
||||
|
||||
## Steps to Run
|
||||
|
||||
### Step 1: Install Required Libraries
|
||||
|
||||
Begin by cloning the Ultralytics repository, installing dependencies, and navigating to the local directory using the provided commands in Step 2.
|
||||
|
||||
```bash
|
||||
# Clone Ultralytics repo
|
||||
git clone https://github.com/ultralytics/ultralytics
|
||||
|
||||
# Navigate to the local directory
|
||||
cd ultralytics/examples/YOLOv8-Region-Counter
|
||||
```
|
||||
|
||||
### Step 2: Run Region Counting Using Ultralytics YOLOv8
|
||||
|
||||
Execute the following basic commands for inference.
|
||||
|
||||
???+ tip "Region is Movable"
|
||||
|
||||
During video playback, you can interactively move the region within the video by clicking and dragging using the left mouse button.
|
||||
|
||||
```bash
|
||||
# Save results
|
||||
python yolov8_region_counter.py --source "path/to/video.mp4" --save-img
|
||||
|
||||
# Run model on CPU
|
||||
python yolov8_region_counter.py --source "path/to/video.mp4" --device cpu
|
||||
|
||||
# Change model file
|
||||
python yolov8_region_counter.py --source "path/to/video.mp4" --weights "path/to/model.pt"
|
||||
|
||||
# Detect specific classes (e.g., first and third classes)
|
||||
python yolov8_region_counter.py --source "path/to/video.mp4" --classes 0 2
|
||||
|
||||
# View results without saving
|
||||
python yolov8_region_counter.py --source "path/to/video.mp4" --view-img
|
||||
```
|
||||
|
||||
### Optional Arguments
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|----------------------|--------|--------------|--------------------------------------------|
|
||||
| `--source` | `str` | `None` | Path to video file, for webcam 0 |
|
||||
| `--line_thickness` | `int` | `2` | Bounding Box thickness |
|
||||
| `--save-img` | `bool` | `False` | Save the predicted video/image |
|
||||
| `--weights` | `str` | `yolov8n.pt` | Weights file path |
|
||||
| `--classes` | `list` | `None` | Detect specific classes i.e. --classes 0 2 |
|
||||
| `--region-thickness` | `int` | `2` | Region Box thickness |
|
||||
| `--track-thickness` | `int` | `2` | Tracking line thickness |
|
||||
185
docs/en/guides/sahi-tiled-inference.md
Normal file
185
docs/en/guides/sahi-tiled-inference.md
Normal file
@ -0,0 +1,185 @@
|
||||
---
|
||||
comments: true
|
||||
description: A comprehensive guide on how to use YOLOv8 with SAHI for standard and sliced inference in object detection tasks.
|
||||
keywords: YOLOv8, SAHI, Sliced Inference, Object Detection, Ultralytics, Large Scale Image Analysis, High-Resolution Imagery
|
||||
---
|
||||
|
||||
# Ultralytics Docs: Using YOLOv8 with SAHI for Sliced Inference
|
||||
|
||||
Welcome to the Ultralytics documentation on how to use YOLOv8 with [SAHI](https://github.com/obss/sahi) (Slicing Aided Hyper Inference). This comprehensive guide aims to furnish you with all the essential knowledge you'll need to implement SAHI alongside YOLOv8. We'll deep-dive into what SAHI is, why sliced inference is critical for large-scale applications, and how to integrate these functionalities with YOLOv8 for enhanced object detection performance.
|
||||
|
||||
<p align="center">
|
||||
<img width="1024" src="https://raw.githubusercontent.com/obss/sahi/main/resources/sliced_inference.gif" alt="SAHI Sliced Inference Overview">
|
||||
</p>
|
||||
|
||||
## Introduction to SAHI
|
||||
|
||||
SAHI (Slicing Aided Hyper Inference) is an innovative library designed to optimize object detection algorithms for large-scale and high-resolution imagery. Its core functionality lies in partitioning images into manageable slices, running object detection on each slice, and then stitching the results back together. SAHI is compatible with a range of object detection models, including the YOLO series, thereby offering flexibility while ensuring optimized use of computational resources.
|
||||
|
||||
### Key Features of SAHI
|
||||
|
||||
- **Seamless Integration**: SAHI integrates effortlessly with YOLO models, meaning you can start slicing and detecting without a lot of code modification.
|
||||
- **Resource Efficiency**: By breaking down large images into smaller parts, SAHI optimizes the memory usage, allowing you to run high-quality detection on hardware with limited resources.
|
||||
- **High Accuracy**: SAHI maintains the detection accuracy by employing smart algorithms to merge overlapping detection boxes during the stitching process.
|
||||
|
||||
## What is Sliced Inference?
|
||||
|
||||
Sliced Inference refers to the practice of subdividing a large or high-resolution image into smaller segments (slices), conducting object detection on these slices, and then recompiling the slices to reconstruct the object locations on the original image. This technique is invaluable in scenarios where computational resources are limited or when working with extremely high-resolution images that could otherwise lead to memory issues.
|
||||
|
||||
### Benefits of Sliced Inference
|
||||
|
||||
- **Reduced Computational Burden**: Smaller image slices are faster to process, and they consume less memory, enabling smoother operation on lower-end hardware.
|
||||
|
||||
- **Preserved Detection Quality**: Since each slice is treated independently, there is no reduction in the quality of object detection, provided the slices are large enough to capture the objects of interest.
|
||||
|
||||
- **Enhanced Scalability**: The technique allows for object detection to be more easily scaled across different sizes and resolutions of images, making it ideal for a wide range of applications from satellite imagery to medical diagnostics.
|
||||
|
||||
<table border="0">
|
||||
<tr>
|
||||
<th>YOLOv8 without SAHI</th>
|
||||
<th>YOLOv8 with SAHI</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><img src="https://user-images.githubusercontent.com/26833433/266123241-260a9740-5998-4e9a-ad04-b39b7767e731.png" alt="YOLOv8 without SAHI" width="640"></td>
|
||||
<td><img src="https://user-images.githubusercontent.com/26833433/266123245-55f696ad-ec74-4e71-9155-c211d693bb69.png" alt="YOLOv8 with SAHI" width="640"></td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
## Installation and Preparation
|
||||
|
||||
### Installation
|
||||
|
||||
To get started, install the latest versions of SAHI and Ultralytics:
|
||||
|
||||
```bash
|
||||
pip install -U ultralytics sahi
|
||||
```
|
||||
|
||||
### Import Modules and Download Resources
|
||||
|
||||
Here's how to import the necessary modules and download a YOLOv8 model and some test images:
|
||||
|
||||
```python
|
||||
from sahi.utils.yolov8 import download_yolov8s_model
|
||||
from sahi import AutoDetectionModel
|
||||
from sahi.utils.cv import read_image
|
||||
from sahi.utils.file import download_from_url
|
||||
from sahi.predict import get_prediction, get_sliced_prediction, predict
|
||||
from pathlib import Path
|
||||
from IPython.display import Image
|
||||
|
||||
# Download YOLOv8 model
|
||||
yolov8_model_path = "models/yolov8s.pt"
|
||||
download_yolov8s_model(yolov8_model_path)
|
||||
|
||||
# Download test images
|
||||
download_from_url('https://raw.githubusercontent.com/obss/sahi/main/demo/demo_data/small-vehicles1.jpeg', 'demo_data/small-vehicles1.jpeg')
|
||||
download_from_url('https://raw.githubusercontent.com/obss/sahi/main/demo/demo_data/terrain2.png', 'demo_data/terrain2.png')
|
||||
```
|
||||
|
||||
## Standard Inference with YOLOv8
|
||||
|
||||
### Instantiate the Model
|
||||
|
||||
You can instantiate a YOLOv8 model for object detection like this:
|
||||
|
||||
```python
|
||||
detection_model = AutoDetectionModel.from_pretrained(
|
||||
model_type='yolov8',
|
||||
model_path=yolov8_model_path,
|
||||
confidence_threshold=0.3,
|
||||
device="cpu", # or 'cuda:0'
|
||||
)
|
||||
```
|
||||
|
||||
### Perform Standard Prediction
|
||||
|
||||
Perform standard inference using an image path or a numpy image.
|
||||
|
||||
```python
|
||||
# With an image path
|
||||
result = get_prediction("demo_data/small-vehicles1.jpeg", detection_model)
|
||||
|
||||
# With a numpy image
|
||||
result = get_prediction(read_image("demo_data/small-vehicles1.jpeg"), detection_model)
|
||||
```
|
||||
|
||||
### Visualize Results
|
||||
|
||||
Export and visualize the predicted bounding boxes and masks:
|
||||
|
||||
```python
|
||||
result.export_visuals(export_dir="demo_data/")
|
||||
Image("demo_data/prediction_visual.png")
|
||||
```
|
||||
|
||||
## Sliced Inference with YOLOv8
|
||||
|
||||
Perform sliced inference by specifying the slice dimensions and overlap ratios:
|
||||
|
||||
```python
|
||||
result = get_sliced_prediction(
|
||||
"demo_data/small-vehicles1.jpeg",
|
||||
detection_model,
|
||||
slice_height=256,
|
||||
slice_width=256,
|
||||
overlap_height_ratio=0.2,
|
||||
overlap_width_ratio=0.2
|
||||
)
|
||||
```
|
||||
|
||||
## Handling Prediction Results
|
||||
|
||||
SAHI provides a `PredictionResult` object, which can be converted into various annotation formats:
|
||||
|
||||
```python
|
||||
# Access the object prediction list
|
||||
object_prediction_list = result.object_prediction_list
|
||||
|
||||
# Convert to COCO annotation, COCO prediction, imantics, and fiftyone formats
|
||||
result.to_coco_annotations()[:3]
|
||||
result.to_coco_predictions(image_id=1)[:3]
|
||||
result.to_imantics_annotations()[:3]
|
||||
result.to_fiftyone_detections()[:3]
|
||||
```
|
||||
|
||||
## Batch Prediction
|
||||
|
||||
For batch prediction on a directory of images:
|
||||
|
||||
```python
|
||||
predict(
|
||||
model_type="yolov8",
|
||||
model_path="path/to/yolov8n.pt",
|
||||
model_device="cpu", # or 'cuda:0'
|
||||
model_confidence_threshold=0.4,
|
||||
source="path/to/dir",
|
||||
slice_height=256,
|
||||
slice_width=256,
|
||||
overlap_height_ratio=0.2,
|
||||
overlap_width_ratio=0.2,
|
||||
)
|
||||
```
|
||||
|
||||
That's it! Now you're equipped to use YOLOv8 with SAHI for both standard and sliced inference.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
If you use SAHI in your research or development work, please cite the original SAHI paper and acknowledge the authors:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@article{akyon2022sahi,
|
||||
title={Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection},
|
||||
author={Akyon, Fatih Cagatay and Altinuc, Sinan Onur and Temizel, Alptekin},
|
||||
journal={2022 IEEE International Conference on Image Processing (ICIP)},
|
||||
doi={10.1109/ICIP46576.2022.9897990},
|
||||
pages={966-970},
|
||||
year={2022}
|
||||
}
|
||||
```
|
||||
|
||||
We extend our thanks to the SAHI research group for creating and maintaining this invaluable resource for the computer vision community. For more information about SAHI and its creators, visit the [SAHI GitHub repository](https://github.com/obss/sahi).
|
||||
166
docs/en/guides/security-alarm-system.md
Normal file
166
docs/en/guides/security-alarm-system.md
Normal file
@ -0,0 +1,166 @@
|
||||
---
|
||||
comments: true
|
||||
description: Security Alarm System Project Using Ultralytics YOLOv8. Learn How to implement a Security Alarm System Using ultralytics YOLOv8
|
||||
keywords: Object Detection, Security Alarm, Object Tracking, YOLOv8, Computer Vision Projects
|
||||
---
|
||||
|
||||
# Security Alarm System Project Using Ultralytics YOLOv8
|
||||
|
||||
<img src="https://github.com/RizwanMunawar/ultralytics/assets/62513924/f4e4a613-fb25-4bd0-9ec5-78352ddb62bd" alt="Security Alarm System">
|
||||
|
||||
The Security Alarm System Project utilizing Ultralytics YOLOv8 integrates advanced computer vision capabilities to enhance security measures. YOLOv8, developed by Ultralytics, provides real-time object detection, allowing the system to identify and respond to potential security threats promptly. This project offers several advantages:
|
||||
|
||||
- **Real-time Detection:** YOLOv8's efficiency enables the Security Alarm System to detect and respond to security incidents in real-time, minimizing response time.
|
||||
- **Accuracy:** YOLOv8 is known for its accuracy in object detection, reducing false positives and enhancing the reliability of the security alarm system.
|
||||
- **Integration Capabilities:** The project can be seamlessly integrated with existing security infrastructure, providing an upgraded layer of intelligent surveillance.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/_1CmwUzoxY4"
|
||||
title="YouTube video player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Watch:</strong> Security Alarm System Project with Ultralytics YOLOv8 Object Detection
|
||||
</p>
|
||||
|
||||
### Code
|
||||
|
||||
#### Import Libraries
|
||||
|
||||
```python
|
||||
import torch
|
||||
import numpy as np
|
||||
import cv2
|
||||
from time import time
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.utils.plotting import Annotator, colors
|
||||
import smtplib
|
||||
from email.mime.multipart import MIMEMultipart
|
||||
from email.mime.text import MIMEText
|
||||
```
|
||||
|
||||
#### Set up the parameters of the message
|
||||
|
||||
???+ tip "Note"
|
||||
|
||||
App Password Generation is necessary
|
||||
|
||||
- Navigate to [App Password Generator](https://myaccount.google.com/apppasswords), designate an app name such as "security project," and obtain a 16-digit password. Copy this password and paste it into the designated password field as instructed.
|
||||
|
||||
```python
|
||||
password = ""
|
||||
from_email = "" # must match the email used to generate the password
|
||||
to_email = "" # receiver email
|
||||
```
|
||||
|
||||
#### Server creation and authentication
|
||||
|
||||
```python
|
||||
server = smtplib.SMTP('smtp.gmail.com: 587')
|
||||
server.starttls()
|
||||
server.login(from_email, password)
|
||||
```
|
||||
|
||||
#### Email Send Function
|
||||
|
||||
```python
|
||||
def send_email(to_email, from_email, object_detected=1):
|
||||
message = MIMEMultipart()
|
||||
message['From'] = from_email
|
||||
message['To'] = to_email
|
||||
message['Subject'] = "Security Alert"
|
||||
# Add in the message body
|
||||
message_body = f'ALERT - {object_detected} objects has been detected!!'
|
||||
|
||||
message.attach(MIMEText(message_body, 'plain'))
|
||||
server.sendmail(from_email, to_email, message.as_string())
|
||||
```
|
||||
|
||||
#### Object Detection and Alert Sender
|
||||
|
||||
```python
|
||||
class ObjectDetection:
|
||||
def __init__(self, capture_index):
|
||||
# default parameters
|
||||
self.capture_index = capture_index
|
||||
self.email_sent = False
|
||||
|
||||
# model information
|
||||
self.model = YOLO("yolov8n.pt")
|
||||
|
||||
# visual information
|
||||
self.annotator = None
|
||||
self.start_time = 0
|
||||
self.end_time = 0
|
||||
|
||||
# device information
|
||||
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
||||
|
||||
def predict(self, im0):
|
||||
results = self.model(im0)
|
||||
return results
|
||||
|
||||
def display_fps(self, im0):
|
||||
self.end_time = time()
|
||||
fps = 1 / np.round(self.end_time - self.start_time, 2)
|
||||
text = f'FPS: {int(fps)}'
|
||||
text_size = cv2.getTextSize(text, cv2.FONT_HERSHEY_SIMPLEX, 1.0, 2)[0]
|
||||
gap = 10
|
||||
cv2.rectangle(im0, (20 - gap, 70 - text_size[1] - gap), (20 + text_size[0] + gap, 70 + gap), (255, 255, 255), -1)
|
||||
cv2.putText(im0, text, (20, 70), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 0), 2)
|
||||
|
||||
def plot_bboxes(self, results, im0):
|
||||
class_ids = []
|
||||
self.annotator = Annotator(im0, 3, results[0].names)
|
||||
boxes = results[0].boxes.xyxy.cpu()
|
||||
clss = results[0].boxes.cls.cpu().tolist()
|
||||
names = results[0].names
|
||||
for box, cls in zip(boxes, clss):
|
||||
class_ids.append(cls)
|
||||
self.annotator.box_label(box, label=names[int(cls)], color=colors(int(cls), True))
|
||||
return im0, class_ids
|
||||
|
||||
def __call__(self):
|
||||
cap = cv2.VideoCapture(self.capture_index)
|
||||
assert cap.isOpened()
|
||||
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
|
||||
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
|
||||
frame_count = 0
|
||||
while True:
|
||||
self.start_time = time()
|
||||
ret, im0 = cap.read()
|
||||
assert ret
|
||||
results = self.predict(im0)
|
||||
im0, class_ids = self.plot_bboxes(results, im0)
|
||||
|
||||
if len(class_ids) > 0: # Only send email If not sent before
|
||||
if not self.email_sent:
|
||||
send_email(to_email, from_email, len(class_ids))
|
||||
self.email_sent = True
|
||||
else:
|
||||
self.email_sent = False
|
||||
|
||||
self.display_fps(im0)
|
||||
cv2.imshow('YOLOv8 Detection', im0)
|
||||
frame_count += 1
|
||||
if cv2.waitKey(5) & 0xFF == 27:
|
||||
break
|
||||
cap.release()
|
||||
cv2.destroyAllWindows()
|
||||
server.quit()
|
||||
```
|
||||
|
||||
#### Call the Object Detection class and Run the Inference
|
||||
|
||||
```python
|
||||
detector = ObjectDetection(capture_index=0)
|
||||
detector()
|
||||
```
|
||||
|
||||
That's it! When you execute the code, you'll receive a single notification on your email if any object is detected. The notification is sent immediately, not repeatedly. However, feel free to customize the code to suit your project requirements.
|
||||
|
||||
#### Email Received Sample
|
||||
|
||||
<img width="256" src="https://github.com/RizwanMunawar/ultralytics/assets/62513924/db79ccc6-aabd-4566-a825-b34e679c90f9" alt="Email Received Sample">
|
||||
110
docs/en/guides/speed-estimation.md
Normal file
110
docs/en/guides/speed-estimation.md
Normal file
@ -0,0 +1,110 @@
|
||||
---
|
||||
comments: true
|
||||
description: Speed Estimation Using Ultralytics YOLOv8
|
||||
keywords: Ultralytics, YOLOv8, Object Detection, Speed Estimation, Object Tracking, Notebook, IPython Kernel, CLI, Python SDK
|
||||
---
|
||||
|
||||
# Speed Estimation using Ultralytics YOLOv8 🚀
|
||||
|
||||
## What is Speed Estimation?
|
||||
|
||||
Speed estimation is the process of calculating the rate of movement of an object within a given context, often employed in computer vision applications. Using [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) you can now calculate the speed of object using [object tracking](https://docs.ultralytics.com/modes/track/) alongside distance and time data, crucial for tasks like traffic and surveillance. The accuracy of speed estimation directly influences the efficiency and reliability of various applications, making it a key component in the advancement of intelligent systems and real-time decision-making processes.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/rCggzXRRSRo"
|
||||
title="YouTube video player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Watch:</strong> Speed Estimation using Ultralytics YOLOv8
|
||||
</p>
|
||||
|
||||
## Advantages of Speed Estimation?
|
||||
|
||||
- **Efficient Traffic Control:** Accurate speed estimation aids in managing traffic flow, enhancing safety, and reducing congestion on roadways.
|
||||
- **Precise Autonomous Navigation:** In autonomous systems like self-driving cars, reliable speed estimation ensures safe and accurate vehicle navigation.
|
||||
- **Enhanced Surveillance Security:** Speed estimation in surveillance analytics helps identify unusual behaviors or potential threats, improving the effectiveness of security measures.
|
||||
|
||||
## Real World Applications
|
||||
|
||||
| Transportation | Transportation |
|
||||
|:-------------------------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
|  |  |
|
||||
| Speed Estimation on Road using Ultralytics YOLOv8 | Speed Estimation on Bridge using Ultralytics YOLOv8 |
|
||||
|
||||
!!! Example "Speed Estimation using YOLOv8 Example"
|
||||
|
||||
=== "Speed Estimation"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.solutions import speed_estimation
|
||||
import cv2
|
||||
|
||||
model = YOLO("yolov8n.pt")
|
||||
names = model.model.names
|
||||
|
||||
cap = cv2.VideoCapture("path/to/video/file.mp4")
|
||||
assert cap.isOpened(), "Error reading video file"
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
# Video writer
|
||||
video_writer = cv2.VideoWriter("speed_estimation.avi",
|
||||
cv2.VideoWriter_fourcc(*'mp4v'),
|
||||
fps,
|
||||
(w, h))
|
||||
|
||||
line_pts = [(0, 360), (1280, 360)]
|
||||
|
||||
# Init speed-estimation obj
|
||||
speed_obj = speed_estimation.SpeedEstimator()
|
||||
speed_obj.set_args(reg_pts=line_pts,
|
||||
names=names,
|
||||
view_img=True)
|
||||
|
||||
while cap.isOpened():
|
||||
|
||||
success, im0 = cap.read()
|
||||
if not success:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
|
||||
tracks = model.track(im0, persist=True, show=False)
|
||||
|
||||
im0 = speed_obj.estimate_speed(im0, tracks)
|
||||
video_writer.write(im0)
|
||||
|
||||
cap.release()
|
||||
video_writer.release()
|
||||
cv2.destroyAllWindows()
|
||||
|
||||
```
|
||||
|
||||
???+ warning "Speed is Estimate"
|
||||
|
||||
Speed will be an estimate and may not be completely accurate. Additionally, the estimation can vary depending on GPU speed.
|
||||
|
||||
### Optional Arguments `set_args`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|--------------------|--------|----------------------------|---------------------------------------------------|
|
||||
| `reg_pts` | `list` | `[(20, 400), (1260, 400)]` | Points defining the Region Area |
|
||||
| `names` | `dict` | `None` | Classes names |
|
||||
| `view_img` | `bool` | `False` | Display frames with counts |
|
||||
| `line_thickness` | `int` | `2` | Increase bounding boxes thickness |
|
||||
| `region_thickness` | `int` | `5` | Thickness for object counter region or line |
|
||||
| `spdl_dist_thresh` | `int` | `10` | Euclidean Distance threshold for speed check line |
|
||||
|
||||
### Arguments `model.track`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------|---------|----------------|-------------------------------------------------------------|
|
||||
| `source` | `im0` | `None` | source directory for images or videos |
|
||||
| `persist` | `bool` | `False` | persisting tracks between frames |
|
||||
| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
|
||||
| `conf` | `float` | `0.3` | Confidence Threshold |
|
||||
| `iou` | `float` | `0.5` | IOU Threshold |
|
||||
| `classes` | `list` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] |
|
||||
| `verbose` | `bool` | `True` | Display the object tracking results |
|
||||
137
docs/en/guides/triton-inference-server.md
Normal file
137
docs/en/guides/triton-inference-server.md
Normal file
@ -0,0 +1,137 @@
|
||||
---
|
||||
comments: true
|
||||
description: A step-by-step guide on integrating Ultralytics YOLOv8 with Triton Inference Server for scalable and high-performance deep learning inference deployments.
|
||||
keywords: YOLOv8, Triton Inference Server, ONNX, Deep Learning Deployment, Scalable Inference, Ultralytics, NVIDIA, Object Detection, Cloud Inference
|
||||
---
|
||||
|
||||
# Triton Inference Server with Ultralytics YOLOv8
|
||||
|
||||
The [Triton Inference Server](https://developer.nvidia.com/nvidia-triton-inference-server) (formerly known as TensorRT Inference Server) is an open-source software solution developed by NVIDIA. It provides a cloud inference solution optimized for NVIDIA GPUs. Triton simplifies the deployment of AI models at scale in production. Integrating Ultralytics YOLOv8 with Triton Inference Server allows you to deploy scalable, high-performance deep learning inference workloads. This guide provides steps to set up and test the integration.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/NQDtfSi5QF4"
|
||||
title="Getting Started with NVIDIA Triton Inference Server" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Watch:</strong> Getting Started with NVIDIA Triton Inference Server.
|
||||
</p>
|
||||
|
||||
## What is Triton Inference Server?
|
||||
|
||||
Triton Inference Server is designed to deploy a variety of AI models in production. It supports a wide range of deep learning and machine learning frameworks, including TensorFlow, PyTorch, ONNX Runtime, and many others. Its primary use cases are:
|
||||
|
||||
- Serving multiple models from a single server instance.
|
||||
- Dynamic model loading and unloading without server restart.
|
||||
- Ensemble inference, allowing multiple models to be used together to achieve results.
|
||||
- Model versioning for A/B testing and rolling updates.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Ensure you have the following prerequisites before proceeding:
|
||||
|
||||
- Docker installed on your machine.
|
||||
- Install `tritonclient`:
|
||||
```bash
|
||||
pip install tritonclient[all]
|
||||
```
|
||||
|
||||
## Exporting YOLOv8 to ONNX Format
|
||||
|
||||
Before deploying the model on Triton, it must be exported to the ONNX format. ONNX (Open Neural Network Exchange) is a format that allows models to be transferred between different deep learning frameworks. Use the `export` function from the `YOLO` class:
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load an official model
|
||||
|
||||
# Export the model
|
||||
onnx_file = model.export(format='onnx', dynamic=True)
|
||||
```
|
||||
|
||||
## Setting Up Triton Model Repository
|
||||
|
||||
The Triton Model Repository is a storage location where Triton can access and load models.
|
||||
|
||||
1. Create the necessary directory structure:
|
||||
|
||||
```python
|
||||
from pathlib import Path
|
||||
|
||||
# Define paths
|
||||
triton_repo_path = Path('tmp') / 'triton_repo'
|
||||
triton_model_path = triton_repo_path / 'yolo'
|
||||
|
||||
# Create directories
|
||||
(triton_model_path / '1').mkdir(parents=True, exist_ok=True)
|
||||
```
|
||||
|
||||
2. Move the exported ONNX model to the Triton repository:
|
||||
|
||||
```python
|
||||
from pathlib import Path
|
||||
|
||||
# Move ONNX model to Triton Model path
|
||||
Path(onnx_file).rename(triton_model_path / '1' / 'model.onnx')
|
||||
|
||||
# Create config file
|
||||
(triton_model_path / 'config.pbtxt').touch()
|
||||
```
|
||||
|
||||
## Running Triton Inference Server
|
||||
|
||||
Run the Triton Inference Server using Docker:
|
||||
|
||||
```python
|
||||
import subprocess
|
||||
import time
|
||||
|
||||
from tritonclient.http import InferenceServerClient
|
||||
|
||||
# Define image https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tritonserver
|
||||
tag = 'nvcr.io/nvidia/tritonserver:23.09-py3' # 6.4 GB
|
||||
|
||||
# Pull the image
|
||||
subprocess.call(f'docker pull {tag}', shell=True)
|
||||
|
||||
# Run the Triton server and capture the container ID
|
||||
container_id = subprocess.check_output(
|
||||
f'docker run -d --rm -v {triton_repo_path}:/models -p 8000:8000 {tag} tritonserver --model-repository=/models',
|
||||
shell=True).decode('utf-8').strip()
|
||||
|
||||
# Wait for the Triton server to start
|
||||
triton_client = InferenceServerClient(url='localhost:8000', verbose=False, ssl=False)
|
||||
|
||||
# Wait until model is ready
|
||||
for _ in range(10):
|
||||
with contextlib.suppress(Exception):
|
||||
assert triton_client.is_model_ready(model_name)
|
||||
break
|
||||
time.sleep(1)
|
||||
```
|
||||
|
||||
Then run inference using the Triton Server model:
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load the Triton Server model
|
||||
model = YOLO(f'http://localhost:8000/yolo', task='detect')
|
||||
|
||||
# Run inference on the server
|
||||
results = model('path/to/image.jpg')
|
||||
```
|
||||
|
||||
Cleanup the container:
|
||||
|
||||
```python
|
||||
# Kill and remove the container at the end of the test
|
||||
subprocess.call(f'docker kill {container_id}', shell=True)
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
By following the above steps, you can deploy and run Ultralytics YOLOv8 models efficiently on Triton Inference Server, providing a scalable and high-performance solution for deep learning inference tasks. If you face any issues or have further queries, refer to the [official Triton documentation](https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/index.html) or reach out to the Ultralytics community for support.
|
||||
146
docs/en/guides/view-results-in-terminal.md
Normal file
146
docs/en/guides/view-results-in-terminal.md
Normal file
@ -0,0 +1,146 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to view image results inside a compatible VSCode terminal.
|
||||
keywords: YOLOv8, VSCode, Terminal, Remote Development, Ultralytics, SSH, Object Detection, Inference, Results, Remote Tunnel, Images, Helpful, Productivity Hack
|
||||
---
|
||||
|
||||
# Viewing Inference Results in a Terminal
|
||||
|
||||
<p align="center">
|
||||
<img width="800" src="https://raw.githubusercontent.com/saitoha/libsixel/data/data/sixel.gif" alt="Sixel example of image in Terminal">
|
||||
</p>
|
||||
|
||||
Image from the [libsixel](https://saitoha.github.io/libsixel/) website.
|
||||
|
||||
## Motivation
|
||||
|
||||
When connecting to a remote machine, normally visualizing image results is not possible or requires moving data to a local device with a GUI. The VSCode integrated terminal allows for directly rendering images. This is a short demonstration on how to use this in conjunction with `ultralytics` with [prediction results](../modes/predict.md).
|
||||
|
||||
!!! warning
|
||||
|
||||
Only compatible with Linux and MacOS. Check the VSCode [repository](https://github.com/microsoft/vscode), check [Issue status](https://github.com/microsoft/vscode/issues/198622), or [documentation](https://code.visualstudio.com/docs) for updates about Windows support to view images in terminal with `sixel`.
|
||||
|
||||
The VSCode compatible protocols for viewing images using the integrated terminal are [`sixel`](https://en.wikipedia.org/wiki/Sixel) and [`iTerm`](https://iterm2.com/documentation-images.html). This guide will demonstrate use of the `sixel` protocol.
|
||||
|
||||
## Process
|
||||
|
||||
1. First, you must enable settings `terminal.integrated.enableImages` and `terminal.integrated.gpuAcceleration` in VSCode.
|
||||
|
||||
```yaml
|
||||
"terminal.integrated.gpuAcceleration": "auto" # "auto" is default, can also use "on"
|
||||
"terminal.integrated.enableImages": false
|
||||
```
|
||||
|
||||
<p align="center">
|
||||
<img width="800" src="https://github.com/ultralytics/ultralytics/assets/62214284/d158ab1c-893c-4397-a5de-2f9f74f81175" alt="VSCode enable terminal images setting">
|
||||
</p>
|
||||
|
||||
1. Install the `python-sixel` library in your virtual environment. This is a [fork](https://github.com/lubosz/python-sixel?tab=readme-ov-file) of the `PySixel` library, which is no longer maintained.
|
||||
|
||||
```bash
|
||||
pip install sixel
|
||||
```
|
||||
|
||||
1. Import the relevant libraries
|
||||
|
||||
```py
|
||||
import io
|
||||
|
||||
import cv2 as cv
|
||||
|
||||
from ultralytics import YOLO
|
||||
from sixel import SixelWriter
|
||||
```
|
||||
|
||||
1. Load a model and execute inference, then plot the results and store in a variable. See more about inference arguments and working with results on the [predict mode](../modes/predict.md) page.
|
||||
|
||||
```{ .py .annotate }
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO("yolov8n.pt")
|
||||
|
||||
# Run inference on an image
|
||||
results = model.predict(source="ultralytics/assets/bus.jpg")
|
||||
|
||||
# Plot inference results
|
||||
plot = results[0].plot() #(1)!
|
||||
```
|
||||
|
||||
1. See [plot method parameters](../modes/predict.md#plot-method-parameters) to see possible arguments to use.
|
||||
|
||||
1. Now, use OpenCV to convert the `numpy.ndarray` to `bytes` data. Then use `io.BytesIO` to make a "file-like" object.
|
||||
|
||||
```{ .py .annotate }
|
||||
# Results image as bytes
|
||||
im_bytes = cv.imencode(
|
||||
".png", #(1)!
|
||||
plot,
|
||||
)[1].tobytes() #(2)!
|
||||
|
||||
# Image bytes as a file-like object
|
||||
mem_file = io.BytesIO(im_bytes)
|
||||
```
|
||||
|
||||
1. It's possible to use other image extensions as well.
|
||||
2. Only the object at index `1` that is returned is needed.
|
||||
|
||||
1. Create a `SixelWriter` instance, and then use the `.draw()` method to draw the image in the terminal.
|
||||
|
||||
```py
|
||||
# Create sixel writer object
|
||||
w = SixelWriter()
|
||||
|
||||
# Draw the sixel image in the terminal
|
||||
w.draw(mem_file)
|
||||
```
|
||||
|
||||
## Example Inference Results
|
||||
|
||||
<p align="center">
|
||||
<img width="800" src="https://github.com/ultralytics/ultralytics/assets/62214284/6743ab64-300d-4429-bdce-e246455f7b68" alt="View Image in Terminal">
|
||||
</p>
|
||||
|
||||
!!! danger
|
||||
|
||||
Using this example with videos or animated GIF frames has **not** been tested. Attempt at your own risk.
|
||||
|
||||
## Full Code Example
|
||||
|
||||
```{ .py .annotate }
|
||||
import io
|
||||
|
||||
import cv2 as cv
|
||||
|
||||
from ultralytics import YOLO
|
||||
from sixel import SixelWriter
|
||||
|
||||
# Load a model
|
||||
model = YOLO("yolov8n.pt")
|
||||
|
||||
# Run inference on an image
|
||||
results = model.predict(source="ultralytics/assets/bus.jpg")
|
||||
|
||||
# Plot inference results
|
||||
plot = results[0].plot() #(3)!
|
||||
|
||||
# Results image as bytes
|
||||
im_bytes = cv.imencode(
|
||||
".png", #(1)!
|
||||
plot,
|
||||
)[1].tobytes() #(2)!
|
||||
|
||||
mem_file = io.BytesIO(im_bytes)
|
||||
w = SixelWriter()
|
||||
w.draw(mem_file)
|
||||
```
|
||||
|
||||
1. It's possible to use other image extensions as well.
|
||||
2. Only the object at index `1` that is returned is needed.
|
||||
3. See [plot method parameters](../modes/predict.md#plot-method-parameters) to see possible arguments to use.
|
||||
|
||||
---
|
||||
|
||||
!!! tip
|
||||
|
||||
You may need to use `clear` to "erase" the view of the image in the terminal.
|
||||
177
docs/en/guides/vision-eye.md
Normal file
177
docs/en/guides/vision-eye.md
Normal file
@ -0,0 +1,177 @@
|
||||
---
|
||||
comments: true
|
||||
description: VisionEye View Object Mapping using Ultralytics YOLOv8
|
||||
keywords: Ultralytics, YOLOv8, Object Detection, Object Tracking, IDetection, VisionEye, Computer Vision, Notebook, IPython Kernel, CLI, Python SDK
|
||||
---
|
||||
|
||||
# VisionEye View Object Mapping using Ultralytics YOLOv8 🚀
|
||||
|
||||
## What is VisionEye Object Mapping?
|
||||
|
||||
[Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) VisionEye offers the capability for computers to identify and pinpoint objects, simulating the observational precision of the human eye. This functionality enables computers to discern and focus on specific objects, much like the way the human eye observes details from a particular viewpoint.
|
||||
|
||||
## Samples
|
||||
|
||||
| VisionEye View | VisionEye View With Object Tracking | VisionEye View With Distance Calculation |
|
||||
|:------------------------------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
|  |  |  |
|
||||
| VisionEye View Object Mapping using Ultralytics YOLOv8 | VisionEye View Object Mapping with Object Tracking using Ultralytics YOLOv8 | VisionEye View with Distance Calculation using Ultralytics YOLOv8 |
|
||||
|
||||
!!! Example "VisionEye Object Mapping using YOLOv8"
|
||||
|
||||
=== "VisionEye Object Mapping"
|
||||
|
||||
```python
|
||||
import cv2
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.utils.plotting import colors, Annotator
|
||||
|
||||
model = YOLO("yolov8n.pt")
|
||||
names = model.model.names
|
||||
cap = cv2.VideoCapture("path/to/video/file.mp4")
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
out = cv2.VideoWriter('visioneye-pinpoint.avi', cv2.VideoWriter_fourcc(*'MJPG'), fps, (w, h))
|
||||
|
||||
center_point = (-10, h)
|
||||
|
||||
while True:
|
||||
ret, im0 = cap.read()
|
||||
if not ret:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
|
||||
results = model.predict(im0)
|
||||
boxes = results[0].boxes.xyxy.cpu()
|
||||
clss = results[0].boxes.cls.cpu().tolist()
|
||||
|
||||
annotator = Annotator(im0, line_width=2)
|
||||
|
||||
for box, cls in zip(boxes, clss):
|
||||
annotator.box_label(box, label=names[int(cls)], color=colors(int(cls)))
|
||||
annotator.visioneye(box, center_point)
|
||||
|
||||
out.write(im0)
|
||||
cv2.imshow("visioneye-pinpoint", im0)
|
||||
|
||||
if cv2.waitKey(1) & 0xFF == ord('q'):
|
||||
break
|
||||
|
||||
out.release()
|
||||
cap.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
=== "VisionEye Object Mapping with Object Tracking"
|
||||
|
||||
```python
|
||||
import cv2
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.utils.plotting import colors, Annotator
|
||||
|
||||
model = YOLO("yolov8n.pt")
|
||||
cap = cv2.VideoCapture("path/to/video/file.mp4")
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
out = cv2.VideoWriter('visioneye-pinpoint.avi', cv2.VideoWriter_fourcc(*'MJPG'), fps, (w, h))
|
||||
|
||||
center_point = (-10, h)
|
||||
|
||||
while True:
|
||||
ret, im0 = cap.read()
|
||||
if not ret:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
|
||||
annotator = Annotator(im0, line_width=2)
|
||||
|
||||
results = model.track(im0, persist=True)
|
||||
boxes = results[0].boxes.xyxy.cpu()
|
||||
|
||||
if results[0].boxes.id is not None:
|
||||
track_ids = results[0].boxes.id.int().cpu().tolist()
|
||||
|
||||
for box, track_id in zip(boxes, track_ids):
|
||||
annotator.box_label(box, label=str(track_id), color=colors(int(track_id)))
|
||||
annotator.visioneye(box, center_point)
|
||||
|
||||
out.write(im0)
|
||||
cv2.imshow("visioneye-pinpoint", im0)
|
||||
|
||||
if cv2.waitKey(1) & 0xFF == ord('q'):
|
||||
break
|
||||
|
||||
out.release()
|
||||
cap.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
=== "VisionEye with Distance Calculation"
|
||||
|
||||
```python
|
||||
import cv2
|
||||
import math
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.utils.plotting import Annotator, colors
|
||||
|
||||
model = YOLO("yolov8s.pt")
|
||||
cap = cv2.VideoCapture("Path/to/video/file.mp4")
|
||||
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
out = cv2.VideoWriter('visioneye-distance-calculation.avi', cv2.VideoWriter_fourcc(*'MJPG'), fps, (w, h))
|
||||
|
||||
center_point = (0, h)
|
||||
pixel_per_meter = 10
|
||||
|
||||
txt_color, txt_background, bbox_clr = ((0, 0, 0), (255, 255, 255), (255, 0, 255))
|
||||
|
||||
while True:
|
||||
ret, im0 = cap.read()
|
||||
if not ret:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
|
||||
annotator = Annotator(im0, line_width=2)
|
||||
|
||||
results = model.track(im0, persist=True)
|
||||
boxes = results[0].boxes.xyxy.cpu()
|
||||
|
||||
if results[0].boxes.id is not None:
|
||||
track_ids = results[0].boxes.id.int().cpu().tolist()
|
||||
|
||||
for box, track_id in zip(boxes, track_ids):
|
||||
annotator.box_label(box, label=str(track_id), color=bbox_clr)
|
||||
annotator.visioneye(box, center_point)
|
||||
|
||||
x1, y1 = int((box[0] + box[2]) // 2), int((box[1] + box[3]) // 2) # Bounding box centroid
|
||||
|
||||
distance = (math.sqrt((x1 - center_point[0]) ** 2 + (y1 - center_point[1]) ** 2))/pixel_per_meter
|
||||
|
||||
text_size, _ = cv2.getTextSize(f"Distance: {distance:.2f} m", cv2.FONT_HERSHEY_SIMPLEX,1.2, 3)
|
||||
cv2.rectangle(im0, (x1, y1 - text_size[1] - 10),(x1 + text_size[0] + 10, y1), txt_background, -1)
|
||||
cv2.putText(im0, f"Distance: {distance:.2f} m",(x1, y1 - 5), cv2.FONT_HERSHEY_SIMPLEX, 1.2,txt_color, 3)
|
||||
|
||||
out.write(im0)
|
||||
cv2.imshow("visioneye-distance-calculation", im0)
|
||||
|
||||
if cv2.waitKey(1) & 0xFF == ord('q'):
|
||||
break
|
||||
|
||||
out.release()
|
||||
cap.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
### `visioneye` Arguments
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|---------------|---------|------------------|--------------------------------------------------|
|
||||
| `color` | `tuple` | `(235, 219, 11)` | Line and object centroid color |
|
||||
| `pin_color` | `tuple` | `(255, 0, 255)` | VisionEye pinpoint color |
|
||||
| `thickness` | `int` | `2` | pinpoint to object line thickness |
|
||||
| `pins_radius` | `int` | `10` | Pinpoint and object centroid point circle radius |
|
||||
|
||||
## Note
|
||||
|
||||
For any inquiries, feel free to post your questions in the [Ultralytics Issue Section](https://github.com/ultralytics/ultralytics/issues/new/choose) or the discussion section mentioned below.
|
||||
148
docs/en/guides/workouts-monitoring.md
Normal file
148
docs/en/guides/workouts-monitoring.md
Normal file
@ -0,0 +1,148 @@
|
||||
---
|
||||
comments: true
|
||||
description: Workouts Monitoring Using Ultralytics YOLOv8
|
||||
keywords: Ultralytics, YOLOv8, Object Detection, Pose Estimation, PushUps, PullUps, Ab workouts, Notebook, IPython Kernel, CLI, Python SDK
|
||||
---
|
||||
|
||||
# Workouts Monitoring using Ultralytics YOLOv8 🚀
|
||||
|
||||
Monitoring workouts through pose estimation with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) enhances exercise assessment by accurately tracking key body landmarks and joints in real-time. This technology provides instant feedback on exercise form, tracks workout routines, and measures performance metrics, optimizing training sessions for users and trainers alike.
|
||||
|
||||
## Advantages of Workouts Monitoring?
|
||||
|
||||
- **Optimized Performance:** Tailoring workouts based on monitoring data for better results.
|
||||
- **Goal Achievement:** Track and adjust fitness goals for measurable progress.
|
||||
- **Personalization:** Customized workout plans based on individual data for effectiveness.
|
||||
- **Health Awareness:** Early detection of patterns indicating health issues or over-training.
|
||||
- **Informed Decisions:** Data-driven decisions for adjusting routines and setting realistic goals.
|
||||
|
||||
## Real World Applications
|
||||
|
||||
| Workouts Monitoring | Workouts Monitoring |
|
||||
|:----------------------------------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------------------------------:|
|
||||
|  |  |
|
||||
| PushUps Counting | PullUps Counting |
|
||||
|
||||
!!! Example "Workouts Monitoring Example"
|
||||
|
||||
=== "Workouts Monitoring"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.solutions import ai_gym
|
||||
import cv2
|
||||
|
||||
model = YOLO("yolov8n-pose.pt")
|
||||
cap = cv2.VideoCapture("path/to/video/file.mp4")
|
||||
assert cap.isOpened(), "Error reading video file"
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
gym_object = ai_gym.AIGym() # init AI GYM module
|
||||
gym_object.set_args(line_thickness=2,
|
||||
view_img=True,
|
||||
pose_type="pushup",
|
||||
kpts_to_check=[6, 8, 10])
|
||||
|
||||
frame_count = 0
|
||||
while cap.isOpened():
|
||||
success, im0 = cap.read()
|
||||
if not success:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
frame_count += 1
|
||||
results = model.track(im0, verbose=False) # Tracking recommended
|
||||
#results = model.predict(im0) # Prediction also supported
|
||||
im0 = gym_object.start_counting(im0, results, frame_count)
|
||||
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
=== "Workouts Monitoring with Save Output"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
from ultralytics.solutions import ai_gym
|
||||
import cv2
|
||||
|
||||
model = YOLO("yolov8n-pose.pt")
|
||||
cap = cv2.VideoCapture("path/to/video/file.mp4")
|
||||
assert cap.isOpened(), "Error reading video file"
|
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
|
||||
|
||||
video_writer = cv2.VideoWriter("workouts.avi",
|
||||
cv2.VideoWriter_fourcc(*'mp4v'),
|
||||
fps,
|
||||
(w, h))
|
||||
|
||||
gym_object = ai_gym.AIGym() # init AI GYM module
|
||||
gym_object.set_args(line_thickness=2,
|
||||
view_img=True,
|
||||
pose_type="pushup",
|
||||
kpts_to_check=[6, 8, 10])
|
||||
|
||||
frame_count = 0
|
||||
while cap.isOpened():
|
||||
success, im0 = cap.read()
|
||||
if not success:
|
||||
print("Video frame is empty or video processing has been successfully completed.")
|
||||
break
|
||||
frame_count += 1
|
||||
results = model.track(im0, verbose=False) # Tracking recommended
|
||||
#results = model.predict(im0) # Prediction also supported
|
||||
im0 = gym_object.start_counting(im0, results, frame_count)
|
||||
video_writer.write(im0)
|
||||
|
||||
cv2.destroyAllWindows()
|
||||
video_writer.release()
|
||||
```
|
||||
|
||||
???+ tip "Support"
|
||||
|
||||
"pushup", "pullup" and "abworkout" supported
|
||||
|
||||
### KeyPoints Map
|
||||
|
||||
|
||||
|
||||
### Arguments `set_args`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-------------------|--------|----------|----------------------------------------------------------------------------------------|
|
||||
| `kpts_to_check` | `list` | `None` | List of three keypoints index, for counting specific workout, followed by keypoint Map |
|
||||
| `view_img` | `bool` | `False` | Display the frame with counts |
|
||||
| `line_thickness` | `int` | `2` | Increase the thickness of count value |
|
||||
| `pose_type` | `str` | `pushup` | Pose that need to be monitored, `pullup` and `abworkout` also supported |
|
||||
| `pose_up_angle` | `int` | `145` | Pose Up Angle value |
|
||||
| `pose_down_angle` | `int` | `90` | Pose Down Angle value |
|
||||
|
||||
### Arguments `model.predict`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------------|----------------|------------------------|----------------------------------------------------------------------------|
|
||||
| `source` | `str` | `'ultralytics/assets'` | source directory for images or videos |
|
||||
| `conf` | `float` | `0.25` | object confidence threshold for detection |
|
||||
| `iou` | `float` | `0.7` | intersection over union (IoU) threshold for NMS |
|
||||
| `imgsz` | `int or tuple` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
|
||||
| `half` | `bool` | `False` | use half precision (FP16) |
|
||||
| `device` | `None or str` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |
|
||||
| `max_det` | `int` | `300` | maximum number of detections per image |
|
||||
| `vid_stride` | `bool` | `False` | video frame-rate stride |
|
||||
| `stream_buffer` | `bool` | `False` | buffer all streaming frames (True) or return the most recent frame (False) |
|
||||
| `visualize` | `bool` | `False` | visualize model features |
|
||||
| `augment` | `bool` | `False` | apply image augmentation to prediction sources |
|
||||
| `agnostic_nms` | `bool` | `False` | class-agnostic NMS |
|
||||
| `classes` | `list[int]` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] |
|
||||
| `retina_masks` | `bool` | `False` | use high-resolution segmentation masks |
|
||||
| `embed` | `list[int]` | `None` | return feature vectors/embeddings from given layers |
|
||||
|
||||
### Arguments `model.track`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------|---------|----------------|-------------------------------------------------------------|
|
||||
| `source` | `im0` | `None` | source directory for images or videos |
|
||||
| `persist` | `bool` | `False` | persisting tracks between frames |
|
||||
| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
|
||||
| `conf` | `float` | `0.3` | Confidence Threshold |
|
||||
| `iou` | `float` | `0.5` | IOU Threshold |
|
||||
| `classes` | `list` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] |
|
||||
| `verbose` | `bool` | `True` | Display the object tracking results |
|
||||
276
docs/en/guides/yolo-common-issues.md
Normal file
276
docs/en/guides/yolo-common-issues.md
Normal file
@ -0,0 +1,276 @@
|
||||
---
|
||||
comments: true
|
||||
description: A comprehensive guide to troubleshooting common issues encountered while working with YOLOv8 in the Ultralytics ecosystem.
|
||||
keywords: Troubleshooting, Ultralytics, YOLOv8, Installation Errors, Training Data, Model Performance, Hyperparameter Tuning, Deployment
|
||||
---
|
||||
|
||||
# Troubleshooting Common YOLO Issues
|
||||
|
||||
<p align="center">
|
||||
<img width="800" src="https://user-images.githubusercontent.com/26833433/273067258-7c1b9aee-b4e8-43b5-befd-588d4f0bd361.png" alt="YOLO Common Issues Image">
|
||||
</p>
|
||||
|
||||
## Introduction
|
||||
|
||||
This guide serves as a comprehensive aid for troubleshooting common issues encountered while working with YOLOv8 on your Ultralytics projects. Navigating through these issues can be a breeze with the right guidance, ensuring your projects remain on track without unnecessary delays.
|
||||
|
||||
## Common Issues
|
||||
|
||||
### Installation Errors
|
||||
|
||||
Installation errors can arise due to various reasons, such as incompatible versions, missing dependencies, or incorrect environment setups. First, check to make sure you are doing the following:
|
||||
|
||||
- You're using Python 3.8 or later as recommended.
|
||||
|
||||
- Ensure that you have the correct version of PyTorch (1.8 or later) installed.
|
||||
|
||||
- Consider using virtual environments to avoid conflicts.
|
||||
|
||||
- Follow the [official installation guide](../quickstart.md) step by step.
|
||||
|
||||
Additionally, here are some common installation issues users have encountered, along with their respective solutions:
|
||||
|
||||
- Import Errors or Dependency Issues - If you're getting errors during the import of YOLOv8, or you're having issues related to dependencies, consider the following troubleshooting steps:
|
||||
|
||||
- **Fresh Installation**: Sometimes, starting with a fresh installation can resolve unexpected issues. Especially with libraries like Ultralytics, where updates might introduce changes to the file tree structure or functionalities.
|
||||
|
||||
- **Update Regularly**: Ensure you're using the latest version of the library. Older versions might not be compatible with recent updates, leading to potential conflicts or issues.
|
||||
|
||||
- **Check Dependencies**: Verify that all required dependencies are correctly installed and are of the compatible versions.
|
||||
|
||||
- **Review Changes**: If you initially cloned or installed an older version, be aware that significant updates might affect the library's structure or functionalities. Always refer to the official documentation or changelogs to understand any major changes.
|
||||
|
||||
- Remember, keeping your libraries and dependencies up-to-date is crucial for a smooth and error-free experience.
|
||||
|
||||
- Running YOLOv8 on GPU - If you're having trouble running YOLOv8 on GPU, consider the following troubleshooting steps:
|
||||
|
||||
- **Verify CUDA Compatibility and Installation**: Ensure your GPU is CUDA compatible and that CUDA is correctly installed. Use the `nvidia-smi` command to check the status of your NVIDIA GPU and CUDA version.
|
||||
|
||||
- **Check PyTorch and CUDA Integration**: Ensure PyTorch can utilize CUDA by running `import torch; print(torch.cuda.is_available())` in a Python terminal. If it returns 'True', PyTorch is set up to use CUDA.
|
||||
|
||||
- **Environment Activation**: Ensure you're in the correct environment where all necessary packages are installed.
|
||||
|
||||
- **Update Your Packages**: Outdated packages might not be compatible with your GPU. Keep them updated.
|
||||
|
||||
- **Program Configuration**: Check if the program or code specifies GPU usage. In YOLOv8, this might be in the settings or configuration.
|
||||
|
||||
### Model Training Issues
|
||||
|
||||
This section will address common issues faced while training and their respective explanations and solutions.
|
||||
|
||||
#### Verification of Configuration Settings
|
||||
|
||||
**Issue**: You are unsure whether the configuration settings in the `.yaml` file are being applied correctly during model training.
|
||||
|
||||
**Solution**: The configuration settings in the `.yaml` file should be applied when using the `model.train()` function. To ensure that these settings are correctly applied, follow these steps:
|
||||
|
||||
- Confirm that the path to your `.yaml` configuration file is correct.
|
||||
- Make sure you pass the path to your `.yaml` file as the `data` argument when calling `model.train()`, as shown below:
|
||||
|
||||
```python
|
||||
model.train(data='/path/to/your/data.yaml', batch=4)
|
||||
```
|
||||
|
||||
#### Accelerating Training with Multiple GPUs
|
||||
|
||||
**Issue**: Training is slow on a single GPU, and you want to speed up the process using multiple GPUs.
|
||||
|
||||
**Solution**: Increasing the batch size can accelerate training, but it's essential to consider GPU memory capacity. To speed up training with multiple GPUs, follow these steps:
|
||||
|
||||
- Ensure that you have multiple GPUs available.
|
||||
|
||||
- Modify your .yaml configuration file to specify the number of GPUs to use, e.g., gpus: 4.
|
||||
|
||||
- Increase the batch size accordingly to fully utilize the multiple GPUs without exceeding memory limits.
|
||||
|
||||
- Modify your training command to utilize multiple GPUs:
|
||||
|
||||
```python
|
||||
# Adjust the batch size and other settings as needed to optimize training speed
|
||||
model.train(data='/path/to/your/data.yaml', batch=32, multi_scale=True)
|
||||
```
|
||||
|
||||
#### Continuous Monitoring Parameters
|
||||
|
||||
**Issue**: You want to know which parameters should be continuously monitored during training, apart from loss.
|
||||
|
||||
**Solution**: While loss is a crucial metric to monitor, it's also essential to track other metrics for model performance optimization. Some key metrics to monitor during training include:
|
||||
|
||||
- Precision
|
||||
- Recall
|
||||
- Mean Average Precision (mAP)
|
||||
|
||||
You can access these metrics from the training logs or by using tools like TensorBoard or wandb for visualization. Implementing early stopping based on these metrics can help you achieve better results.
|
||||
|
||||
#### Tools for Tracking Training Progress
|
||||
|
||||
**Issue**: You are looking for recommendations on tools to track training progress.
|
||||
|
||||
**Solution**: To track and visualize training progress, you can consider using the following tools:
|
||||
|
||||
- [TensorBoard](https://www.tensorflow.org/tensorboard): TensorBoard is a popular choice for visualizing training metrics, including loss, accuracy, and more. You can integrate it with your YOLOv8 training process.
|
||||
- [Comet](https://bit.ly/yolov8-readme-comet): Comet provides an extensive toolkit for experiment tracking and comparison. It allows you to track metrics, hyperparameters, and even model weights. Integration with YOLO models is also straightforward, providing you with a complete overview of your experiment cycle.
|
||||
- [Ultralytics HUB](https://hub.ultralytics.com): Ultralytics HUB offers a specialized environment for tracking YOLO models, giving you a one-stop platform to manage metrics, datasets, and even collaborate with your team. Given its tailored focus on YOLO, it offers more customized tracking options.
|
||||
|
||||
Each of these tools offers its own set of advantages, so you may want to consider the specific needs of your project when making a choice.
|
||||
|
||||
#### How to Check if Training is Happening on the GPU
|
||||
|
||||
**Issue**: The 'device' value in the training logs is 'null,' and you're unsure if training is happening on the GPU.
|
||||
|
||||
**Solution**: The 'device' value being 'null' typically means that the training process is set to automatically use an available GPU, which is the default behavior. To ensure training occurs on a specific GPU, you can manually set the 'device' value to the GPU index (e.g., '0' for the first GPU) in your .yaml configuration file:
|
||||
|
||||
```yaml
|
||||
device: 0
|
||||
```
|
||||
|
||||
This will explicitly assign the training process to the specified GPU. If you wish to train on the CPU, set 'device' to 'cpu'.
|
||||
|
||||
Keep an eye on the 'runs' folder for logs and metrics to monitor training progress effectively.
|
||||
|
||||
#### Key Considerations for Effective Model Training
|
||||
|
||||
Here are some things to keep in mind, if you are facing issues related to model training.
|
||||
|
||||
**Dataset Format and Labels**
|
||||
|
||||
- Importance: The foundation of any machine learning model lies in the quality and format of the data it is trained on.
|
||||
|
||||
- Recommendation: Ensure that your custom dataset and its associated labels adhere to the expected format. It's crucial to verify that annotations are accurate and of high quality. Incorrect or subpar annotations can derail the model's learning process, leading to unpredictable outcomes.
|
||||
|
||||
**Model Convergence**
|
||||
|
||||
- Importance: Achieving model convergence ensures that the model has sufficiently learned from the training data.
|
||||
|
||||
- Recommendation: When training a model 'from scratch', it's vital to ensure that the model reaches a satisfactory level of convergence. This might necessitate a longer training duration, with more epochs, compared to when you're fine-tuning an existing model.
|
||||
|
||||
**Learning Rate and Batch Size**
|
||||
|
||||
- Importance: These hyperparameters play a pivotal role in determining how the model updates its weights during training.
|
||||
|
||||
- Recommendation: Regularly evaluate if the chosen learning rate and batch size are optimal for your specific dataset. Parameters that are not in harmony with the dataset's characteristics can hinder the model's performance.
|
||||
|
||||
**Class Distribution**
|
||||
|
||||
- Importance: The distribution of classes in your dataset can influence the model's prediction tendencies.
|
||||
|
||||
- Recommendation: Regularly assess the distribution of classes within your dataset. If there's a class imbalance, there's a risk that the model will develop a bias towards the more prevalent class. This bias can be evident in the confusion matrix, where the model might predominantly predict the majority class.
|
||||
|
||||
**Cross-Check with Pretrained Weights**
|
||||
|
||||
- Importance: Leveraging pretrained weights can provide a solid starting point for model training, especially when data is limited.
|
||||
|
||||
- Recommendation: As a diagnostic step, consider training your model using the same data but initializing it with pretrained weights. If this approach yields a well-formed confusion matrix, it could suggest that the 'from scratch' model might require further training or adjustments.
|
||||
|
||||
### Issues Related to Model Predictions
|
||||
|
||||
This section will address common issues faced during model prediction.
|
||||
|
||||
#### Getting Bounding Box Predictions With Your YOLOv8 Custom Model
|
||||
|
||||
**Issue**: When running predictions with a custom YOLOv8 model, there are challenges with the format and visualization of the bounding box coordinates.
|
||||
|
||||
**Solution**:
|
||||
|
||||
- Coordinate Format: YOLOv8 provides bounding box coordinates in absolute pixel values. To convert these to relative coordinates (ranging from 0 to 1), you need to divide by the image dimensions. For example, let’s say your image size is 640x640. Then you would do the following:
|
||||
|
||||
```python
|
||||
# Convert absolute coordinates to relative coordinates
|
||||
x1 = x1 / 640 # Divide x-coordinates by image width
|
||||
x2 = x2 / 640
|
||||
y1 = y1 / 640 # Divide y-coordinates by image height
|
||||
y2 = y2 / 640
|
||||
```
|
||||
|
||||
- File Name: To obtain the file name of the image you're predicting on, access the image file path directly from the result object within your prediction loop.
|
||||
|
||||
#### Filtering Objects in YOLOv8 Predictions
|
||||
|
||||
**Issue**: Facing issues with how to filter and display only specific objects in the prediction results when running YOLOv8 using the Ultralytics library.
|
||||
|
||||
**Solution**: To detect specific classes use the classes argument to specify the classes you want to include in the output. For instance, to detect only cars (assuming 'cars' have class index 2):
|
||||
|
||||
```shell
|
||||
yolo task=detect mode=segment model=yolov8n-seg.pt source='path/to/car.mp4' show=True classes=2
|
||||
```
|
||||
|
||||
#### Understanding Precision Metrics in YOLOv8
|
||||
|
||||
**Issue**: Confusion regarding the difference between box precision, mask precision, and confusion matrix precision in YOLOv8.
|
||||
|
||||
**Solution**: Box precision measures the accuracy of predicted bounding boxes compared to the actual ground truth boxes using IoU (Intersection over Union) as the metric. Mask precision assesses the agreement between predicted segmentation masks and ground truth masks in pixel-wise object classification. Confusion matrix precision, on the other hand, focuses on overall classification accuracy across all classes and does not consider the geometric accuracy of predictions. It's important to note that a bounding box can be geometrically accurate (true positive) even if the class prediction is wrong, leading to differences between box precision and confusion matrix precision. These metrics evaluate distinct aspects of a model's performance, reflecting the need for different evaluation metrics in various tasks.
|
||||
|
||||
#### Extracting Object Dimensions in YOLOv8
|
||||
|
||||
**Issue**: Difficulty in retrieving the length and height of detected objects in YOLOv8, especially when multiple objects are detected in an image.
|
||||
|
||||
**Solution**: To retrieve the bounding box dimensions, first use the Ultralytics YOLOv8 model to predict objects in an image. Then, extract the width and height information of bounding boxes from the prediction results.
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a pre-trained YOLOv8 model
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Specify the source image
|
||||
source = 'https://ultralytics.com/images/bus.jpg'
|
||||
|
||||
# Make predictions
|
||||
results = model.predict(source, save=True, imgsz=320, conf=0.5)
|
||||
|
||||
# Extract bounding box dimensions
|
||||
boxes = results[0].boxes.xywh.cpu()
|
||||
for box in boxes:
|
||||
x, y, w, h = box
|
||||
print(f"Width of Box: {w}, Height of Box: {h}")
|
||||
```
|
||||
|
||||
### Deployment Challenges
|
||||
|
||||
#### GPU Deployment Issues
|
||||
|
||||
**Issue:** Deploying models in a multi-GPU environment can sometimes lead to unexpected behaviors like unexpected memory usage, inconsistent results across GPUs, etc.
|
||||
|
||||
**Solution:** Check for default GPU initialization. Some frameworks, like PyTorch, might initialize CUDA operations on a default GPU before transitioning to the designated GPUs. To bypass unexpected default initializations, specify the GPU directly during deployment and prediction. Then, use tools to monitor GPU utilization and memory usage to identify any anomalies in real-time. Also, ensure you're using the latest version of the framework or library.
|
||||
|
||||
#### Model Conversion/Exporting Issues
|
||||
|
||||
**Issue:** During the process of converting or exporting machine learning models to different formats or platforms, users might encounter errors or unexpected behaviors.
|
||||
|
||||
**Solution:**
|
||||
|
||||
- Compatibility Check: Ensure that you are using versions of libraries and frameworks that are compatible with each other. Mismatched versions can lead to unexpected errors during conversion.
|
||||
|
||||
- Environment Reset: If you're using an interactive environment like Jupyter or Colab, consider restarting your environment after making significant changes or installations. A fresh start can sometimes resolve underlying issues.
|
||||
|
||||
- Official Documentation: Always refer to the official documentation of the tool or library you are using for conversion. It often contains specific guidelines and best practices for model exporting.
|
||||
|
||||
- Community Support: Check the library or framework's official repository for similar issues reported by other users. The maintainers or community might have provided solutions or workarounds in discussion threads.
|
||||
|
||||
- Update Regularly: Ensure that you are using the latest version of the tool or library. Developers frequently release updates that fix known bugs or improve functionality.
|
||||
|
||||
- Test Incrementally: Before performing a full conversion, test the process with a smaller model or dataset to identify potential issues early on.
|
||||
|
||||
## Community and Support
|
||||
|
||||
Engaging with a community of like-minded individuals can significantly enhance your experience and success in working with YOLOv8. Below are some channels and resources you may find helpful.
|
||||
|
||||
### Forums and Channels for Getting Help
|
||||
|
||||
**GitHub Issues:** The YOLOv8 repository on GitHub has an [Issues tab](https://github.com/ultralytics/ultralytics/issues) where you can ask questions, report bugs, and suggest new features. The community and maintainers are active here, and it’s a great place to get help with specific problems.
|
||||
|
||||
**Ultralytics Discord Server:** Ultralytics has a [Discord server](https://ultralytics.com/discord/) where you can interact with other users and the developers.
|
||||
|
||||
### Official Documentation and Resources
|
||||
|
||||
**Ultralytics YOLOv8 Docs**: The [official documentation](../index.md) provides a comprehensive overview of YOLOv8, along with guides on installation, usage, and troubleshooting.
|
||||
|
||||
These resources should provide a solid foundation for troubleshooting and improving your YOLOv8 projects, as well as connecting with others in the YOLOv8 community.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Troubleshooting is an integral part of any development process, and being equipped with the right knowledge can significantly reduce the time and effort spent in resolving issues. This guide aimed to address the most common challenges faced by users of the YOLOv8 model within the Ultralytics ecosystem. By understanding and addressing these common issues, you can ensure smoother project progress and achieve better results with your computer vision tasks.
|
||||
|
||||
Remember, the Ultralytics community is a valuable resource. Engaging with fellow developers and experts can provide additional insights and solutions that might not be covered in standard documentation. Always keep learning, experimenting, and sharing your experiences to contribute to the collective knowledge of the community.
|
||||
|
||||
Happy troubleshooting!
|
||||
176
docs/en/guides/yolo-performance-metrics.md
Normal file
176
docs/en/guides/yolo-performance-metrics.md
Normal file
@ -0,0 +1,176 @@
|
||||
---
|
||||
comments: true
|
||||
description: A comprehensive guide on various performance metrics related to YOLOv8, their significance, and how to interpret them.
|
||||
keywords: YOLOv8, Performance metrics, Object detection, Intersection over Union (IoU), Average Precision (AP), Mean Average Precision (mAP), Precision, Recall, Validation mode, Ultralytics
|
||||
---
|
||||
|
||||
# Performance Metrics Deep Dive
|
||||
|
||||
## Introduction
|
||||
|
||||
Performance metrics are key tools to evaluate the accuracy and efficiency of object detection models. They shed light on how effectively a model can identify and localize objects within images. Additionally, they help in understanding the model's handling of false positives and false negatives. These insights are crucial for evaluating and enhancing the model's performance. In this guide, we will explore various performance metrics associated with YOLOv8, their significance, and how to interpret them.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/q7LwPoM7tSQ"
|
||||
title="YouTube video player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Watch:</strong> Ultralytics YOLOv8 Performance Metrics | MAP, F1 Score, Precision, IoU & Accuracy
|
||||
</p>
|
||||
|
||||
## Object Detection Metrics
|
||||
|
||||
Let’s start by discussing some metrics that are not only important to YOLOv8 but are broadly applicable across different object detection models.
|
||||
|
||||
- **Intersection over Union (IoU):** IoU is a measure that quantifies the overlap between a predicted bounding box and a ground truth bounding box. It plays a fundamental role in evaluating the accuracy of object localization.
|
||||
|
||||
- **Average Precision (AP):** AP computes the area under the precision-recall curve, providing a single value that encapsulates the model's precision and recall performance.
|
||||
|
||||
- **Mean Average Precision (mAP):** mAP extends the concept of AP by calculating the average AP values across multiple object classes. This is useful in multi-class object detection scenarios to provide a comprehensive evaluation of the model's performance.
|
||||
|
||||
- **Precision and Recall:** Precision quantifies the proportion of true positives among all positive predictions, assessing the model's capability to avoid false positives. On the other hand, Recall calculates the proportion of true positives among all actual positives, measuring the model's ability to detect all instances of a class.
|
||||
|
||||
- **F1 Score:** The F1 Score is the harmonic mean of precision and recall, providing a balanced assessment of a model's performance while considering both false positives and false negatives.
|
||||
|
||||
## How to Calculate Metrics for YOLOv8 Model
|
||||
|
||||
Now, we can explore [YOLOv8's Validation mode](../modes/val.md) that can be used to compute the above discussed evaluation metrics.
|
||||
|
||||
Using the validation mode is simple. Once you have a trained model, you can invoke the model.val() function. This function will then process the validation dataset and return a variety of performance metrics. But what do these metrics mean? And how should you interpret them?
|
||||
|
||||
### Interpreting the Output
|
||||
|
||||
Let's break down the output of the model.val() function and understand each segment of the output.
|
||||
|
||||
#### Class-wise Metrics
|
||||
|
||||
One of the sections of the output is the class-wise breakdown of performance metrics. This granular information is useful when you are trying to understand how well the model is doing for each specific class, especially in datasets with a diverse range of object categories. For each class in the dataset the following is provided:
|
||||
|
||||
- **Class**: This denotes the name of the object class, such as "person", "car", or "dog".
|
||||
|
||||
- **Images**: This metric tells you the number of images in the validation set that contain the object class.
|
||||
|
||||
- **Instances**: This provides the count of how many times the class appears across all images in the validation set.
|
||||
|
||||
- **Box(P, R, mAP50, mAP50-95)**: This metric provides insights into the model's performance in detecting objects:
|
||||
|
||||
- **P (Precision)**: The accuracy of the detected objects, indicating how many detections were correct.
|
||||
|
||||
- **R (Recall)**: The ability of the model to identify all instances of objects in the images.
|
||||
|
||||
- **mAP50**: Mean average precision calculated at an intersection over union (IoU) threshold of 0.50. It's a measure of the model's accuracy considering only the "easy" detections.
|
||||
|
||||
- **mAP50-95**: The average of the mean average precision calculated at varying IoU thresholds, ranging from 0.50 to 0.95. It gives a comprehensive view of the model's performance across different levels of detection difficulty.
|
||||
|
||||
#### Speed Metrics
|
||||
|
||||
The speed of inference can be as critical as accuracy, especially in real-time object detection scenarios. This section breaks down the time taken for various stages of the validation process, from preprocessing to post-processing.
|
||||
|
||||
#### COCO Metrics Evaluation
|
||||
|
||||
For users validating on the COCO dataset, additional metrics are calculated using the COCO evaluation script. These metrics give insights into precision and recall at different IoU thresholds and for objects of different sizes.
|
||||
|
||||
#### Visual Outputs
|
||||
|
||||
The model.val() function, apart from producing numeric metrics, also yields visual outputs that can provide a more intuitive understanding of the model's performance. Here's a breakdown of the visual outputs you can expect:
|
||||
|
||||
- **F1 Score Curve (`F1_curve.png`)**: This curve represents the F1 score across various thresholds. Interpreting this curve can offer insights into the model's balance between false positives and false negatives over different thresholds.
|
||||
|
||||
- **Precision-Recall Curve (`PR_curve.png`)**: An integral visualization for any classification problem, this curve showcases the trade-offs between precision and recall at varied thresholds. It becomes especially significant when dealing with imbalanced classes.
|
||||
|
||||
- **Precision Curve (`P_curve.png`)**: A graphical representation of precision values at different thresholds. This curve helps in understanding how precision varies as the threshold changes.
|
||||
|
||||
- **Recall Curve (`R_curve.png`)**: Correspondingly, this graph illustrates how the recall values change across different thresholds.
|
||||
|
||||
- **Confusion Matrix (`confusion_matrix.png`)**: The confusion matrix provides a detailed view of the outcomes, showcasing the counts of true positives, true negatives, false positives, and false negatives for each class.
|
||||
|
||||
- **Normalized Confusion Matrix (`confusion_matrix_normalized.png`)**: This visualization is a normalized version of the confusion matrix. It represents the data in proportions rather than raw counts. This format makes it simpler to compare the performance across classes.
|
||||
|
||||
- **Validation Batch Labels (`val_batchX_labels.jpg`)**: These images depict the ground truth labels for distinct batches from the validation dataset. They provide a clear picture of what the objects are and their respective locations as per the dataset.
|
||||
|
||||
- **Validation Batch Predictions (`val_batchX_pred.jpg`)**: Contrasting the label images, these visuals display the predictions made by the YOLOv8 model for the respective batches. By comparing these to the label images, you can easily assess how well the model detects and classifies objects visually.
|
||||
|
||||
#### Results Storage
|
||||
|
||||
For future reference, the results are saved to a directory, typically named runs/detect/val.
|
||||
|
||||
## Choosing the Right Metrics
|
||||
|
||||
Choosing the right metrics to evaluate often depends on the specific application.
|
||||
|
||||
- **mAP:** Suitable for a broad assessment of model performance.
|
||||
|
||||
- **IoU:** Essential when precise object location is crucial.
|
||||
|
||||
- **Precision:** Important when minimizing false detections is a priority.
|
||||
|
||||
- **Recall:** Vital when it's important to detect every instance of an object.
|
||||
|
||||
- **F1 Score:** Useful when a balance between precision and recall is needed.
|
||||
|
||||
For real-time applications, speed metrics like FPS (Frames Per Second) and latency are crucial to ensure timely results.
|
||||
|
||||
## Interpretation of Results
|
||||
|
||||
It’s important to understand the metrics. Here's what some of the commonly observed lower scores might suggest:
|
||||
|
||||
- **Low mAP:** Indicates the model may need general refinements.
|
||||
|
||||
- **Low IoU:** The model might be struggling to pinpoint objects accurately. Different bounding box methods could help.
|
||||
|
||||
- **Low Precision:** The model may be detecting too many non-existent objects. Adjusting confidence thresholds might reduce this.
|
||||
|
||||
- **Low Recall:** The model could be missing real objects. Improving feature extraction or using more data might help.
|
||||
|
||||
- **Imbalanced F1 Score:** There's a disparity between precision and recall.
|
||||
|
||||
- **Class-specific AP:** Low scores here can highlight classes the model struggles with.
|
||||
|
||||
## Case Studies
|
||||
|
||||
Real-world examples can help clarify how these metrics work in practice.
|
||||
|
||||
### Case 1
|
||||
|
||||
- **Situation:** mAP and F1 Score are suboptimal, but while Recall is good, Precision isn't.
|
||||
|
||||
- **Interpretation & Action:** There might be too many incorrect detections. Tightening confidence thresholds could reduce these, though it might also slightly decrease recall.
|
||||
|
||||
### Case 2
|
||||
|
||||
- **Situation:** mAP and Recall are acceptable, but IoU is lacking.
|
||||
|
||||
- **Interpretation & Action:** The model detects objects well but might not be localizing them precisely. Refining bounding box predictions might help.
|
||||
|
||||
### Case 3
|
||||
|
||||
- **Situation:** Some classes have a much lower AP than others, even with a decent overall mAP.
|
||||
|
||||
- **Interpretation & Action:** These classes might be more challenging for the model. Using more data for these classes or adjusting class weights during training could be beneficial.
|
||||
|
||||
## Connect and Collaborate
|
||||
|
||||
Tapping into a community of enthusiasts and experts can amplify your journey with YOLOv8. Here are some avenues that can facilitate learning, troubleshooting, and networking.
|
||||
|
||||
### Engage with the Broader Community
|
||||
|
||||
- **GitHub Issues:** The YOLOv8 repository on GitHub has an [Issues tab](https://github.com/ultralytics/ultralytics/issues) where you can ask questions, report bugs, and suggest new features. The community and maintainers are active here, and it’s a great place to get help with specific problems.
|
||||
|
||||
- **Ultralytics Discord Server:** Ultralytics has a [Discord server](https://ultralytics.com/discord/) where you can interact with other users and the developers.
|
||||
|
||||
### Official Documentation and Resources:
|
||||
|
||||
- **Ultralytics YOLOv8 Docs:** The [official documentation](../index.md) provides a comprehensive overview of YOLOv8, along with guides on installation, usage, and troubleshooting.
|
||||
|
||||
Using these resources will not only guide you through any challenges but also keep you updated with the latest trends and best practices in the YOLOv8 community.
|
||||
|
||||
## Conclusion
|
||||
|
||||
In this guide, we've taken a close look at the essential performance metrics for YOLOv8. These metrics are key to understanding how well a model is performing and are vital for anyone aiming to fine-tune their models. They offer the necessary insights for improvements and to make sure the model works effectively in real-life situations.
|
||||
|
||||
Remember, the YOLOv8 and Ultralytics community is an invaluable asset. Engaging with fellow developers and experts can open doors to insights and solutions not found in standard documentation. As you journey through object detection, keep the spirit of learning alive, experiment with new strategies, and share your findings. By doing so, you contribute to the community's collective wisdom and ensure its growth.
|
||||
|
||||
Happy object detecting!
|
||||
108
docs/en/guides/yolo-thread-safe-inference.md
Normal file
108
docs/en/guides/yolo-thread-safe-inference.md
Normal file
@ -0,0 +1,108 @@
|
||||
---
|
||||
comments: true
|
||||
description: This guide provides best practices for performing thread-safe inference with YOLO models, ensuring reliable and concurrent predictions in multi-threaded applications.
|
||||
keywords: thread-safe, YOLO inference, multi-threading, concurrent predictions, YOLO models, Ultralytics, Python threading, safe YOLO usage, AI concurrency
|
||||
---
|
||||
|
||||
# Thread-Safe Inference with YOLO Models
|
||||
|
||||
Running YOLO models in a multi-threaded environment requires careful consideration to ensure thread safety. Python's `threading` module allows you to run several threads concurrently, but when it comes to using YOLO models across these threads, there are important safety issues to be aware of. This page will guide you through creating thread-safe YOLO model inference.
|
||||
|
||||
## Understanding Python Threading
|
||||
|
||||
Python threads are a form of parallelism that allow your program to run multiple operations at once. However, Python's Global Interpreter Lock (GIL) means that only one thread can execute Python bytecode at a time.
|
||||
|
||||
<p align="center">
|
||||
<img width="800" src="https://user-images.githubusercontent.com/26833433/281418476-7f478570-fd77-4a40-bf3d-74b4db4d668c.png" alt="Single vs Multi-Thread Examples">
|
||||
</p>
|
||||
|
||||
While this sounds like a limitation, threads can still provide concurrency, especially for I/O-bound operations or when using operations that release the GIL, like those performed by YOLO's underlying C libraries.
|
||||
|
||||
## The Danger of Shared Model Instances
|
||||
|
||||
Instantiating a YOLO model outside your threads and sharing this instance across multiple threads can lead to race conditions, where the internal state of the model is inconsistently modified due to concurrent accesses. This is particularly problematic when the model or its components hold state that is not designed to be thread-safe.
|
||||
|
||||
### Non-Thread-Safe Example: Single Model Instance
|
||||
|
||||
When using threads in Python, it's important to recognize patterns that can lead to concurrency issues. Here is what you should avoid: sharing a single YOLO model instance across multiple threads.
|
||||
|
||||
```python
|
||||
# Unsafe: Sharing a single model instance across threads
|
||||
from ultralytics import YOLO
|
||||
from threading import Thread
|
||||
|
||||
# Instantiate the model outside the thread
|
||||
shared_model = YOLO("yolov8n.pt")
|
||||
|
||||
|
||||
def predict(image_path):
|
||||
results = shared_model.predict(image_path)
|
||||
# Process results
|
||||
|
||||
|
||||
# Starting threads that share the same model instance
|
||||
Thread(target=predict, args=("image1.jpg",)).start()
|
||||
Thread(target=predict, args=("image2.jpg",)).start()
|
||||
```
|
||||
|
||||
In the example above, the `shared_model` is used by multiple threads, which can lead to unpredictable results because `predict` could be executed simultaneously by multiple threads.
|
||||
|
||||
### Non-Thread-Safe Example: Multiple Model Instances
|
||||
|
||||
Similarly, here is an unsafe pattern with multiple YOLO model instances:
|
||||
|
||||
```python
|
||||
# Unsafe: Sharing multiple model instances across threads can still lead to issues
|
||||
from ultralytics import YOLO
|
||||
from threading import Thread
|
||||
|
||||
# Instantiate multiple models outside the thread
|
||||
shared_model_1 = YOLO("yolov8n_1.pt")
|
||||
shared_model_2 = YOLO("yolov8n_2.pt")
|
||||
|
||||
|
||||
def predict(model, image_path):
|
||||
results = model.predict(image_path)
|
||||
# Process results
|
||||
|
||||
|
||||
# Starting threads with individual model instances
|
||||
Thread(target=predict, args=(shared_model_1, "image1.jpg")).start()
|
||||
Thread(target=predict, args=(shared_model_2, "image2.jpg")).start()
|
||||
```
|
||||
|
||||
Even though there are two separate model instances, the risk of concurrency issues still exists. If the internal implementation of `YOLO` is not thread-safe, using separate instances might not prevent race conditions, especially if these instances share any underlying resources or states that are not thread-local.
|
||||
|
||||
## Thread-Safe Inference
|
||||
|
||||
To perform thread-safe inference, you should instantiate a separate YOLO model within each thread. This ensures that each thread has its own isolated model instance, eliminating the risk of race conditions.
|
||||
|
||||
### Thread-Safe Example
|
||||
|
||||
Here's how to instantiate a YOLO model inside each thread for safe parallel inference:
|
||||
|
||||
```python
|
||||
# Safe: Instantiating a single model inside each thread
|
||||
from ultralytics import YOLO
|
||||
from threading import Thread
|
||||
|
||||
|
||||
def thread_safe_predict(image_path):
|
||||
# Instantiate a new model inside the thread
|
||||
local_model = YOLO("yolov8n.pt")
|
||||
results = local_model.predict(image_path)
|
||||
# Process results
|
||||
|
||||
|
||||
# Starting threads that each have their own model instance
|
||||
Thread(target=thread_safe_predict, args=("image1.jpg",)).start()
|
||||
Thread(target=thread_safe_predict, args=("image2.jpg",)).start()
|
||||
```
|
||||
|
||||
In this example, each thread creates its own `YOLO` instance. This prevents any thread from interfering with the model state of another, thus ensuring that each thread performs inference safely and without unexpected interactions with the other threads.
|
||||
|
||||
## Conclusion
|
||||
|
||||
When using YOLO models with Python's `threading`, always instantiate your models within the thread that will use them to ensure thread safety. This practice avoids race conditions and makes sure that your inference tasks run reliably.
|
||||
|
||||
For more advanced scenarios and to further optimize your multi-threaded inference performance, consider using process-based parallelism with `multiprocessing` or leveraging a task queue with dedicated worker processes.
|
||||
Reference in New Issue
Block a user